
晶圆级AI芯片WSE-3推理性能公布:在80亿参数模型上每秒生成1800个Token
今年3月,新创AI芯片公司CerebrasSystems推出了其第三代的晶圆级AI芯片WSE-3,性能达到了上一代WSE-2的两倍,可用于训练业内一些最大的人工智能模型。在近日的HotChips2024大会上,CerebrasSystems详细介绍了这款芯片在AI推理方面的性能。
根据官方资料显示,WSE-3依然是采用了一整张12英寸晶圆来制作,基于台积电5nm制程,芯片面积为46225平方毫米,拥有的晶体管数量达到了4万亿个,拥有90万个AI核心,44GB片上SRAM,整体的内存带宽为21PB/s,结构带宽高达214PB/s。使得WSE-3具有125FP16PetaFLOPS的峰值性能,相比上一代的WSE-2提升了1倍。

作为对比,WSE-2芯片面积同样是46225平方毫米,基于台积电7nm制程,晶体管数量为2.6万亿个,AI内核数量为85万个,片上内存SRAM为40GB,内存带宽为20PB/s,结构带宽高达220PB/s。
如果将其与英伟达的H100相比,WSE-3面积将是H100的57倍,内核数量是H100的52倍,片上内存是H100的880倍,内存带宽是H100的7000倍,结构带宽是H100的3715倍。( H200的HBM3e仅拥有4.8TBps的带宽。)

在此次的HotChips2024大会上,Cerebras公布了更多关于WSE-3在运行AI大模型上的性能表现。
Cerebras表示,它在Llama3.1-8B上的推理速度比微软Azure等公司使用NVIDIAH100快了20倍。需要指出的是,在许多现代生成式AI工作负载中,推理性能通常更得益于内存带宽的大小,而不单单是计算能力。也就是说,拥有更大的内存带宽,模型的推理速度就越快。
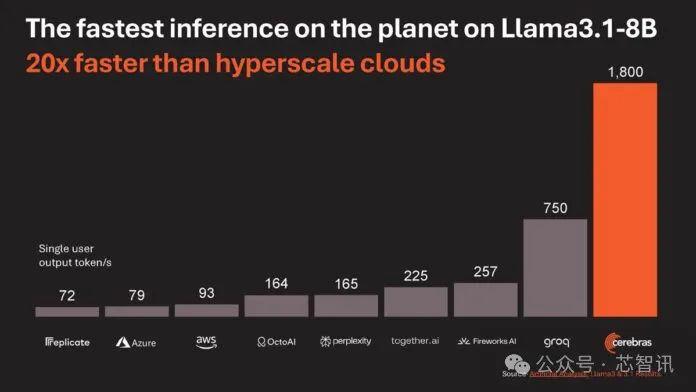
CerebraSystems首席执行官AndrewFeldman称,WSE-3通过使用44GB片上SRAM,使得其能够以16位精度运行Llama3.18B时,每秒能够生成超过1,800个Token,而性能最好的基于英伟达H100的实例每秒只能生成超过242个Token。
与此同时,Cerebras还推出了基于WSE-3的CS-3超级计算机,可用于训练参数高达24万亿的人工智能模型,这比相比基于WSE-2和其他现代人工智能处理器的超级计算机有了重大飞跃。该超级计算机可以支持1.5TB、12TB或1.2PB的外部内存,这使它能够在单个逻辑空间中存储大量模型,而无需分区或重构,从而简化了训练过程,提高了开发人员的效率。

