
NeurIPS 2022 | 文本图片编辑新范式,单个模型实现多文本引导图像编辑
最近用文本来引导图像编辑取得了非常大的进展以及关注度,特别是基于去噪扩散模型如StableDiffusion或者DALLE等。但是基于GAN的文本-图像编辑依旧有一些问题等待解决,例如经典的StyleCILP中针对每一个文本必须要训练一个模型,这种单文本对单模型的方式在实际应用中是不方便的。本文我们提出FFCLIP并解决了这个问题,针对灵活的不同文本输入,FFCLIP只需要一个模型就能够对图片进行相应的编辑,无需针对每个文本重新训练模型,并且在多个数据集上都取得了非常不错的效果。
论文简要概述
利用文本对图像进行编辑的相关研究非常火热,最近许多研究都基于去噪扩散模型来提升效果而少有学者继续关注GAN的相关研究。本文基于经典的StyleGAN和CLIP并提出语义调制模块,从而对不同的文本仅需要单个模型就可以进行文本-图像编辑。
本文首先利用已有的编码器将需要编辑的图像转换到StyleGAN的W^+语义空间中的潜在编码w,再通过提出的语义调制模块对该隐编码进行自适应的调制。该语义调制模块包括语义对齐和语义注入模块,首先通过注意力机制对齐文本编码和GAN的隐编码之间的语义,再将文本信息注入到对齐后的隐编码中,从而保证该隐编码拥有文本信息从而达到利用文本编辑图像能力。
不同于经典的StyleCLIP模型,我们的模型无需对每个文本单独训练一个模型,一个模型就可以响应多个文本从而对图像做有效的编辑,所以我们的模型成为FFCLIP-FreeFormText-DrivenImageManipulation。同时我们的模型在经典的教堂,人脸以及汽车数据集上都取得了非常不错的效果。

论文地址:https://arxiv.org/pdf/2210.07883.pdf
Github地址:https://github.com/KumapowerLIU/FFCLIP
背景和启示
最近,描述用户意图的自由文本提示已被用于编辑StyleGAN潜在空间以进行图像编辑操作[1、2]。一句话(例如,‘Blue’)或短语(例如,‘Managed10’)作为输入,这些方法通过调制StyleGAN潜在空间中的潜在编码来相应地编辑所描述的图像属性。
精确的文本-图像编辑依赖于StyleGAN的视觉语义空间与CLIP的文本语义空间之间的精确潜在映射。比如当文本提示是“惊喜”,我们首先在视觉语义空间中识别其相关的语义子空间(即“表情”,因为惊喜属于表情这个属性)。找到与文本相对应的语义子空间后,文本会告诉我们隐编码的变化方向,从让隐编码从当前的表情变化到惊喜的表情。TediGAN[1]和StyleCLIP[2]等开创性研究凭经验预先定义了哪个潜在视觉子空间对应于目标文本提示嵌入(即TediGAN中的特定属性选择和StyleCLIP中的分组映射)。这种经验识别限制了给定一个文本提示,他们必须训练相应的编辑模型。
不同的文本提示需要不同的模型来调制StyleGAN的潜在视觉子空间中的潜在代码。虽然StyleCLIP中的全局方向方法没有采用这样的过程,但参数调整和编辑方向是手动预定义的。为此,我们有理由来探索如何通过显性的文本自动的找到隐性的视觉语义子空间,从而达到单个模型就可以应对多个文本。
