
AI 计算时代,为何Arm CPU依然是基石?
在人工智能(AI)时代,AI芯片大厂英伟达的GPU成为了最强抢手的芯片,也让英伟达一跃成为了全球市值最高的企业。英伟达CEO黄仁勋曾多次公开表示,全球公司正在从基于CPU的通用计算向基于GPU的加速计算和生成式AI过渡。然而,不管计算领域的潮流如何更迭,不可否认的是,CPU依然是这个AI加速计算时代的发展基石。

在2024年11月21日于深圳召开的“ArmTechSymposia年度技术大会”上,Arm终端事业部产品管理副总裁JamesMcNiven也指出,“无论是现在还是未来,ArmCPU都将是AI运行的基石,同时结合Arm面向基础设施、汽车、终端等多个市场推出的Arm计算子系统(CSS),以及强大的Arm生态优势,Arm已成功转型为面向未来的应用广泛且至关重要的计算平台技术提供商。”
AI时代,CPU为何依然是基石?
虽然目前在云端AI市场,以英伟达为代表的GPU厂商占据了很大的市场份额,黄仁勋也多次强调,“英伟达将可以利用GPU完全取代传统的基于CPU的数据中心”。但事实上,GPU所能够取代的只是被用于AI计算的CPU,或者说将AI计算负载从CPU上部分卸载下来。
因为对于任何AI基础设施或者AI设备来说,CPU都是最为关键的“大脑”,它具有非常灵活地负责各种类型的通用计算与控制的能力,相比之下GPU更多的还是面向图形计算和AI加速计算,无法替代CPU的通用计算能力。所以,不管是英伟达还是AMD的八张GPU加速卡的服务器,其中都必须搭载2个CPU。即便是的英伟达目前最强的AI芯片GB200当中,也依然集成了其自研的基于Arm架构的GraceCPU。
而目前云端的主流AI加速计算方案也都是基于“CPU+”的模式,比如CPU+FPGA、CPU+GPU、CPU+TPU、CPU+ASIC(包括各类NPU)等。正如前面所说的,CPU是通用计算内核,在负责通用计算与控制的任务的同时,也能够灵活地应对各种类型的AI计算需求,但是效率偏低,因此需要配合其他类型的芯片来提升AI计算的效率。
比如,AISC、TPU针对特定的AI算法计算效率最高,但是也仅仅针对特定的AI算法,灵活性较低;FPGA可编程特性带来了更高的灵活性和计算效率,但是却有着芯片面积、功耗、成本等方面的缺点;相比较而言GPU在AI计算效率、灵活性等方面的比较均衡,但随着云端GPU的成本的越来越高昂;此外,AI加速计算的需求也开始更多地从训练转向推理,也推动了对于CPU+ASIC或者其他混合式AI加速计算方案的需求增长。但不管怎样,CPU依然是各类AI加速计算方案的核心。
特别是随着生成式AI开始进入到边缘侧的趋势之下,也推动了AI加速计算从云端转向对于成本、功耗、能效、隐私保护更为敏感的边缘侧,CPU对于AI的重要性也更为“凸显”。
比如目前常见智能手机SoC,其内部的AI计算基本都采用的是异构计算的架构,即在利用NPU进行专用AI加速的同时,还将利用CPU、GPU、DSP来协同进行AI计算,因为这样的计算架构能够利用最适合的内核来运行对应的AI算法,可以极大的提升AI计算的能效。
再比如对于一些成本和功耗敏感的物联网设备来说,其内部甚至都没有GPU、NPU等内核,其所有的计算任务可能都将是基于CPU来做的,同样对于AI的计算也需要依托于CPU来完成。
虽然目前在云端AI计算市场主要由英特尔、AMD的CPU,以及英伟达GPU所统治,但是Arm也早已经向云端AI计算市场发起挑战,并已经取得了一些成绩。而在边缘侧的AI计算领域,Arm更无疑是最大的“赢家”。

JamesMcNiven透露,截至2025年底,全球将有超过1,000亿台基于Arm架构的设备可具备AI功能,囊括了手机、PC、穿戴设备、汽车、服务器等几乎所有主要类型的AI设备。
面向AI时代,Arm已成为AI计算的基石
