
斯坦福大模型评测榜 Claude 3 排名第一,阿里 Qwen2、零一万物 Yi Large 国产模型进入前十
IT之家6月22日消息,斯坦福大学基础模型研究中心(CRFM)6月11日发布了大规模多任务语言理解能力评估(MassiveMultitaskLanguageUnderstandingonHELM)排行榜,其中综合排名前十的大语言模型中有两款来自中国厂商,分别是阿里巴巴的Qwen2Instruct(72B)和零一万物的YiLarge(Preview)。
据悉大规模多任务语言理解能力评估(MMLUonHELM)采用了DanHendrycks等人提出的一种测试方法,用于衡量文本模型在多任务学习中的准确性。这个测试内容包括基础数学、美国历史、计算机科学、法律等领域的57个任务。要在这个测试中获得高分,模型必须具备广泛的世界知识和解决问题的能力。IT之家附排名如下:
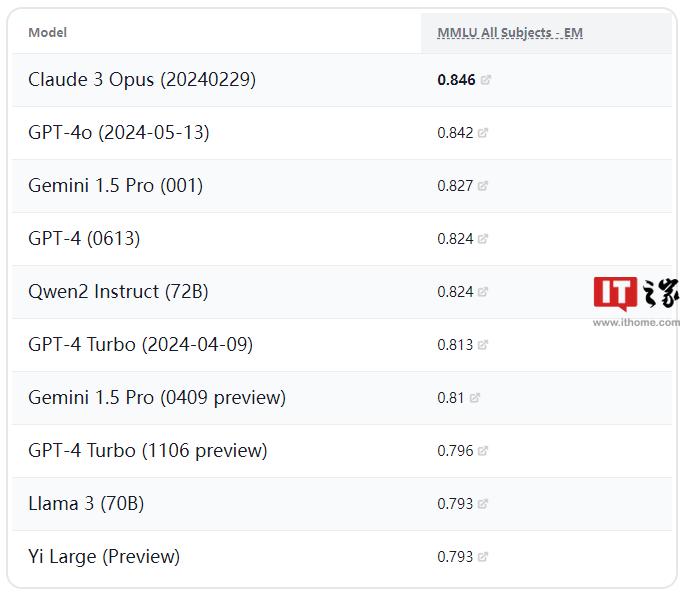
1、Claude3Opus(20240229):Anthropic(美国,亚马逊投资)
2、GPT-4o(2024-05-13):OpenAI(美国)
3、Gemini1.5Pro:谷歌(美国)
4、GPT-4(0613):OpenAI(美国)
5、Qwen2Instruct(72B):阿里巴巴(中国)
6、GPT-4Turbo(2024-04-09):OpenAI(美国)
7、Gemini1.5Pro(0409preview):谷歌(美国)
8、GPT-4Turbo(1106preview):OpenAI(美国)
9、Llama3(70B):Meta(美国)
10、YiLarge(Preview):零一万物(中国)
Qwen2是由阿里巴巴开发的一款开源大语言模型,发布于今年6月6日。Qwen2系列包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B在内的五个不同规模的预训练及指令微调模型;支持除英语和中文外的额外27种语言的数据训练;Qwen2-7B-Instruct和Qwen2-72B-Instruct支持长128K个token的上下文。
YiLarge是由零一万物公司开发的一款闭源大模型,Yi模型系列基于6B和34B预训练语言模型,然后扩展到聊天模型、200K长上下文模型、深度升级模型和视觉语言模型。官方宣称“其在关键基准测试分数上优于GPT-4和Claude3Opus等领先模型”。
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。