
Kimi如何避免服务宕机?郑纬民院士揭秘:以存换算
2024-12-12 15:44:30 - 新浪科技
新浪科技讯12月12日下午消息,在2024大模型技术与应用创新论坛上,中国工程院院士、清华大学计算机系教授郑纬民在分享中提及了月之暗面kimi对话AI产品避免大量用户涌入导致服务宕机背后的技术原理——以存换算。
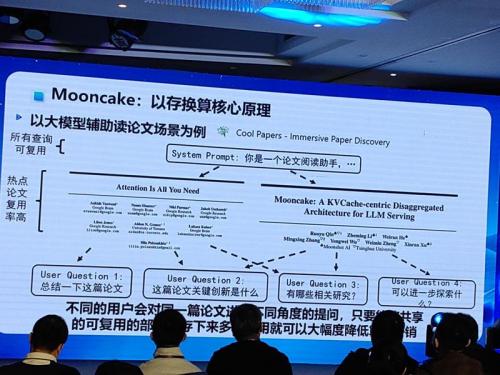
据郑纬民介绍,保障kimi对话AI流畅运行背后的大模型推理框架,名为Mooncake,是一项叫做清华大学与月之暗面共同研发的推理系统方案。
郑纬民指出,Kimi研发遵循的基本原则是:数据更多、模型更大、更长的上下文窗口,肯定会带来更好的效果。因为kimi支持200万字的上下文,效果很好,很多人都喜欢用它。
但是,在Kimi推出初期,遇到访问过大服务宕机采用的应对策略便是买算力卡,但买了五次卡还是死机,并不能彻底解决问题。其背后的原因是,更高的推理负载意味着要买更多的推理卡,但推理卡多了存储器也会不够,用的人多了,问题也就大了。
据郑纬民介绍,最后月之暗面与清华大学开发了Mooncake技术框架,通过将不同用户与Kimi对话的公共内容提炼出来,存储下来,遇到下次用户再提问的时候直接读取回复,减少了每次用户提问都要重新生成的过程,节省了许多算力卡,之后Mooncake就没有再死过机。
“把存储器好好用,也可以省很多卡。”郑纬民表示。(文猛)