早在2021年3月底,Arm就发布了全新的64位指令集Armv9,这是Arm架构十年来最大的一次版本升级,带来了AI和安全等方面的全面升级。
具体来说,Armv9升级了SVE2指令集,可以支持从128位扩展至2048位的矢量计算,显著增强了处理器对矢量计算的支持,这对于需要大量矩阵运算的AI和机器学习应用来说,将带来极大的性能提升。
同时,Armv9还通过优化机器学习指令集,提升了机器学习的处理能力。Armv9还推出了CCA机密计算机体系架构,引入动态域技术,增强了系统安全性,保护数据不会轻易被破解和攻击,进一步提升了AI应用的安全性。
此外,Armv9还具有极高的可扩展性,使得它能够广泛应用于从智能终端设备到大型数据中心的各种计算场景。
可以说,Armv9从设计之初,面向的就是未来AI时代的计算需求。
JamesMcNiven表示:“Armv9专为人工智能打造,将引领Arm计算平台迈入下一个辉煌的10年。得益于SVE2指令集、伸缩矩阵扩展(SME)、CCA等关键技术,Armv9不仅能带来卓越的性能、安全性、可扩展性,还能在生态系统内实现无缝迁移,进而带来更加出色的整体效能。”

谈到Armv9如何面向多元化的应用场景,为客户提供更具创新性、差异化的解决方案,JamesMcNiven进一步解释称,“在人工智能领域我们也意识到异构计算是必要的,意味着我们需要灵活调配计算资源,这就是Arm的优势所在。我们一直在CPU、GPU、NPU当中添加人工智能的能力,能够实现灵活的组合,但这还远远不够。对于Arm的计算平台来说,我们不再是简单的将这些模块堆砌在一起,我们将其做成一个整合的完整的解决方案为大家带来更多价值,我们称之为Arm计算子系统(CSS)。”
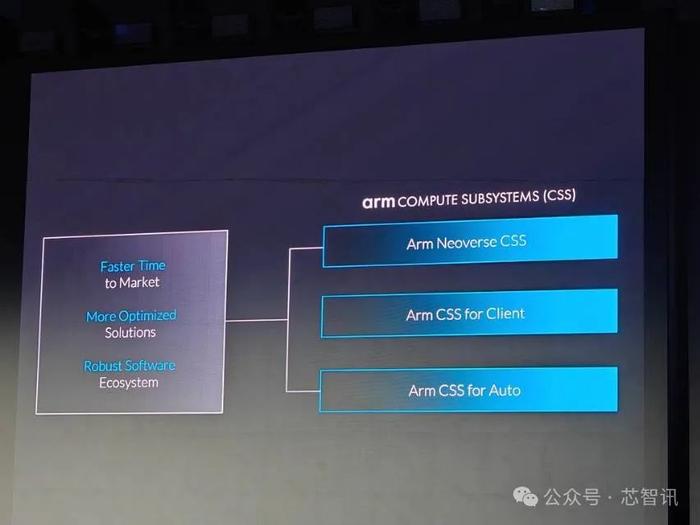
近几年来,Arm也已经面向基础设施、终端等多个市场推出了Arm计算子系统(CSS),旨在提高前沿AI体验的性能、效率和可访问性,帮助生态系统合作伙伴更轻松、更快速地打造自己的芯片解决方案。使得Arm作为计算平台不仅仅惠及单一领域,而是能够服务于整个生态体系。
目前众多芯片设计厂商基于Arm架构的处理器正在数据中心基础设施市场、智能手机、AIPC、智能汽车等边缘设备的AI方面发挥至关重要的“基石”性作用。
比如在数据中心(服务器)市场,近年来亚马逊云科技(Graviton系列)、阿里巴巴(倚天系列)、微软(Cobalt100)、谷歌(Axion系列)、华为(鲲鹏系列)等头部的云服务厂商都推出了自研的服务器CPU,同时也有像Ampere等第三方的服务器CPU厂商,均推出了基于ArmCPU架构的产品。
为了助力Arm服务器CPU厂商的设计,Arm在2023年10月还整合了特殊应用IC(ASIC)设计公司、IP供应商、电子设计自动化(EDA)工具供应商、晶圆厂与固件开发商等业界领导企业资源,推出了“Arm全面设计”(ArmTotalDesign),致力于加速并简化NeoverseCSS构架系统的开发,协助各方进行创新、加速产品上市时程,并降低打造客制化芯片所需的成本与阻力。今年6月,联发科就有宣布加入Arm全面设计(ArmTotalDesign)生态项目,不排除联发科也可能基于Arm架构开发服务器CPU。截至今年10月,参与Arm全面设计的企业已迅速成长至30家,并已经开始加速基于NeoverseN系列或V系列CSS的测试芯片与小芯片产品的开发。
在智能手机市场,Arm是当之无愧的霸主。目前几乎所有的智能手机SoC都是基于ArmCPU架构(包括苹果A系列处理器和高通骁龙处理器),并且绝大多数的智能手机SoC还采用了ArmGPU和互连技术。同时,在ArmPC市场,得益于Arm指令集所带来的高性能、低功耗能力的加持,苹果的M系列处理器大获成功,并实现在Mac产品上对于英特尔处理器的全面替代;同样,高通去年推出的全新AIPC处理器——骁龙X系列也是基于Arm指令集架构的。
