
AI掀起“算力革命”:英伟达之后,AMD也要放大招!
AI掀起“算力革命”:英伟达之后,AMD也要放大招!
华泰证券何翩翩
与英伟达GH200超级芯片类似,AMD在2023下半年即将推出的MI300也将采用CPU+GPU架构,同样发力于AI训练市场。 英伟达的高算力GPU一直是AI训练的首选,但随着谷歌TPU、AMDMI300及云厂商自研芯片等的强势涌入,AI训练的市场格局变化苗头渐生。
千呼万唤始出来,DGXGH200超级计算系统助力新一代大AI模型,与英伟达GH200超级芯片类似,AMD在2023下半年即将推出的MI300也将采用CPU+GPU架构,同样发力于AI训练市场。
英伟达在2023COMPUTEX大会上更新了多款AI算力产品。当中焦点落在DGXGH200超级计算系统上。该系统是通过NVLink互连技术及NVLinkSwitchSystem,串联32台由8块GH200超级芯片(总计256块)合并而成的单一超级计算系统,存储器容量高达144TB,大规模的共享内存能解决AI大模型训练的关键瓶颈,将为生成式AI语言应用、推荐系统和数据分析工作负载的大模型增添动力。英伟达宣布GoogleCloud、Meta与微软将是其首批用户。
核心观点
先进的加速计算+网络技术,为吞吐量和可扩展性迎来新突破
DGXGH200集成了英伟达最先进的加速计算和网络技术,为提供最大的吞吐量和可扩展性而设计。NVIDIANVLink-C2C将CPU与GPU相连组成GH200超级芯片,它们再通过NVLinkSwitchSystem组成高带宽的多GPU系统,每个GraceHopper超级芯片还配有一个NVIDIAConnectX-7网络适配器和一个NVIDIABlueField-3NIC。从具体参数上看DGXGH200性能优异,DGXGH200可提供高达1exaFLOPS=1000petaFLOPS的算力。在2023年底,结合Quantum-2InfiniBand技术与4台DGXGH200的AI超级计算机NVIDIAHelios(含1024=4*256个GH200超级芯片)将会推出,或标志英伟达在AI和数据分析工作负载加速计算的又一突破。
英伟达GH200vsAMDMI300,互联和生态圈或是AMD破局的主要障碍
