
北大团队构建“情境化构念表征”框架,用AI大模型感知已逝去的心灵
来源:DeepTech深科技
历史学和考古学的目的,是重现已消逝的生活。而历史文本,则是心理学家眼中的“遗迹”和“化石”。
北京大学历史系博士生、美国哈佛大学定量社会科学研究所联合培养博士生陈钰琪和合作者,则希望利用AI模型在大规模的历史文本中测量那些已逝去的心灵。

长期以来,文化心理学家对人类的历史一直抱有强烈的兴趣,因为文化和心理的演进并非一蹴而就,而是在漫长的历史时段中形成的。他们的思想与行为是由社会塑造的,而社会是由历史塑造的。
然而,问卷调查等科学实验方法在面对已逝去的心灵时没有用武之地,研究者们因历史无法重现而束手无策。
而自然语言处理(NLP,NaturalLanguageProcessing)与文本定量分析方法的不断更新,为相关研究带来了越来越多的可能。
基于此,陈钰琪等人开发了一种名为“情境化构念表征”(CCR,ContextualizedConstructRepresentation)的框架,以用于测量带有上下文情境的历史文本中的心理构念,如集体主义、传统主义、社会规范强度等。
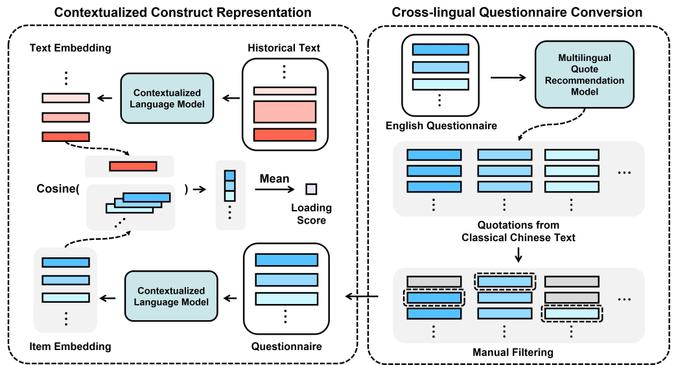
CCR方法的基本原理是利用Transformer模型,同时辅以心理学量表与待测量文本的文本嵌入,并通过相似度计算得到待测量文本在该量表主题下的“载荷分数”。
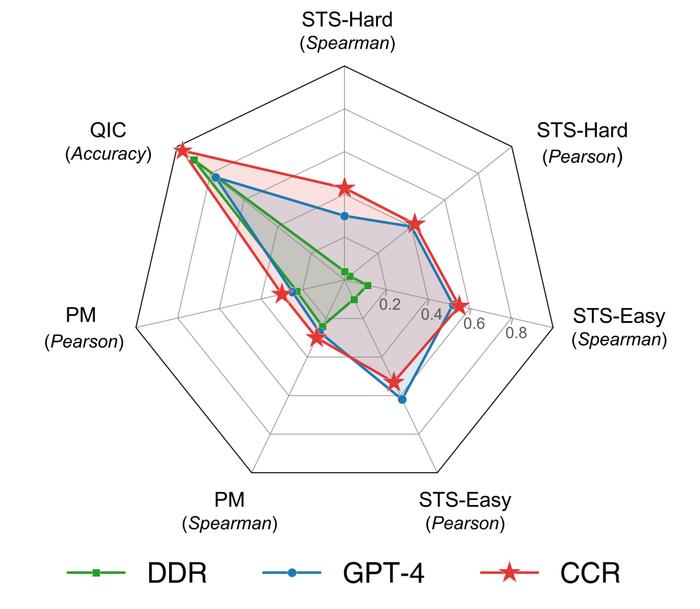
通过在专门测试集上执行语义文本相似度、量表分类和心理测量等任务,陈钰琪和合作者针对CCR方法、过去心理学界主流采用的“分布式词典表征”(DDR,DistributedDictionaryRepresentation)方法、基于生成式大模型的小样本提示方法这三种方法,在不同模型上的表现进行了比较。
通过使用微调之后的模型,他们发现CCR方法在所有任务上的表现,均超过了传统的DDR方法,并在大部分任务上也超过了使用GPT-4(gpt-4-turbo-0125-preview版本)的小样本提示方法。
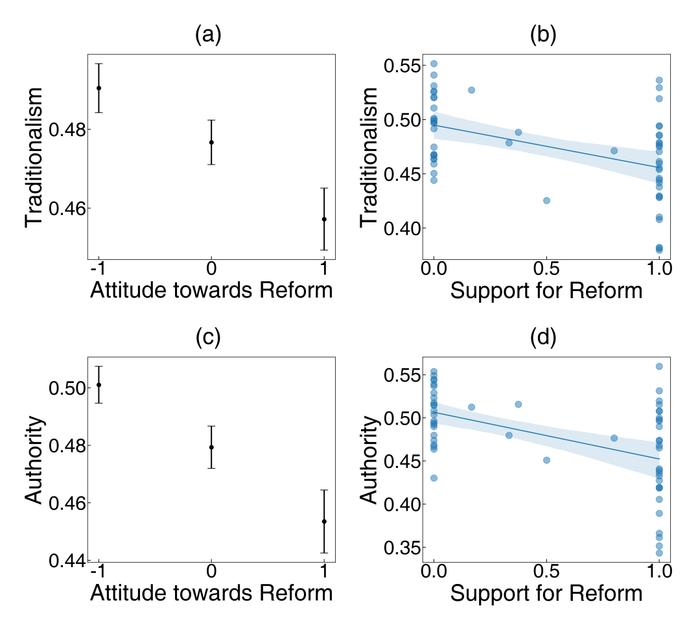
