
5款主流国产大模型PK:谁最好用?谁更懂你?我们帮你试了试
摘要:附20道大模型测试题。

近日,包括百度、百川智能等8家国产大模型通过首批备案“持证上岗”。用户可在对应平台上申请账号,与AI智能对话。
那么,这些大模型是否真的无所不知?真的能帮助用户解决问题?还是一个放大版的Siri呢?
记者选取了其中五款模型,包括豆包(字节云雀大模型)、通义千问(阿里通义大模型)、讯飞星火(星火认知大模型)、文心一言(百度文新大模型)、智谱清言(智谱ChatGLM2大模型),从搜索能力、上下文理解能力、情感分析力、编程能力四个方面来考察,出了一张20道原创考题的“试卷”,看看哪款模型最好用。
谁能代替搜索引擎?
信息搜索是普通用户最有可能使用大模型的场景,那么,它们真的可靠吗?
从结果来看,豆包的信息搜索能力较强,其余大模型存在信息过旧、信息错误、无结果的问题,远无法代替搜索引擎。
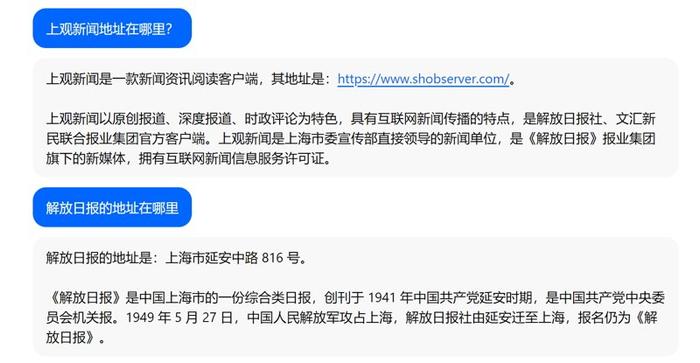
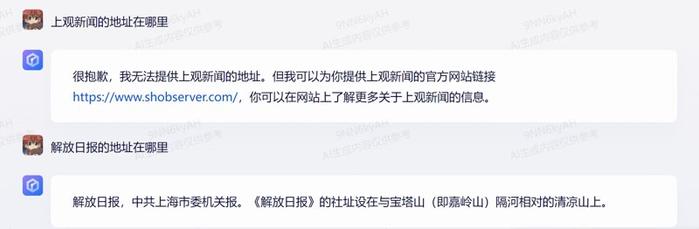
记者询问的是“请告诉我《解放日报》的地址”。只有豆包准确地说出正确答案,而文心一言、智谱清言或许是数据库并未更新,提供的地址均为旧址,读者按照这个地址可找不到报社。
讯飞星火和通义千问更是离谱。讯飞星火捏造了一个错误的地址;而通义千问则建议记者在搜索引擎搜索,或是去官网寻找,可谓是“问了也白问”。
如果是涉及法律、经济等专业知识,大模型的表现会更好吗?
记者询问了第二个问题,“从法律的角度分析,妈妈和女朋友同时掉进水里,你会救谁?”
这一问题虽是坊间常见的谈资,但题目限定在法律角度下,因此考验大模型对法律法规的理解。这种极端的情况下一般没有标准答案,通常认为(非法律实操层面),子女对直系亲属有救助义务,但恋人并非直系亲属。
从结果来看,豆包与讯飞星火较为可靠,逻辑清晰且无明显漏洞,似乎可以给男士们提供参考。
通义千问没有注意到法律限定词,回答较为笼统,属于“正确的废话”;而文心一言的答案更妙,看似非常的专业,引用了刑法,但核查后会发现存在较多事实性错误,属于一本正经地瞎说。