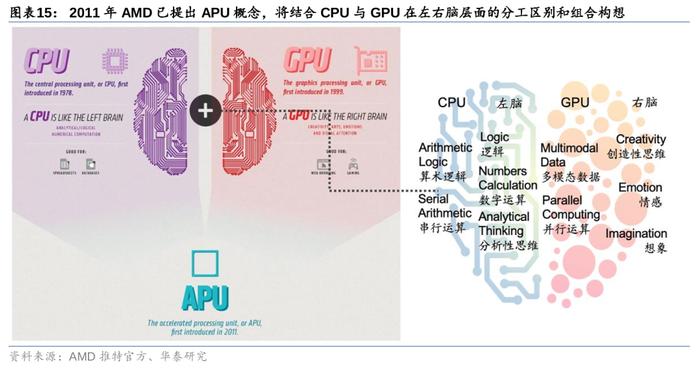
英伟达的GraceHopper与AMD的MI300同为CPU+GPU架构。我们认为,该架构已成为AI芯片的趋势,鉴于AI的最终目标是模仿人类大脑的操作,AI芯片也应仿生人脑结构,并顺应多模态模型的发展。CPU更像左脑,负责对信息的逻辑处理,如串行运算、数字和算术、分析思维、理解、整理等,而GPU更像右脑,负责并行计算、创造性思维和想象等。在面对不同模态的推理时,CPU与GPU的分工也各有不同。例如,在处理语音、语言和文本时,计算有序,因此或更适合使用CPU;但在处理图像、视频等推理时,需要大规模并行运算,或更适宜GPU。此前,英特尔也曾准备发布同类产品FalconShores。
AI训练多方入局苗头初生,AI推理百花齐放难决胜负
英伟达的高算力GPU一直是AI训练的首选,但随着谷歌TPU、AMDMI300及云厂商自研芯片等的强势涌入,AI训练的市场格局变化苗头渐生。谷歌的TPU是少数能与英伟GPU匹敌的芯片,但面临着通用性的局限;AMDMI300在制程、架构及算力等多方面虽向英伟达GPU看齐,但仍存在软件生态和互联的突围障碍。在TCO、研发可控性及集成生态圈等因素下,微软、谷歌及亚马逊等头部云厂商推进自研芯片乃大势所趋。在算力要求比训练低的推理端,各类芯片百花齐放,主要根据不同AI工作负载来选择,或不会演变出像训练端一家独大的竞争局面。总体而言,AI训练和推理的TAM虽在不断变大,但英伟达在当中的增速能否跟上是支撑公司发展的关键。
从Spectrum-X网络平台到超算系统,英伟达为AI计算全面加速
除了GH200芯片及DGXGH200超算系统的重磅发布,CEO黄仁勋在本次2023COMPUTEX还宣布了多款新品全面加速AI计算:专门用于提高以太网AI云性能和效率的网络平台Spectrum-X及用于创建加速服务器的模块化参考架构NVIDIAMGX,为AI及HPC的客户提供多元化选择。
正文
DGXGH200超级计算系统为新一代大AI模型而设
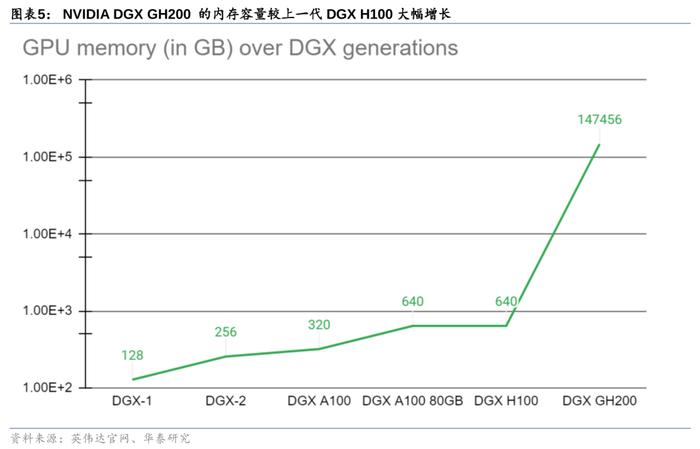