在这篇论文中,我们提出了FFCLIP-FreeFormCLIP,它可以针对不同的文本自动找到相对应视觉子空间。FFCLIP由几个语义调制模块组成,这些语义调制模块把StyleGAN潜在空间W^+中的潜在编码w^+和文本编码e作为输入。
语义调制模块由一个语义对齐模块和一个语义注入模块组成。语义对齐模块将文本编码e作为query,将潜在编码w作为key和Value。然后我们分别在position和channel维度上计算交叉注意力,从而得到两个注意力图。接着我们使用线性变换将当前的视觉空间转换到与文本对应的子空间,其中线性变换参数(即平移和缩放参数)是基于这两个注意力图计算的。通过这种对齐方式,我们可以自动的为每个文本找到相应的视觉子空间。最后,语义注入模块[3]通过之后的另一个线性变换修改子空间中的潜在代码。
从FFCLIP的角度来看,[1,2]中子空间经验选择是我们在语义对齐模块中线性变换的一种特殊形式。他们的组选择操作类似于我们的缩放参数的二进制值,以指示w的每个位置维度的用法。另一方面,我们观察到W^+空间的语义仍然存在纠缠的现象,经验设计无法找到StyleGAN的潜在空间和CLIP的文本语义空间之间的精确映射。相反,我们的语义对齐模块中的缩放参数自适应地修改潜在代码w以映射不同的文本提示嵌入。然后通过我们的平移参数进一步改进对齐方式。我们在基准数据集上评估我们的方法,并将FFCLIP与最先进的方法进行比较。结果表明,FFCLIP在传达用户意图的同时能够生成更加合理的内容。
FFCLIP
图1所展示的就是我们的整体框架。FFCLIP首先通过预训练好的GANinversion编码器和文本编码器得到图像和文本的潜在编码,其中图像的潜在编码则是之前提到的StyleGAN视觉语义空间W^+中的w,而文本编码则是e_t。我们和StyleCLIP一样采用e4eGANinversion编码器[4]和CLIP中的文本编码器来分别得到相应的潜在编码。接着我们将e_t和w作为调制模块的输入并输出得到w的偏移量∆w,最后将∆w与原始的w相加并放入预训练好的StyleGAN中得到相应的结果。
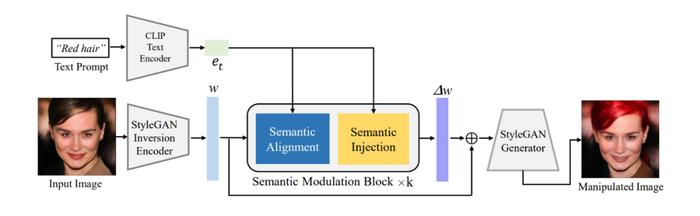
下图二就是我们的语义调制模块。在语义对齐模块中(Semantic Alignment),我们可以清晰地看到我们将∆w设置为Key和Value并将e_t设置为Query来计算两个注意力图,这两个注意力图的大小分别是18×1以及512×512。接着我们将18×1的注意力图当作线性变换中缩放系数S,我们计算该注意力图的过程如下:
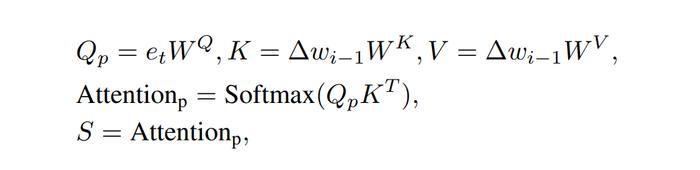
同时我们将512×512的注意力图与Value相乘以后再经过Pooling操作得到显性变换中的平移系数T。我们计算该注意力图的过程如下:
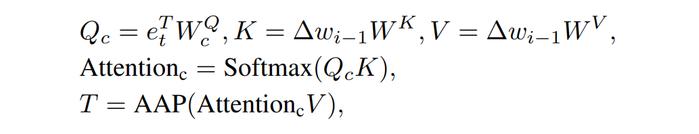
拥有了平移和缩放系数后,我们就可以通过线性变换为当前文本e_t找到相对应的视觉子空间,计算步骤如下:
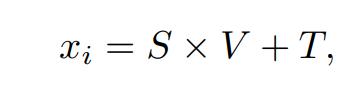
期中x_i是我们第i个语义调制模块的输出结果。由于∆w的大小是18×512,所以18×1和512×512的注意力图分别是在∆w的position和channel两个维度上进行注意力图的计算,这个操作类似于DualAttention[5].
