
商汤加入AI大战!首次实时演示大模型体系 代码编写效率提升62%
商汤加入AI大战!首次实时演示大模型体系代码编写效率提升62%

葛佳明
04-1017:35
商汤科技发布“日日新”大模型体系,含自然语言生成、照片生成服务、感知模型预标注、模型研发,并宣布推出1800亿参数中文语言大模型应用平台“商量”,可实现多轮对话、逻辑推理、语言纠错、内容创作、情感分析等。
GPT的诞生引燃了沉寂许久的人工智能新浪潮,“颠覆性变革”正在发生,是否拥有超大模型与高算力开始渐渐成为衡量一家人工智能企业能力的主要标准。
4月10日,人工智能软件公司商汤科技董事长兼CEO徐立,在技术交流日上宣布,将推出大模型体系“商汤日日新大模型”,包括自然语言生成、文生图、感知模型标注以及模型研发功能。
“日日新”取自《礼记·大学》:“汤之盘铭曰:苟日新,日日新,又日新。”

商汤还宣布推出商汤自研中文语言大模型应用平台“商量 SenseChat”。
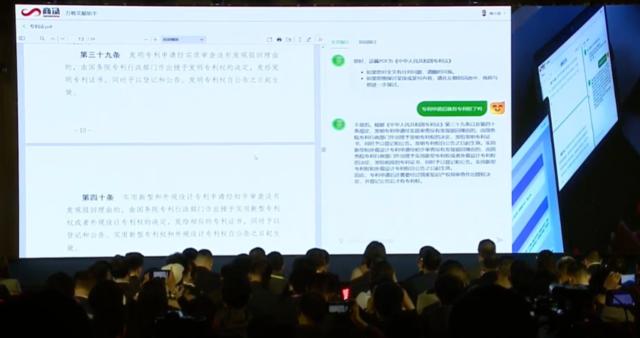
徐立介绍称,商量是一个1800亿参数的中文大语言模型,可实现多轮对话、逻辑推理、语言纠错、内容创作、情感分析等,并在现场演示了其作广告语、续写儿童故事、编程等功能,下图为商汤大模型实时演示:
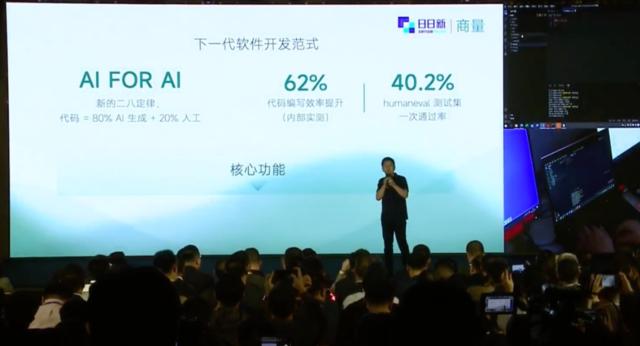
徐立表示,内部实测代码编写效率提升62%,HumanEval测试集一次通过率40.2%。下一代软件开发范式是AIforAI,代码=80%AI生成+20%人工。
此外,商汤还介绍了超10亿参数自研文生图生成模型“秒画”,支持二次元等多种生成风格。单卡A100支持,2秒生成1张512K分辨率的图片。用户可基于单卡A100自训练。基于平台发布的模型,可设置toB服务API(应用程序编程接口),结合商汤大算力对外提供服务。

同时,徐立指出,人工智能的能力由大模型参数量乘以训练数据量决定。商汤人工智能计算中心,算力可支持20个千亿参数超大模型同时训练。
徐立此前曾表示,商汤将通用人工智能(AGI)作为核心发展战略,以期在未来几年内实现重大突破:
人工智能是一个前景广阔的赛道,商汤将一如既往地坚定投入在迈向通用人工智能的前沿研发与商业化进程中。
商汤SenseCore庞大的算力输出能力
徐立在交流日介绍称,人工智能的能力由大模型参数量乘以训练数据量决定。商汤人工智能计算中心算力达5000+p,当前可支持20个千亿参数超大模型同时训练。
根据商汤3月28日公布的财报显示,服务于大模型训练的商汤SenseCoreAI大装置,目前已支持8家客户进行大模型训练,总共提供了7000多张GPU卡。

SenseCore已支持了超过10个大模型训练项目,包括语言大模型、文生图模型、视觉大模型、多模态模型等自研模型和客户自定义模型。
从算力能力上看,年内,商汤SenseCoreAI大装置在持续进行扩建,共计完成了2.7万块GPU的部署并实现了5.0exaFLOPS的算力输出能力。
目前该装置可最多支持20个千亿参数量大模型(以千卡并行)同时训练,最高可支持万亿参数超大模型的训练。
商汤科技联合创始人兼首席科学家王晓刚教授在此前接受媒体采访时表示,商汤多年人才和技术积累使其具有与OpenAI相比非常类似的优势:
商汤有非常多的研发人员能深入到一线,用模型去解决实际问题,有很好的积累。‘好的原材料’就是要深入到各个行业里积累非常多的know-how。美国公司OpenAI能够把ChatGPT做出来,背后也有多年积累,从小模型到大模型的研发,中间积累了非常多的know-how。”
王晓刚教授指出,深度学习一下子颠覆了所有传统,现在的关键是“拥抱全新研究范式”和“转变观念”:
颠覆会不断出现,且以非常快的速度出现。现在重新有了一个机会。这对于整个行业发展非常好。
十年前,商汤还没有诞生,我们创始团队在当时做的决定就是-Allindeeplearning。我们之前在传统视觉技术里也有较长积累,但是,当新技术来了,我们就果断地去拥抱新技术。今天也一样。”
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。