GraceHopper超级芯片宣布全面投产。严格意义上来说,GH200并不是一款“全新”的芯片,因为早在2022年的GTC大会,英伟达就已经公布了由首款数据中心CPUGrace+新一代高性能计算GPUHopper打造而成的GraceHopperSuperchip并透露其使用了NVLink-C2C技术,具有高达900GB/s的一致性接口速率;在2023年的GTC大会上,英伟达CEO黄仁勋先生也曾手持这款超级芯片进行首次实物展示。距离GraceHopper首次发布14个月后的COMPUTEX2023上,GH200GraceHopper超级芯片被正式宣布已经全面投产,将为大规模HPC和AI应用带来突破性的加速计算。
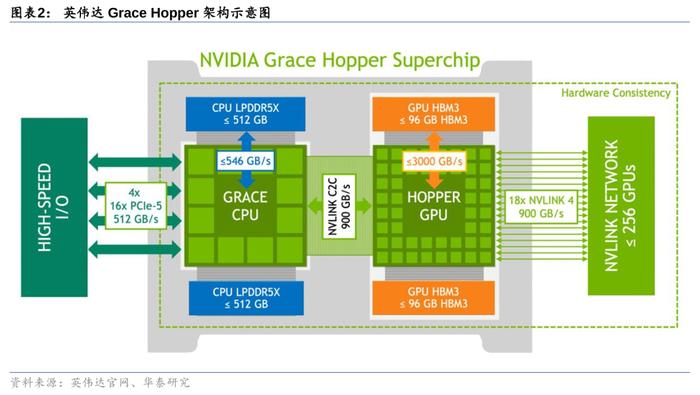
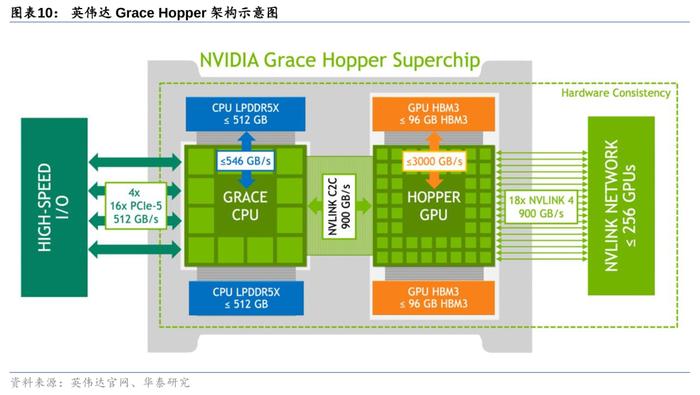
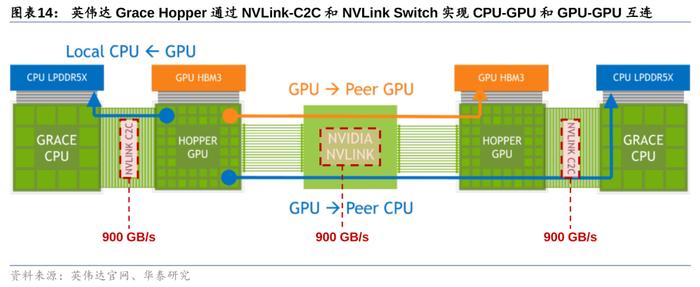
GraceHopper超级芯片:NVLink-C2C技术赋能芯粒互联。NVIDIANVLink-C2C是一种超快速的芯片到芯片、裸片到裸片的互连技术,它从PCB级集成、多芯片模块(MCM)、硅中介层或晶圆级连接实现扩展,是GraceHopper超级芯片异构集成的关键。通过NVLink-C2C技术,GraceCPU与HopperH100GPU构成一个完整的系统,并实现内存相互访问,从而无需沿循“CPU-内存-主板-显存-GPU”基于主板PCIe的迂回路线,减少了CPU计算损耗,并大幅提升功耗效率、延时和带宽。值得注意的是,NVLink-C2C技术不仅止于CPU+GPU,而是支持定制裸片与NVIDIAGPU、CPU、DPU、NIC和SoC等多种芯片之间的一致互连,将为数据中心带来全新的系统级集成芯产品。
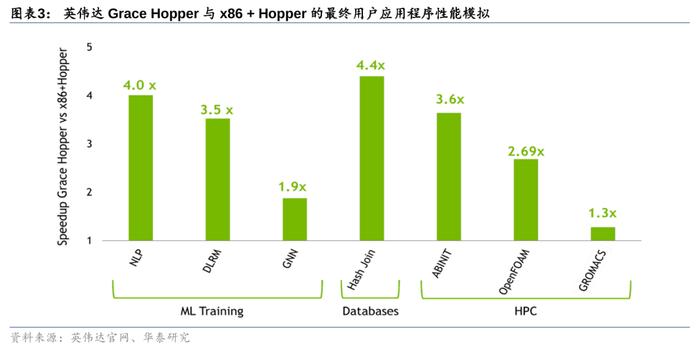
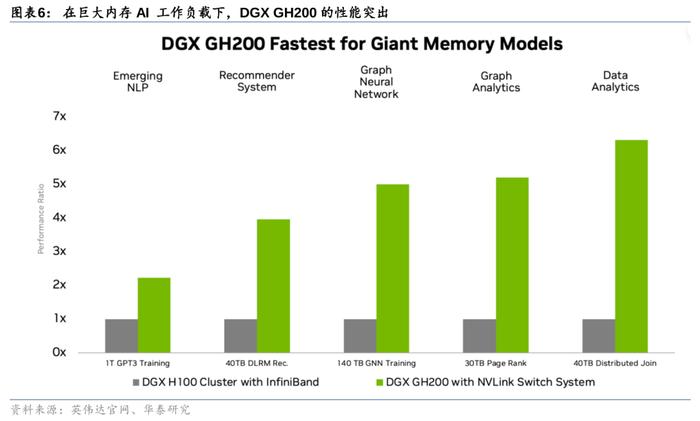