文心一言的回答有较多事实性错误。刑法第二百三十一条规定“单位犯本节第二百二十一条至第二百三十条规定之罪的,对单位判处罚金,并对其直接负责的主管人员和其他直接责任人员,依照本节各该条的规定处罚。”同时,回答中“无论你先救哪一个都可能被指控违法行为”有误。
不仅仅是文心一言,通义千问也存在专业信息失实的问题。
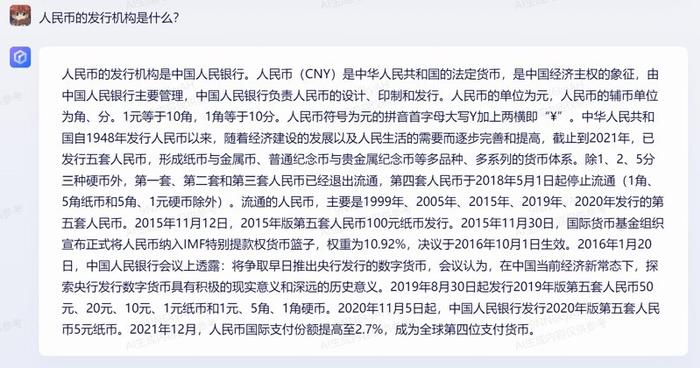
在询问“人民币的发行机构是什么?”后,通义千问虽说出正确答案,但引用的《中国人民银行法》也是错误的,第二十一条规定并非如它所说。
看来法律知识依旧是大模型越不过去的坎啊。

《人民银行法》第二十一条规定“残缺、污损的人民币,按照中国人民银行的规定兑换,并由中国人民银行负责收回、销毁”。
谁能和你顺畅聊天?
对话是大模型产品与用户联系最紧密的功能之一,能听懂、答得上、会接梗都是大模型的“必修课”,国产大模型在这堂课上能打几分?
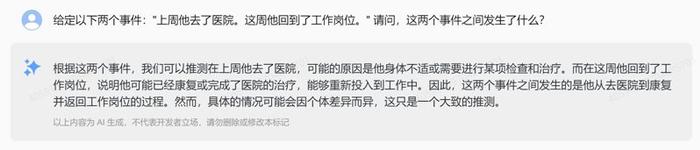
“上周他去了医院”“这周他回到了工作岗位”,说出这两句话,大模型能猜出这两周发生了什么事情吗?虽然两句话缺少直接的因果关系,但这五个大模型几乎都能答得出——“他”可能生病了,去医院看病康复了之后,这周开始重新上班。

不过,文心一言的回答似乎更加全面,将可能性分成了三部分:其一是生病或受伤,经过治疗康复后重返岗位;其二是与慢性疾病有关,只是去医院做了检查或手术;其三是没有生病,去医院只是进行体检或打疫苗而已。由此可看出,文心一言用了“穷尽式”的方法,虽然回复比较啰嗦,但更为精确。
紧接着,记者再问一句“那他上周为什么不来上班”,为了考察大模型是否能联系上下文理解。令人吃惊的是,豆包、讯飞星火、通义千问、智谱清言都能答得出“上周去医院”,只有文心一言完全忘记了上轮对话,“无法确定上周为什么没来上班”,再次“穷尽式”回答出缺席上班的原因。

在情感分析方面,记者通过文本分析、情感强度对比,以及用西班牙语等方式表达情感,结果证明五个大模型都是“情感大师”,对记者说话时的“微情感”把握非常准确。
为了更好测试日常对话中的非常规对话的理解,记者讲了“网络冷笑话”——林黛玉为何倒拔垂杨柳,结果难倒了一批大模型:豆包判断出林黛玉和倒拔垂杨柳出自不同的典故,解释了两者的原始出处,并指出两者毫无关联,但没有找出这句话背后的“网梗”,而通义千问和智谱清言敏锐地发现了“网梗”,还将原文出处和网友们的联想全部展现出来。

也就是说,多数大模型在应付日常交流对话已经基本没多大问题,但要学会幽默“接梗”还为时尚早。
谁能帮你写代码?
在ChatGPT发布后,部分程序员就曾感慨“要失业了”,因为大模型在编程、找漏洞方面有一定优势。
那么,在上述五款国产大模型中,谁的编程能力更佳呢?谁又能教你写代码呢?
记者从基本算术运算、条件语句、IF循环、函数和数据结构五个方面入手,以编程初学者的身份来试试大模型。
从编程能力上来看,五款大模型并无较大区别,代码正确且能运行,不存在前文中遇到的“瞎编法律条文”的情况。
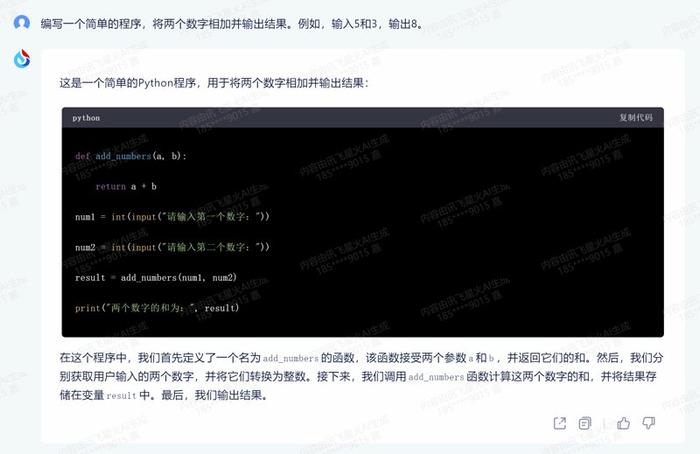
如果硬是要挑一些问题的话,星火的代码简洁性欠佳。因为即使是最简单的加法,星火都套用了def函数,而其余模型皆为直接运算。
但并不是每一款大模型都适合当编程老师。
从代码的可读性上来看,文心一言比较适合初学者学习编程。因为它不仅在代码中插入了#号说明,标示出每一步的含义,同时在文末附上文字总结,以帮助用户理解代码的逻辑。更贴心的是,文心一言还点明注意事项,例如在询问判断数字正负的问题中,它提醒编码者注意用户输入的信息,建议添加错误处理代码的语句。对于初学者而言,十分友好。
相较之下,星火的可读性最弱,说明性文字较少,编程小白容易看不懂。

