
20万张图片训练出医用AI大模型,斯坦福团队整理16年来社交网络数据并建库,使用图像或文本即可检索类似病例
来源:DeepTech深科技
下面这张图是2023年NatureMedicine9月刊的“封面故事”。从这张封面图里,可以直观地感受到20多万张来源于Twitter(现名 X)的病理医学图片。利用这些图片,美国斯坦福大学团队研发一款名为PLIP(pathologylanguage–imagepretraining)的AI模型。

对于本次论文,他们也收到了来自同行的高质量评价。比如,以色列特拉维夫大学艾多·沃尔夫(IdoWolf)博士表示:“这篇论文里有很多令人惊奇的地方。1、研究的民主化:网络上的信息对每个人都是开放的。2、数据量:数据库几乎是无限的。3、不需要监管和伦理批准:信息已经在线并向每个人开放。4、所能使用的数据、以及模型的方法是无穷的。”

缘何优于OpenAI的CLIP模型?
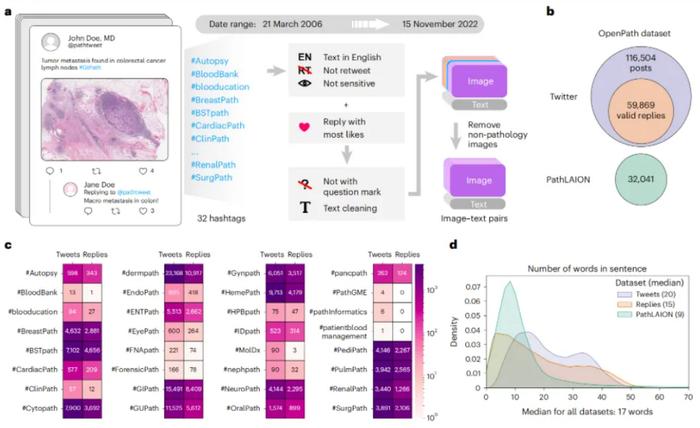
你可能会好奇,那些参与PLIP模型训练的图片是如何筛选的?研究人员表示:“是基于美国和加拿大病理学会在2016年倡议的医学Twitter 标签,通过严格的数据过滤从Twitter 及其他社交网络上选择的。既能保证数据具备较高的质量,又尽可能地涵盖更广的信息。”
不过,在收集数据的过程中,他们也意识到很多病理图片之所以会被分享到Twitter 上,是因为医生们觉得这些数据非常有学习价值,或者是非常经典的案例,又或者是比较罕见的病例。所以,这样的病理图像-文本数据,与其他AI模型的数据集有着很大不同。
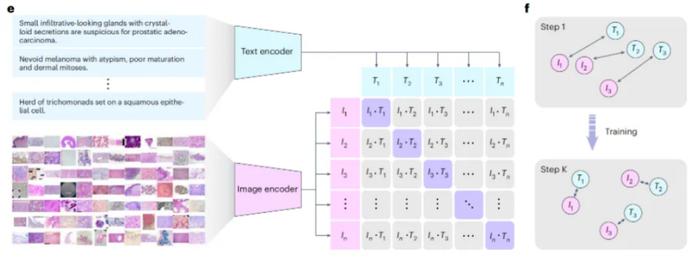
据介绍,PLIP模型的基本原理在于:对大量病理学图片、以及与其对应的自然语言描述进行监督训练,从而学习图像和文本之间的关联性,进而输出对于新图片的分类,以及根据文本或图片检索相似的病理案例。
不同于OpenAI 的CLIP模型,PLIP模型的主要差异在于利用大量的高质量病理学图片以及自然语言描述进行预训练,因此它对病理图片背后的语义知识有着更深入的理解。
而由于没有深入地学习医学图片,所以CLIP模型对于病理图像的理解能力相对欠佳。研发此次PLIP模型的斯坦福团队表示:“通过实验结果也不难看出,PLIP模型在病理医学任务上大幅领先CLIP模型。”
PLIP模型的性能之所以更好,主要在于它利用大量结构化的病理图像-文本对来进行训练。这些图像-文本对虽然来自于社交网络,但是该课题组仍然进行了非常严格的数据预处理和筛选,借此涵盖出几十种不同器官类型和染色模式,确保能够使用一批高质量、被认真标注过的数据来帮助模型进行学习。
通过学习高质量的数据,PLIP模型可以更好地理解病理图像背后的语义知识,从而在各种下游任务中表现得更为出色。
PLIP模型的输出结果也比较直观,且具备较好的用户友好度。和OpenAI 的CLIP模型一样的是,PLIP模型对于文本或图片的输出都是一个向量。即它可以通过对比学习,来找到和目标输入最接近的图片,因此其输出结果可以直接被用户读懂。
另外,PLIP模型不仅可以为新的病理图片进行分类,还可以让用户通过图像或自然语言搜索来检索相似案例,从而促进知识共享。
同时,PLIP模型主要是用于图像分类和检索,而不是生成文本。由于它的核心任务不是文本生成,因此“捏造”文本的风险相对较低。由于检索结果都是来自于真实且由医生提供的数据,所以具备较高的可信度。
本次论文发表之后,也有很多同行好奇收集社交网络的数据是否符合相关政策和规定。对此该团队表示:“2022年我们得到了Twitter 的教育API(EducationalAPI),在数据挖掘、数据收集、数据保存的过程中,完全遵守各个公司的相关规定。我们也咨询了律师,确保了本次工作完全符合版权法的规定。”

此前相关成果曾获本校投资
下一步,他们将收集更多数据来训练更大的模型。目前,他们正在收集的数据预计比OpenPath数据集大出几十倍。其次,他们将对PLIP模型进行优化和拓展,尤其将在更多医学细分领域之中开展应用。再次,他们还打算探索如何将PLIP与其他AI技术结合,以提供精确度更高、功能更多的医学图像解决方案。
此外,考虑到PLIP在教育方面的应用,他们还计划开发一个面向医学教育者和学生的在线平台,让他们能够更方便地访问相关资源、以及学习病理知识。
另据悉,担任论文一作的黄治,其本科和博士先后毕业于西安交通大学和美国普渡大学。求学过程之中,他逐渐对医学数据产生浓厚的兴趣,希望通过AI算法帮助人们解决临床问题和科研问题。

2021年,他加入斯坦福大学从事博士后研究,师从JamesZou 教授和托马斯·蒙提尼(ThomasMontine)教授。
除了本次论文之外,他还和导师开发了nuclei.io人工智能病理学标注和分析平台,后被选为“2022年度斯坦福医学院创新催化剂”九大创新产品之一,并获得了斯坦福大学的投资。

1.Huang,Z.,Bianchi,F.,Yuksekgonul,M.etal. Avisual–languagefoundationmodelforpathologyimageanalysisusingmedicalTwitter. NatMed 29,2307–2316(2023).https://doi.org/10.1038/s41591-023-02504-3
运营/排版:何晨龙