DGXGH200超级计算机:GraceHopper超级芯片+NVIDIANVLinkSwitchSystem,专为新一代大规模AI模型而设。DGXGH200超算是第一款将GraceHopper超级芯片与NVIDIANVLinkSwitchSystem配对使用的超级计算机,它通过NVLink互连技术及NVLinkSwitchSystem串联32台由8块GH200超级芯片组成的系统,将总计256块GH200Superchip合并成单一超级计算机,提供了1exaFLOPS=1000petaFLOPS算力与144TB的内存。这种大规模共享内存解决了大规模AI的关键瓶颈,将为生成式AI语言应用、推荐系统和数据分析工作负载的巨型模型增添动力。GoogleCloud、Meta与微软将是DGXGH200的首批用户。
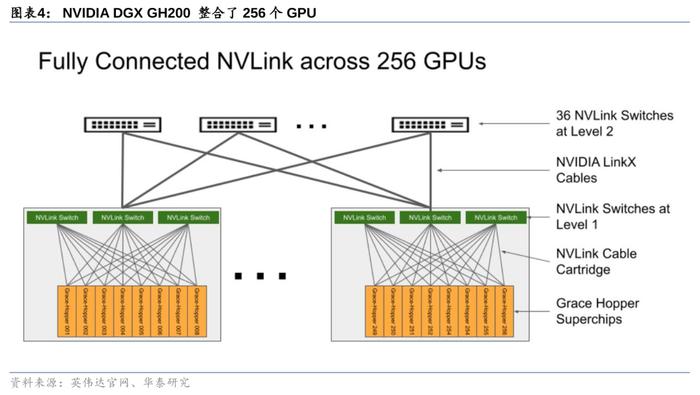
先进的加速计算+网络技术,为吞吐量和可扩展性迎来新突破。DGXGH200集成了英伟达最先进的加速计算和网络技术,为提供最大的吞吐量和可扩展性而设计。NVIDIANVLink-C2C将CPU与GPU相连组成GH200超级芯片,它们再通过NVLinkSwitchSystem组成高带宽的多GPU系统,每个GraceHopper超级芯片还配有一个NVIDIAConnectX-7网络适配器和一个NVIDIABlueField-3NIC。从具体参数上看DGXGH200性能优异,DGXGH200可提供高达1exaFLOPS的算力,标志着GPU在AI和数据分析工作负载加速计算的又一突破。
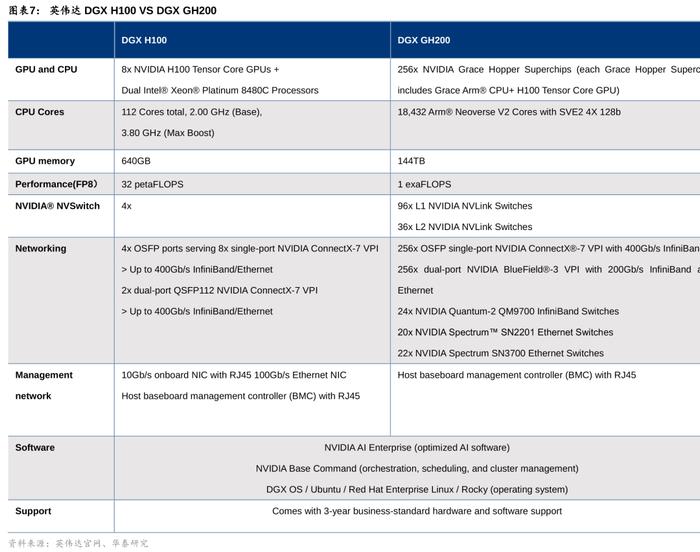
英伟达GH200vsAMDMI300
与英伟达GH200超级芯片类似,AMD在2023下半年即将推出的MI300也将采用CPU+GPU架构,同样发力于AI训练市场。AMD于CES2023介绍了新一代InstinctMI300加速器,结合CPU与GPU,重点发力数据中心的HPC及AI领域,对标英伟达GraceHopper(GraceCPU+HopperH100GPU),一改过去AMD的GPU产品主要应用在图像处理及AI推理领域的局限。公司早前在22Q4财报电话会里提及,MI300已开始送样给重要客户,而正式推出将会在下半年,2024年将看到明显贡献。我们认为,MI300虽然目前可能在网络互联技术和生态圈较为受限,但在突出的性能和高性价比下或将成为AMD在AI竞争的关键拐点?