此外,他们也在由人工标注的真实历史数据集上,验证了CCR方法的可靠性。比如,通过CCR方法测量北宋时期不同官员所撰写文章中传统主义的心理指标分数,可以有效推测该官员是否在王安石新政中支持变法。
总的来说,该方法可以帮助心理学家、历史学家以及任何对古代文化演变感兴趣的研究人员,在相对较低的计算资源耗费下,针对不同的心理学构念或文化主题,对古代历史文本进行大规模的测量和分析,进而验证假说,揭示现代文化现象的历史根源。
研究中,他们面临的第一个问题是,受到广泛认可的心理学量表绝大多数是英文的,因此需要先将英文量表与中国古代文言文进行对齐,才能进行下一步测量。
直接将英文翻译为文言文可能是不妥当的,因为在相关语境差异巨大的情况下,很多词汇难以找到合适的表达,由人工生造的句子往往显得生硬。
为了解决这个问题,他们采用了清华大学孙茂松教授课题组之前的方法,使用多语言的引文推荐模型,将与量表中的英文句子语义相似度高的文言文引文放入备选池。
并进一步通过手工筛选去除噪音,得到与英文量表对应的文言文量表。这些引文均来自于实际历史文本,而非翻译或人工生成,因此自然而然地符合文言文的语境。
接下来的第二个问题是,要从中国古代历史文本得到准确的文本嵌入需要合适的模型。目前,已有许多在文言文语料上预训练的Transformer模型,但没有针对语义相似度或心理测量这一特殊下游任务的模型。
针对语义相似度等任务进行训练的中文文本嵌入模型,则往往基于现代语料和数据集,因此并不适应于专门的心理测量任务。
而他们所需要的文本嵌入模型,要能够对文言文、尤其是文言文中的心理构念及其上下文情境进行准确的表征,只有这样才能胜任从道德价值判断的角度进行语义相似度计算的任务。
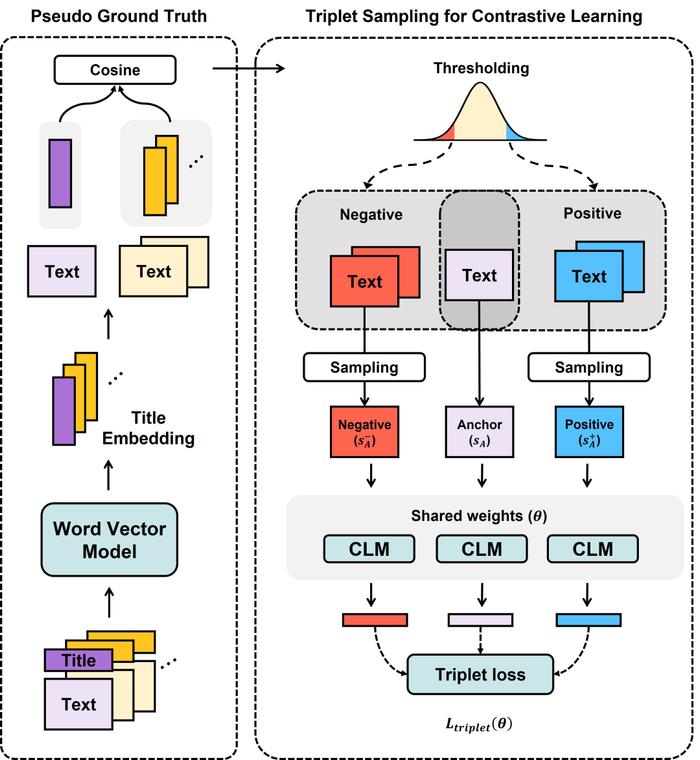
为了解决这一问题,他们提出一种基于间接监督和对比学习的训练方法。
由于相关领域数据的缺乏,他们通过手工搜集的方式,构建了第一个中文历史心理学语料库(C-HI-PSY,ChineseHistoricalPsychologyCorpus),该语料库包括667个与心理或道德相关主题下的21539条文言文段落。
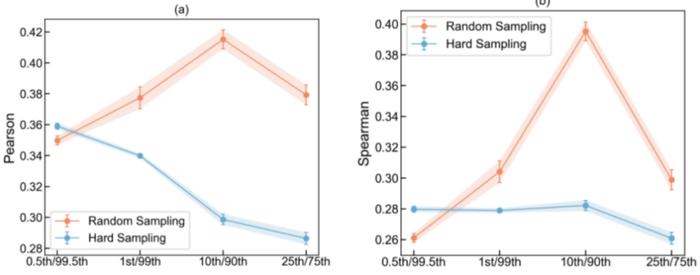
然后,他们通过在更大规模文言文语料上训练的词向量模型,获取了不同主题的词向量表示,借此计算不同主题词向量之间的相似度,并将之作为不同主题所对应文本之间心理语义层面相似度的伪真值。
