
华为云重磅发布盘古大模型5.0,全系列、多模态、强思维全面升级,大模型行业落地也在加速
转自:周到上海
6月21日,华为开发者大会2024(HDC2024)正式揭幕,华为常务董事、华为云CEO张平安重磅发布盘古大模型5.0,在全系列、多模态、强思维三个方面全新升级。盘古5.0推出适配不同业务场景多种规格模型,并与物理世界结合,加速大模型行业落地。
盘古大模型5.0包含不同参数规格的模型,以适配不同的业务场景。十亿级参数的PanguE系列可支撑手机、PC等端侧的智能应用;百亿级参数的PanguP系列,适用于低时延、低成本的推理场景;千亿级参数的PanguU系列适用于处理复杂任务,可以成为企业通用大模型的底座;万亿级参数的PanguS系列超级大模型是处理跨领域多任务的超级大模型够能帮助企业更好的在全场景应用AI技术。
盘古大模型5.0能够更好更精准地理解物理世界,包括文本、图片、视频、雷达、红外、遥感等更多模态。在生成方面,盘古5.0,可以生成符合物理世界规律的多模态内容,让创新随心所欲。
复杂逻辑推理是大模型成为行业助手的关键。盘古大模型5.0将思维链技术与策略搜索技术深度结合,极大提升了数学能力、复杂任务规划能力。
开发者大会(HDC2024)上,华为云正式推出了盘古具身智能大模型,会上,搭载盘古能力的人形机器人也同步亮相。
盘古大模型能够让机器人完成10步以上的复杂任务规划,并且在任务执行中实现多场景泛化和多任务处理。同时盘古大模型还能生成机器人需要的训练视频,让机器人更快地学习各种复杂场景。
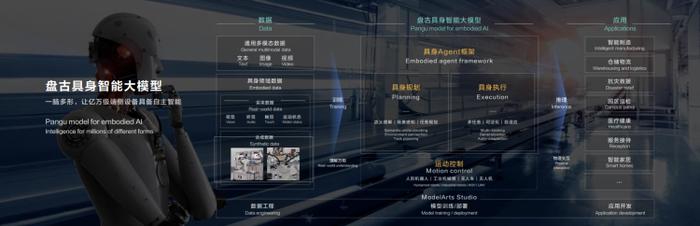
大模型的多模态能力以及思维能力的快速提升,使机器人能够模拟人类常识进行逻辑推理,并在现实环境中高效精准地执行任务,从而有效解决了复杂环境感知与物理空间认知的难题。通过集成多场景泛化和多任务处理能力,盘古模型赋予机器人前所未有的适应性和灵活性,无论是面对工业环境还是家庭生活场景,都能游刃有余。
会上,乐聚人形机器人夸父通过识别物品、问答互动、击掌、递水等互动演示,直观展示了双方基于盘古大模型的合作成果。通过模仿学习策略,华为云与乐聚公司显著提升了人形机器人的双臂操作能力,实现了软硬件层面的协同优化,不仅增强了机器人综合性能,还克服了小样本数据训练的局限性,推动了泛化操作能力的边界。
张平安在大会上表示,除了人形机器人,盘古具身智能大模型还可以赋能多种形态的工业机器人和服务机器人,让它们帮助人类去从事危险和繁重的工作。
“正如大家所期望的,让AI机器人帮助我们去洗衣、做饭、扫地,让我们有更多的时间去看书,写诗,作画。”张平安表示。
此次开发者大会,华为云推出了盘古媒体大模型,通过在语音生成、视频生成和AI翻译三方面的技术创新,重塑了内容生产和应用的新模式。
盘古媒体大模型在视频生成方面取得了显著成果。通过盘古,可以将实拍视频转换为不同风格的高清动漫。在现场演示的生成视频中,演员的舞蹈、武打等大运动轨迹能保持一致视觉效果,角色的面貌特征也保持前后一致。这一技术的突破,为视频制作领域带来了全新的可能性,也大大提升视频制作效率,作品一次拍摄多元化制作,实现价值最大化。
在语音生成方面,盘古大模型通过AI原声译制与视频生成能力,实现了将原片译制成不同语言的视频,并保留原始角色的音色、情感和语气。更为重要的是,盘古还能同步生成新的口型,确保不同语言对应的口型一致,使得跨语言沟通更加自然流畅。
此外,在AI翻译方面,华为云盘古大模型也对云会议系统进行了升级。通过基于大模型的语音复刻、AI文字翻译以及TTS技术,实现了语音的同声传译。这使得不同国家的人在云视频会议中可以畅快地使用母语交流。结合数字人技术,在不方便开摄像头时,用户还可以通过数字人参会,并通过口型驱动实现数字人以各种语言说话都能精准匹配口型,如同本人说话一般。这一技术的应用,将为全球用户提供更加便捷、高效的跨语言沟通体验。
张平安强调,一直以来,华为云盘古大模型都坚定的聚焦行业,在解难题、做难事的道路上不断攻坚克难,砥砺前行,重塑千行万业。华为云将与所有的客户、伙伴和开发者一起,创新不止,攀登不止,让云无处不在,让智能无所不及,加速千行万业的智能升级。
在过去的一年中,盘古大模型持续深耕行业,已在30多个行业、400多个场景中落地,在政务、金融、制造、医药研发、煤矿、钢铁、铁路、自动驾驶、工业设计、建筑设计、气象等领域发挥着巨大价值。
来源:周到上海 作者:苗夏丽