最新的Cerebras软件框架可以为PyTorch2.0和最新的AI模型和技术(如多模态模型、视觉转换器、专家混合和扩散)提供原生支持。Cerebras仍然是唯一为动态和非结构化稀疏性提供本机硬件加速的平台,相比英伟达的DGX-100计算机系统,将训练速度提高了8倍。
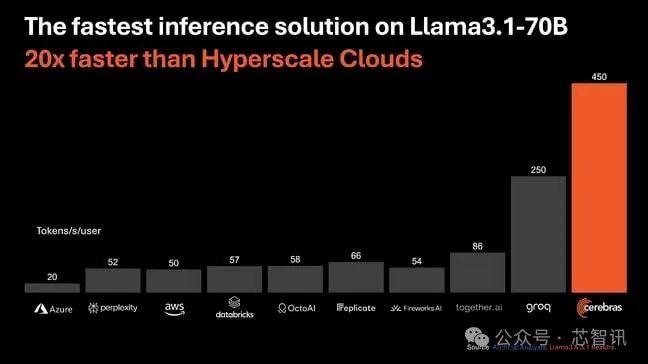
在运行分布在四个CS-3加速器上的700亿参数版本的Llama3.1大模型时,也能够实现每秒450个Token。相比之下,H100可以管理的最佳状态是每秒128个Token。
Feldman认为,这种性能水平,就像宽带的兴起一样,将为AI的采用开辟新的机会。“今天,我认为我们正处于GenAI的拨号时代,”他说,并指出了生成式AI的早期应用,其中提示的响应会有明显的延迟。
他认为,如果能够足够快地处理请求,就可以基于多个模型构建代理应用程序,而不会因为延迟变得难以为继。Feldman认为这种性能有益的另一个应用是允许LLM在多个步骤中迭代他们的答案,而不仅仅是吐出他们的第一个响应。如果您可以足够快地处理Token,则可以在幕后做更多的处理。
虽然WSE-3能够以 16位精度运行Llama3.18B时,每秒能够生成超过1,800个Token,但是如果不是因为系统受计算限制,WSE-3的速度应该能够更快。
该产品代表了Cerebras的一些转变,因为此前,Cerebras主要专注于AI训练。虽然现在也开始应用于AI推理,但是硬件本身实际上并没有改变。Feldman表示,他们正在使用相同的WSE-3芯片和CS-3系统进行推理和训练。
“我们所做的是扩展了编译器的功能,可以同时在芯片上放置多个层,”Feldman解释说。
SRAM速度很快,但使HBM容量更大
虽然SRAM在性能方面比HBM具有明显的优势,但它的不足之处在于容量。对于大型语言模型(LLM)来说,44GB的容量并不多,因为必须考虑到键值缓存在WSE-3所针对的高批处理大小下占用了相当多的空间。
Meta的Llama38B模型是WSE-3的理想化场景,因为大小为16GB(FP16),整个模型可以安装在芯片的SRAM中,为键值缓存留下大约28GB的空间。
Feldman声称,除了极高的吞吐量外,WSE-3还可以扩展到更高的批量大小。尽管它究竟可以扩展到多大程度并保持每个用户Token的生成率,这家初创公司不愿透露。“我们目前的批次大小经常变化。我们预计第四季度的批量规模将达到两位数,“Cerebras说道。
当被追问更多细节时,Feldman补充说:“我们目前的批量大小还不成熟,因此我们宁愿不提供它。系统架构旨在以高批量运行,我们预计在未来几周内实现这一目标。”
与现代GPU非常相似,Cerebras通过跨多个CS-3系统并行化模型来应对这一挑战。具体来说,Cerebras正在使用管道并行性将模型的层分布到多个系统。
对于需要140GB内存的Llama370B,该模型的80层分布在四个通过以太网互连的CS-3系统中。这确实会带来性能损失,因为数据必须通过这些链接。

然而,根据Feldman的说法,节点到节点的延迟并不像您想象的那么大。“这里的延迟是真实的,但很小,并且它与通过芯片上所有其他层的Token分摊,”他解释说。“最后,Token上的晶圆到晶圆延迟约占总数的5%。”
对于更大的模型,例如最近宣布的4050亿参数变体的Llama3,Cerebras估计它将能够使用12个CS-3系统实现每秒约350个Token。
利用更高速的片上SRAM来替代HBM并不是一个新鲜事,Cerebra的竞争对手Groq也是这么做的。
Groq的语言处理单元(LPU)实际上使用了片上SRAM。不同之处在于,由于单个GroqLPUSRAM容量较低,因此需要通过光纤连接更多的加速器来支持更大的模型。
Cerebras需要四个CS-3系统才能以每秒450个令牌的速度运行Llama370B,Groq此前曾表示,它需要576个LPU才能实现每秒300个Token。而Cerebras引用的人工智能分析Groq基准测试略低,为每秒250个Token。
Feldman还指出,Cerebras能够在不求助于量化的情况下做到这一点。认为Groq正在使用8bit量化来达到他们的性能目标,这减少了模型大小、计算开销和内存压力,但代价是准确性有所损失。
不过,仅比较性能,而忽略整体的成本是不公平的对比。毕竟单个晶圆级的WSE-3芯片的成本也远远高于GroqLPU的成本。
编辑:芯智讯-浪客剑