后又通过随机采样或困难采样等不同的采样方式,为C-HI-PSY训练集中的每一个段落,采集n个相似度伪真值高的正样本、以及相似度伪真值低的负样本,借此构成anchor-positive-negative三元组,从而利用三元组损失函数对模型进行微调。
接着,他们在多个针对文言文或中文的Transformer模型上,根据不同的超参数组合进行实验,在C-HI-PSY验证集和测试集上分别进行语义相似度任务的评估。结果发现,所有模型在微调后的表现都有显著提高。
陈钰琪表示:“多元化的背景是他们得以完成这样跨学科的研究工作的重要因素之一。”
论文的前三位作者均为女性,在合作过程中大家的关系非常融洽。陈钰琪说:“我们相信女性的力量,也相信女性的细腻、耐心的特质会为研究增色。
比如,第三作者黎颖曾参加过微软亚洲研究院举办的面向女生的AdaWorkshop,接触到了科技领域很多令人敬佩的女性榜样,这让她很受鼓舞。”
通过使用CCR方法,他们与哈佛大学团队合作,在上万本古籍中首次测量了集体主义、个人主义、忠诚、荣誉等十几个作为文化心理和道德基础的指标,在跨越数千年的中国历史上的历时演变及其空间分布,借此尝试揭示东西方文化心理差异的根源。相关文章也即将发布预印本。
另据悉,陈钰琪本硕博阶段均在北大历史学系接受最传统的人文学科训练。对她来说,跨界研究AI模型原本是难以想象的事情。
博士阶段,因研究面临浩如烟海的考古材料,她开始寻找大规模分析的方法,由此接触到量化研究和数字人文领域,新世界的大门开始对她打开。
起初她也曾有过较为漫长的艰难探索阶段,从最基础的线性代数开始补习数学,通过Coursera学习编程,从参与数据标注到独立设计数据库,从调用模型到训练模型,种种曲折,不一而足。
“期间受到了很多人的帮助,也非常感激我的博士导师在对待我的‘不务正业’时的开放胸怀。到现在,我已经在GitHub上开发了包括OCR文字识别、异体字转换、历史地理编码器等多个面向人文学者的开源项目。”她说。
一路走来,计算机和相关领域的开源精神使她受益匪浅,跨学科研究的经历则让她深信:古老的学科也可以拥抱崭新的技术,新的技术属于所有人。
参考资料:
1.https://arxiv.org/abs/2403.00509
排版:希幔