今年5月底,Arm还发布了首款面向智能手机和PC等终端产品的Arm计算子系统——终端CSS,带来了最新的Armv9.2指令集的CPU集群,加入了对于SVE、SVE2指令的支持,包括最高性能的Cortex-X925CPU、最高效的Cortex-A725CPU、更新后的ArmCortex-A520CPU,此外还带来了性能最高、效率最高的GPU——ArmImmortalis-G925GPU等。
联发科最新推出的天玑9400旗舰移动平台就是搭载ArmCortex-X925和Immortalis-G925,为其第二代全大核架构、游戏性能及生成式AI体验的提升提供了全面的助力。联发科天玑9400已被包括vivo、OPPO、Redmi等品牌厂商的旗舰手机所采用。
在汽车市场,全球15家顶级汽车芯片制造商均已授权使用ArmIP。100%的高级驾驶辅助系统(ADAS)芯片供应商正在基于Arm技术开发其下一代芯片。85%的车载信息娱乐系统(IVI)采用Arm技术。据了解,Arm还将于2015年推出汽车计算子系统。
总结来说,经过多年的发展,目前Arm已经成为了数据中心、智能手机、AIPC、智能汽车、物联网等众多行业发展的关键基石。特别是随着Arm转型为计算平台技术提供商,凭借业界领先的高能效、低功耗技术创新,Arm也已经成为了最普及的AI计算的基石。
面对AI带来的巨大市场机遇,Arm认为中国市场将是重中之重。JamesMcNiven在此次大会上也指出:“我们相信中国的创新正在引领全球人工智能的变革,因为中国是全球最大的智能手机和智能汽车市场。”据市场预测,在汽车领域,到2026年L3级的自动驾驶车辆将会超过百万辆,而在今年年底将会有1.7亿台手机得到人工智能的加持。同时,AIPC的市占率也将超越55%,以AI为主的数据中心增长达到了5倍。预计到2032年,中国的人工智能市场规模将达到1.1万亿。
多元且强大的软件生态系统:持续推动软硬件在AI应用的协同创新
高效、节能的硬件IP是Arm的一大关键优势,但是相对于其他处理器架构来说,Arm所拥有的庞大的跨平台软件应用生态也是另一大关键优势。凭借多年来在ArmCPU平台上进行的大量的软件开发经验,Arm打造了一整套的统一的开发工具链,全面覆盖了云、边、端等应用生态,开发者可以一次学习,即可快速复用到其他领域。
比如,为了加速开发者开发基于Arm架构的处理器的AI应用的开发,Arm今年还推出了全新的KleidiAI软件库,具有高度优化的机器学习(ML)内核的集合,使开发人员能够在通过高度优化的生成式AI框架运行AI工作负载时释放ArmCPU的全部潜力。目前KleidiAI已经用于PyTorch、MediaPipe和MetaLlama3的开发。在此次ArmTechSymposia年度技术大会上,Arm还宣布KleidiAI已经和腾讯混元模型集成,为端侧AI的开发性能提供支持。
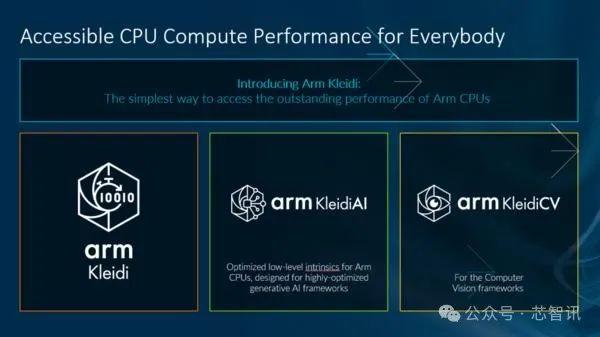
可以说,ArmKleidiAI软件库为软件开发者带来充分利用硬件性能的能力,大幅简化人工智能的开发。

以上种种,无不体现出Arm通过全面的软件生态系统支持开发者和企业的创新实践,并在面向AI的软硬件协同中所扮演的关键角色。据Arm介绍,目前全球有2,000多万名软件开发者在基于Arm架构的设备上构建应用。这也意味着更多的设备、行业和用例可以享受到在Arm平台上运行的能效优势、卓越性能以及加速开发的助益。
小结:
经过多年来持续的技术创新和产品迭代,从边缘设备上运行工作负载的小型传感器,到用于训练大型语言模型(LLM)的复杂工作负载的大型服务器,ArmCPU已经几乎“无处不在”。特别是随着AI时代的到来,凭借在性能和能效之间的完美平衡,ArmCPU也在根本上推动了AI的变革,并将在未来几十年持续占据不断扩展的AI生态系统的核心地位。
编辑:芯智讯-浪客剑