我们将从芯片架构和制程、算力、内存带宽、价格和软件生态对AMDMI300和英伟达GH200两者竞争优势展开对比:
1)芯片架构:CPU+GPU仿生人脑结构,制程看齐英伟达。MI300是AMD首款结合了Zen4CPU与CNDA3GPU的产品,也是市场上首款“CPU+GPU+内存”一体化产品。MI300采用3D堆叠技术和Chiplet设计,配备了9个基于5nm制程的芯片组(据PCgamers推测,包括3个CPU和6个GPU),置于4个基于6nm制程的芯片组之上。因此在制程上,MI300属台积电5nm,相较MI200系列的6nm实现了跃迁,并与英伟达GraceHopper的4nm制程(属台积电5nm体系)看齐。MI300晶体管数量达到1460亿,多于英伟达H100的800亿,以及前代MI250X的582亿晶体管数量。CDNA3架构是MI300的核心DNA,MI300配备了24个Zen4数据中心CPU核心和128GBHBM3内存,并以8192位宽总线配置运行。


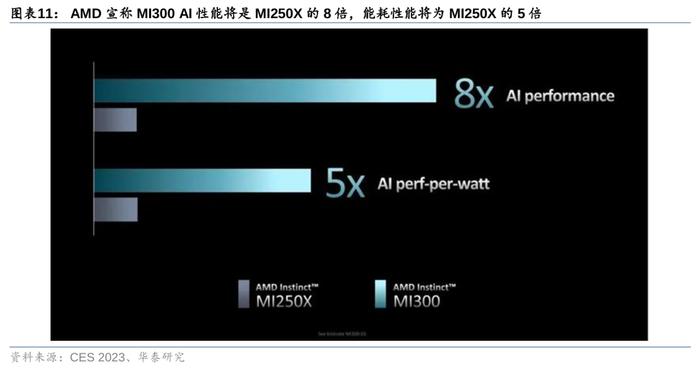
2)算力:MI300的性能逼近英伟达GraceHopper。AMD上代MI250X(发布于2021年11月)FP32算力达47.9TFLOPS,虽已超越英伟达A100的19.5TFLOPS(发布于2020年6月),但其发布时间在英伟达之后。AMD暂时未公布MI300与英伟达GraceHopper在算力上的对比,但相较上一代的MI250X,MI300在AI上的算力(TFLOPS)预计能提升8倍,能耗性能(TFLOPS/watt)将优化5倍。因此,此次MI300的性能提升后有望逼近GraceHopper水平。另外,GraceHopper支持8位浮点精度,而MI250X仅支持16位及以上,但MI300或将在AI训练中支持4位和8位浮点精度,可进一步节省算力。
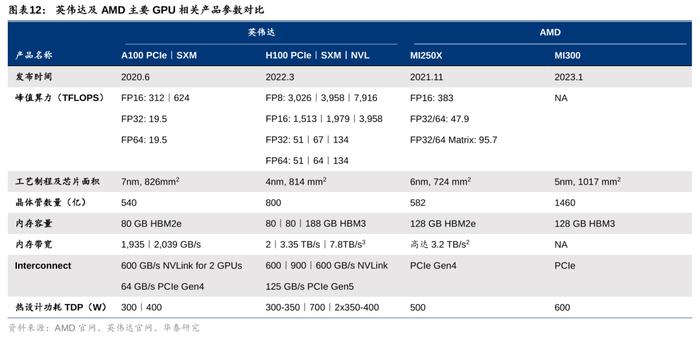
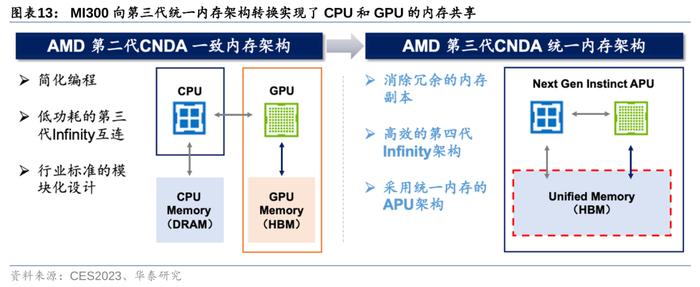
3)内存带宽:MI300通过“统一内存架构”(UnifiedMemory)便利GPU-CPU间数据传输,效果类比英伟达NVLinkC2C技术。MI300的3DChiplet架构使其内部CPU和GPU可共享同一内存空间,针对相同数据同时展开计算,实现“zero-copy”(即CPU执行计算时无需先将数据从某处内存复制到另一个特定内存区域),便利单节点内GPU-CPU之间的数据传输,减少内存带宽的占用。而英伟达GraceHopper则通过NVLink-C2C实现GPU-CPU高速互联,双方作为内存共享对等体可以直接访问对方的对应内存空间,支持900GB/s的互联速度。尽管AMD暂未公布MI300的传输带宽,但其创新的统一内存架构实现了GPU-CPU在物理意义上真正的内存统一。AMD虽未公布MI300HBM的更多信息,但最新代HBM3内存带宽约为819GB/s,与英伟达NVLinkC2C900GB/s带宽相差不大。