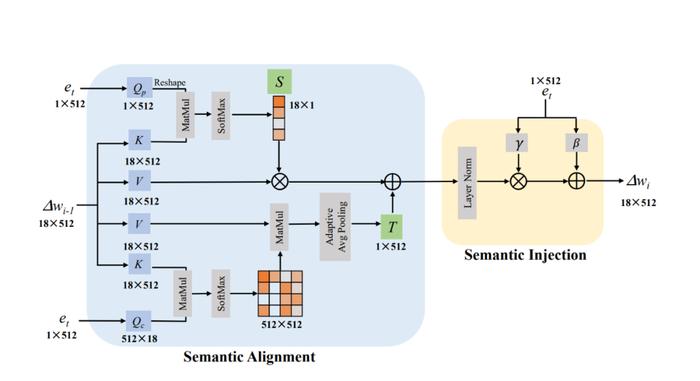
我们通过以上的操作可以得到与文本对应的视觉子空间,紧接着我们采用类似AdaIN的方式,将文本信息注入到这个空间中,从而得到最后的结果,我们称这个操作为语义注入模块(SemanticInjection)。整个模块的实现步骤如下:
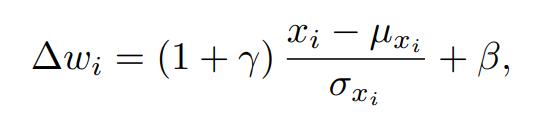
最终我们的FFCLIP中一共堆叠了4个语义调制模块,并最终得到最后的偏移量∆w。
实验结果


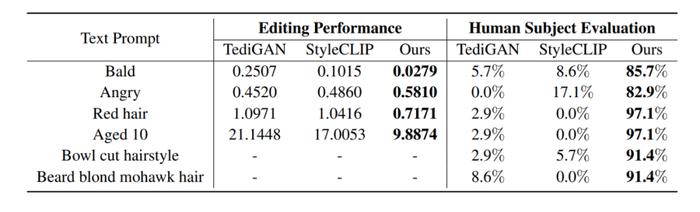
如图3所示,我们与StyleCLIP[1],TediGAN[2]以及HairCLIP[3]进行了视觉上的对比:可以看到FFCLIP能够更好的反应文本的语义,并且生成更加真实的编辑图像。同时相对应的数值对比结果如下表所示,我们的方法无论是在客观数值还是在主观数值上都能取得最好的效果。
同时我们的方法还展现出了非好的鲁棒性,FFCLIP在训练中并未见过词的组合而是用单个的单词进行训练,但是在测试中能够很好的针对词组的语义对图像进行编辑,视觉效果如图4所示。

更多的实验结果和消融实验请看原文。
总结
我们在本文中提出了FFCLIP,一种可以针对不同文本但只需要单个模型就能进行有效图像编辑的新方法。本文动机是现有方法是根据已有的经验来匹配当前文本和GAN的语义子空间,因此一个编辑模型只能处理一个文本提示。我们通过对齐和注入的语义调制来改进潜在映射。它有利于一个编辑模型来处理多个文本提示。多个数据集的实验表明我们的FFCLIP有效地产生语义相关和视觉逼真的结果。
参考文献
1.OrPatashnik,ZongzeWu,EliShechtman,DanielCohen-Or,andDaniLischinski.Styleclip:Text-drivenmanipulationofstyleganimagery.InIEEE/CVFInternationalConferenceonComputerVision,2021.
2.WeihaoXia,YujiuYang,Jing-HaoXue,andBaoyuanWu.Tedigan:Text-guideddiversefaceimagegenerationandmanipulation.InIEEE/CVFConferenceonComputerVisionandPatternRecognition,2021.
3.TianyiWei,DongdongChen,WenboZhou,JingLiao,ZhentaoTan,LuYuan,WeimingZhang,andNenghaiYu.Hairclip:Designyourhairbytextandreferenceimage.arXivpreprintarXiv:2112.05142,2021.
4.OmerTov,YuvalAlaluf,YotamNitzan,OrPatashnik,andDanielCohen-Or.Designinganencoderforstyleganimagemanipulation.ACMTransactionsonGraphics,2021.
5.JunFu,JingLiu,HaijieTian,YongLi,YongjunBao,ZhiweiFang,andHanqingLu.Dualattentionnetworkforscenesegmentation.InIEEE/CVFConferenceonComputerVisionandPatternRecognition,2019.