
调查分析两百余篇大模型论文,数十位研究者一文综述RLHF的挑战与局限
RLHF方法虽然强大,但它并没有解决开发人性化人工智能的基本挑战。
自ChatGPT问世,OpenAI使用的训练方法人类反馈强化学习(RLHF)就备受关注,已经成为微调大型语言模型(LLM)的核心方法。RLHF方法在训练中使用人类反馈,以最小化无益、失真或偏见的输出,使AI模型与人类价值观对齐。
然而,RLHF方法也存在一些缺陷,最近来自MITCSAIL、哈佛大学、哥伦比亚大学等机构的数十位研究者联合发表了一篇综述论文,对两百余篇领域内的研究论文进行分析探讨,系统地研究了RLHF方法的缺陷。

论文地址:https://huggingface.co/papers/2307.15217
总的来说,该论文强调了RLHF的局限性,并表明开发更安全的AI系统需要使用多方面方法(multi-facetedapproach)。研究团队做了如下工作:
调查了RLHF和相关方法的公开问题和基本限制;
概述了在实践中理解、改进和补充RLHF的方法;
提出审计和披露标准,以改善社会对RLHF系统的监督。
具体来说,论文的核心内容包括以下三个部分:
1.RLHF面临的具体挑战。研究团队对RLHF相关问题进行了分类和调查,并区分了RLHF面临的挑战与RLHF的根本局限性,前者更容易解决,可以在RLHF框架内使用改进方法来解决,而后者则必须通过其他方法来解决对齐问题。
2.将RLHF纳入更广泛的技术安全框架。论文表明RLHF并非开发安全AI的完整框架,并阐述了有助于更好地理解、改进和补充RLHF的一些方法,强调了多重冗余策略(multipleredundantstrategy)对减少问题的重要性。
3.治理与透明度。该论文分析探讨了改进行业规范面临的挑战。例如,研究者讨论了让使用RLHF训练AI系统的公司披露训练细节是否有用。
我们来看下论文核心部分的结构和基本内容。
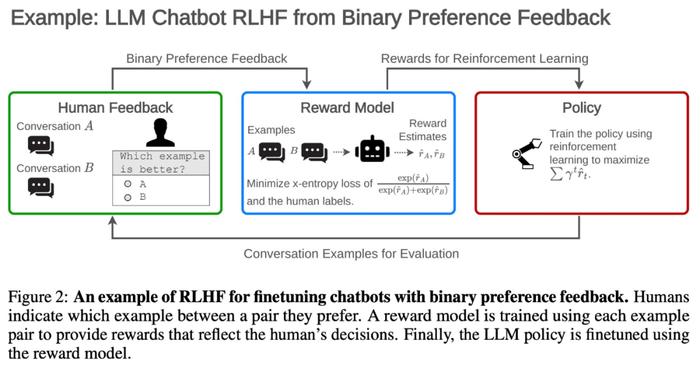
如下图1所示,该研究分析了与RLHF相关3个过程:收集人类反馈、奖励建模和策略优化。其中,反馈过程引出人类对模型输出的评估;奖励建模过程使用监督学习训练出模仿人类评估的奖励模型;策略优化过程优化人工智能系统,以产生奖励模型评估更优的输出。论文第三章从这三个过程以及联合训练奖励模型和策略四个方面探讨了RLHF方法存在的问题和挑战。
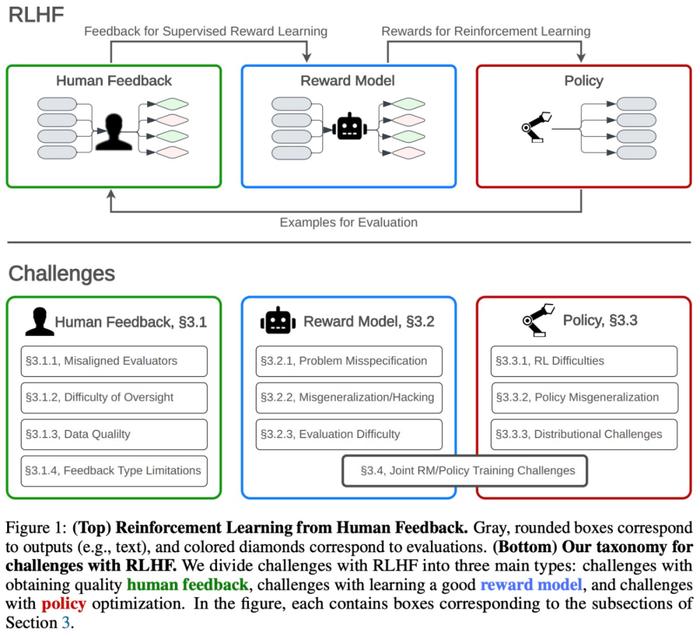
论文第三章总结的问题表明:严重依赖RLHF来开发人工智能系统会带来安全风险。虽然RLHF很有用,但它并没有解决开发人性化人工智能的基本挑战。
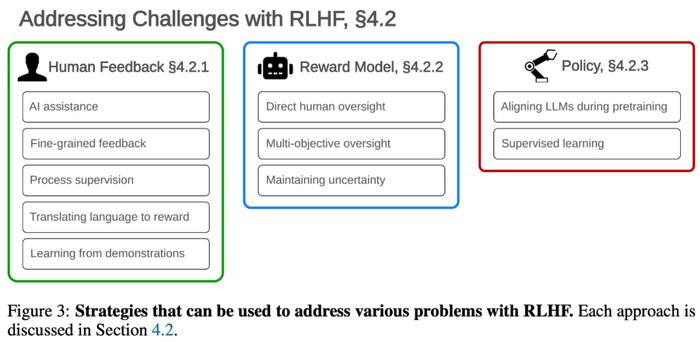
研究团队认为:任何单一策略都不应被视为综合解决方案。更好的做法是采用多种安全方法的「深度防御」,论文第四章从理解、改进、补充RLHF这几个方面详细阐述了提高AI安全性的方法。
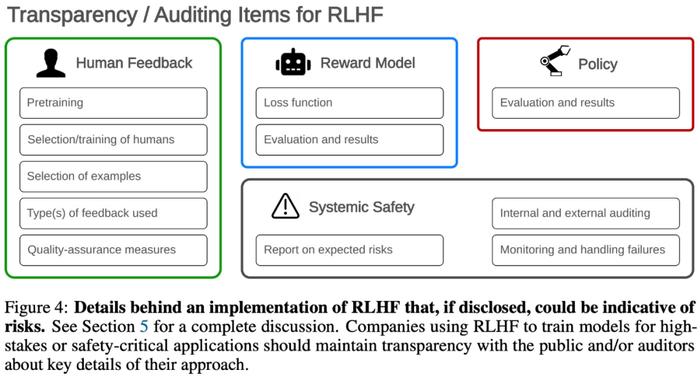
论文第五章概述了RLHF治理面临的风险因素和审计措施。
总结
该研究发现,实践中很多问题来源于RLHF的根本局限性,必须采用非RLHF的方法来避免或弥补。因此,该论文强调两种策略的重要性:(1)根据RLHF和其他方法的根本局限性来评估技术进步,(2)通过采取深度防御安全措施和与科学界公开共享研究成果,来应对AI的对齐问题。
此外,该研究阐明一些挑战和问题并非是RLHF所独有的,如RL策略的难题,还有一些是AI对齐的基本问题。
感兴趣的读者可以阅读论文原文,了解更多研究内容。