因此MI300内GPU-CPU的统一架构可绕过传统连接协议速度的障碍,突破GPU-CPU之间的数据传输速度限制,满足未来AI训练和推理中由模型大小和参数提升带来的海量数据计算和传输需要。但值得一提的是,英伟达还可以通过NVLinkSwitch、Quantum-2InfiniBand等技术实现更多层次的互联,实现带宽内存几个数量级的提升,有效解决GPU大规模并行运算中“单节点本地内存不足”的痛点,MI300的相关技术信息尚未发布。
4)价格:高性价比策略或为AMD在与英伟达的竞争中再添一码。尽管AMD尚未公布MI300定价,管理层在FY23Q1财报电话会中表示数据中心产品将延续往日的高性价比定价风格,重点关注先把市场打开。成本效益乃云厂商的重中之重,加上单一依赖一个厂商也并非他们所愿。公司预计MI300将于今年底前推出,并将搭载于劳伦斯利弗莫尔国家实验室的百亿级超级计算机EICapitan及其他大型云端客户AI模型中。公司预计MI300营收将在23Q4开始放量,24年持续爬升。
5)软件生态:对比英伟达的CUDA(ComputeUnifiedDeviceArchitecture)生态圈,AMD的ROCm(RadeonOpenComputeEcosystem)或是其打破英伟达独大局势的一大障碍。英伟达于2007年发布CUDA生态系统,开发人员可以通过CUDA部署GPU进行通用计算(GPGPU)。通过先发优势和长期耕耘,CUDA生态圈已较为成熟,为英伟达GPU开发、优化和部署多种行业应用提供了独特的护城河。AMD的ROCm发展目标是去建立可替代CUDA的生态。而ROCm于2016年4月发布,相比2007年发布的CUDA起步较晚。全球CUDA开发者2020年达200万,2023年已达400万,包括Adobe等大型企业客户,而ROCm的客户主要为研究机构,多应用于HPC。对任何一种计算平台和编程模型来说,软件开发人员、学术机构和其他开发者与其学习、磨合和建立生态圈都需要时间,更多的开发者意味着不断迭代的工具和更广泛的多行业应用,进一步为选择CUDA提供了更为充分的理由,正向循环、不断完善的生态也将进一步提高其用户粘性。
针对这样的现状,AMD在丰富其软件生态也持续有积极动作。虽然目前仅有部分SKU支持Windows系统,但主流Radeon显卡用户可以开始试用过去仅专业显卡才能使用的AMDROCm(5.6.0Alpha)。23Q1公司宣布其ROCm系统融入PyTorch2.0框架,目前TensorFlow和Caffe深度学习框架也已加入第五代ROCm。ROCm也能对应到CUDA的部分内容,例如ROCm的HIP对应CUDAAPI,只需要替换源码中的CUDA为HPI就可以完全移植。
