
双管齐下!北信源打造法信法律基座大模型安全解决方案
11月15日,在最高人民法院召开的“法信法律基座大模型”研发成果新闻发布会上,“法信法律基座大模型”正式向社会发布。“法信法律基座大模型”定位于法律行业基座模型,既是一个为法治领域提供生成式人工智能底层能力的基座模型,也是一套为保障法律人工智能安全发展,配套安全治理机制,提供数据资源、算力资源、评测资源的服务体系。
但随着AI大模型的应用范围越来越广,“生成式人工智能技术”在迅猛发展的同时,也带来了技术安全风险。面对AI大模型引发的全新安全挑战,行业应从哪些方面进行安全维护?
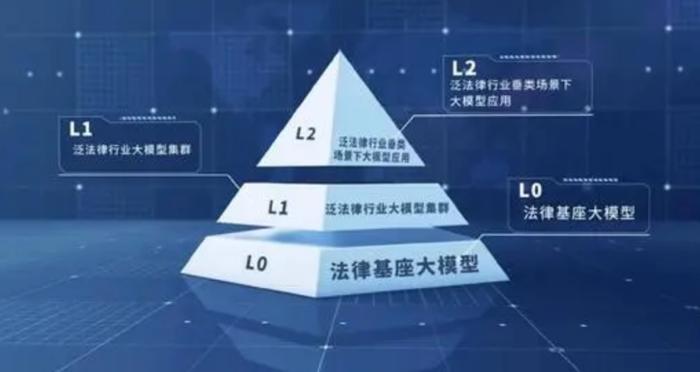
法信法律基座大模型
北信源打造法信法律基座大模型安全解决方案
北信源作为终端安全领军企业,在28年的发展中积累了深厚的安全技术和丰富的安全服务经验,不断将自身的安全理念融入AI的研究与应用中,并结合我国法律法规要求,针对法信法律基座大模型技术结构特点,从供应链安全风险和运行安全风险两个方面来识别其风险与安全威胁。
(一)供应链安全解决方案
供应链安全风险涉及多个环节包括硬件安全、软件及AI组件安全、数据投毒等,还有模型后门、大模型幻觉、提示词注入、对抗攻击、价值观伦理安全、大模型滥用等各类风险。
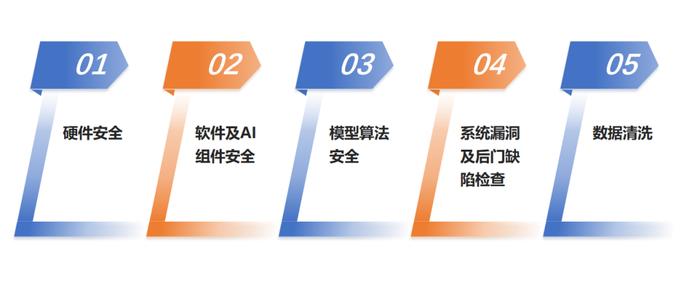
北信源结合多年网络和数据安全的经验,通过严格的供应链审查、安全认证、数据加密,以及外包管理,有效减少了供应链安全风险对法信法律基座大模型的影响,并提出五大应对措施:
对所有使用的软件及AI组件进行安全验证,使用安全扫描工具识别潜在的漏洞。在使用第三方模型或预训练模型前,进行详细的代码审查和模型测试。
在训练模型时,故意引入一些带有噪声或对抗性干扰的输入,训练模型在遇到这些扰动时仍能正确预测。可以提升模型在面对攻击或意外输入时的稳定性。
③数据增强:
通过在训练过程中增加更多样化的数据(例如改变角度、添加噪声、调整亮度等),可以提高模型对现实世界中各种不同情况的适应能力,减少其对特定输入的依赖。
④鲁棒性测试:
定期对模型进行鲁棒性测试,包括模拟不同的恶意攻击或异常数据输入,查看模型是否能稳定表现。可以找出模型在面对哪些情况时容易失败,从而有针对性地改进。
⑤输入数据校验:
在模型使用前,增加一层验证机制,检查输入数据是否被篡改或添加了异常信息。运行安全风险包含了通信网络安全、区域边界安全、计算环境安全、平台漏洞、数据泄露、隐私泄露、数据窃取与篡改等。
(二)运行安全解决方案
运行安全风险包含了通信网络安全、区域边界安全、计算环境安全、平台漏洞、数据泄露、隐私泄露、数据窃取与篡改等。
根据法信法律基座大模型的业务应用场景,北信源按照GB/T22239-2019《信息安全技术网络安全等级保护基本要求》第三级的安全防护能力,开展其规划设计和安全建设。
基于等级保护构建“一个中心(安全管理中心)、三重防护(安全通信网络、安全区域边界、安全计算环境)”的纵深安全防护体系。并增加了大模型业务特有的安全防护保障能力,应对措施包含以下六个方面:
①安全开发和代码审查:
在AI系统开发过程中,采用严格的安全开发流程,确保每一步都经过安全性验证;定期进行代码审查和安全测试,识别并修复潜在漏洞和后门。
使用防后门检测工具和对抗性测试,对AI模型进行全面的安全性评估,确保模型未被植入恶意后门。
③强化访问控制:
通过部署AI防火墙,实施严格的访问控制策略,限制只有经过授权的人员才能访问和修改AI系统的核心代码和模型。
④防篡改机制:
使用防篡改技术保护模型的完整性,确保模型在使用过程中不会被未经授权的修改或注入恶意代码。
⑤模型更新和监控:
使用AI漏洞探测系统定期更新AI模型和系统,修补已知漏洞,并对模型的行为进行持续监控,识别任何潜在的异常活动。
⑥输出后验证:
使用信源密信系统和密信AI能力安全平台,对模型的输出进行验证,向用户提示模型的输出可能不完全准确,提醒用户进行核实,保障最终输出环节的验证。

随着时代的发展,AI大模型的应用范围越来越广,在使用过程中,我们应严格遵循法律法规,确保其安全性与合规性,共同营造一个健康、有序、可持续的AI发展环境,共迎AI时代的机遇与挑战!未来北信源仍将不断创新研发,积极探索“AI+安全”解决方案,帮助用户更安全地享受AI技术带来的便捷和高效。