人脑神经网络的运作模式始终是人工智能追求的终极形态,CPU+GPU类比人类左右脑协同工作,或将成为AI芯片的主流技术方向。早在2011年,AMD产品构想中就以CPU和GPU分别类比人类左右脑,并基于此提出了CPU+GPU的异构产品策略。类比人脑,AMD认为左脑更像CPU,负责对信息的逻辑处理,如串行运算、数字和算术、分析思维、理解、分类、整理等,而右脑更像GPU,负责并行计算、多模态、创造性思维和想象等。GPU的算力高,并针对并行计算,但须由CPU进行控制调用,发布指令。在AI训练端,CPU可负责控制及发出指令,指示GPU处理数据和完成复杂的浮点运算(如矩阵运算)。
从Spectrum-X网络平台到超算系统,英伟达全面加速AI计算
除了GH200超级芯片及DGXGH200超算系统的重磅发布,黄仁勋在本次2023COMPUTEX大会还宣布了多款新品全面加速AI计算:
NVIDIASpectrum-X是全球首个面向AI的以太网网络平台。Spectrum-X基于网络创新,将英伟达Spectrum-4以太网交换机与英伟达BlueField-3DPU紧密耦合,实现了相比传统以太网结构1.7倍的整体AI性能和能效提升,并通过性能隔离增强了多租户功能,在多租户环境中保持一致、可预测的性能。Spectrum-X具有高度通用性,可为人工智能、机器学习和自然语言处理等多元应用提升云端效能。它使用完全基于标准的以太网,并可与基于以太网的堆栈互操作。目前,全球领先的云计算提供商正在采用Spectrum-X平台扩展生成式AI服务。Spectrum-X、Spectrum-4交换机、BlueField-3DPU等现已在戴尔、联想、超微等系统制造商处提供。
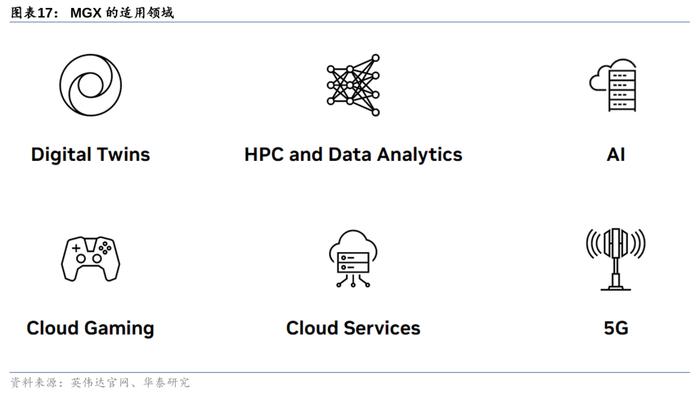
NVIDIAMGX是提供加速服务器的模块化架构,满足全球数据中心多样化的加速运算需求。NVIDIAMGX是介于DGX和HGX之间的模块化灵活组合,它为系统制造商提供了一个模块化参考架构,以快速、经济高效地制造100多种服务器机型,适用于广泛的AI、高性能计算和元宇宙应用。英伟达表示,ASRockRack、ASUS、GIGABYTE、Pegatron、QCT和Supermicro将采用MGX,它可将开发成本削减四分之三,并将开发时间缩短三分之二至仅6个月。
AI超级计算机NVIDIAHelios:DGXGH200+Quantum-2InfiniBand,将于2023年底推出。NVIDIA还将进一步升级网络技术,推出通过NVIDIAQuantum-2InfiniBand串连4台DGXGH200系统而成的超级计算机,并将其命名为Helios。该超级计算机内含1024(4*256)个GH200超级芯片,内存进一步升级为576TBHBM内存,用于提高训练大型AI模型的数据吞吐量,预计将在今年底上线。

本文作者:何翩翩S0570523020002 | ASI353,来源:华泰证券研究所(ID:huataiyjs),原文标题:《华泰|海外科技:英伟达GH200vsAMDMI300》
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。