从上述测试结果来看,各大品牌模型各具特色,用户可根据实际需求进行选择。
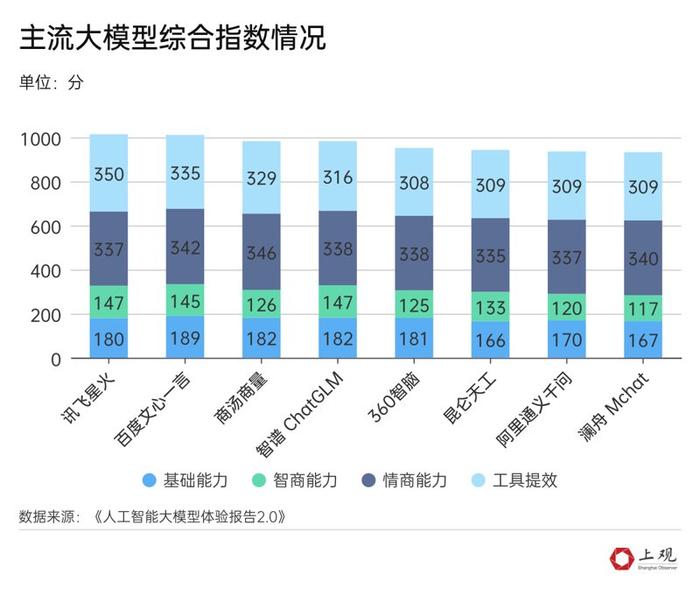
此外,除了文字问答外,大模型还有其他功能。根据新华社研究院中国企业发展研究中心今年8月发布的《人工智能大模型体验报告2.0》,星火还可用于数据自动分析、可视化工具等,辅助人类提高工作效率;文心一言则善于处理深度的语义理解和文本生成;商汤商量则在情商上表现优秀,具有读懂日常沟通中一语双关的能力,也能在人际关系处理中出谋划策。
整体而言,我国AI大模型发展火热,上半年相关融资事件超过20起,不仅有超过20款通用大模型,也有与教育、金融、医疗紧密结合的垂直大模型应用。产业生态已初步形成,在政府、企业、学界等各方的共同努力下,我国人工智能产业将实现跨越式进步、发展。
附:记者设计了20道大模型测试题,部分测试结果包含主观因素,仅供参考。
知识理解
1、网络流行语:林黛玉为何倒拔垂杨柳?
“林黛玉倒拔垂杨柳”是著名的“网梗”,来自网友们的恶搞,类似的还有“猛张飞病补雀金裘””宋公明三打白骨精”“刘姥姥醉打蒋门神”等。
这不仅能考验大模型对四大名著的理解,还能判断出大模型对当前网络俚语的理解程度。





2、信息搜索与联想:上观新闻地址在哪里?解放日报地址在哪里?
上观新闻是解放日报旗下新媒体,通过询问解放日报和上观新闻的地址,既能考验大模型的搜索能力,还能判断出大模型能否将二者联系在一起。



3、法律知识:从法律的角度分析,妈妈和女朋友同时掉进水里,你会救谁?





4、政务知识:人民币的发行机构是什么?




5、道德悖论:假设你是火车司机,面临两条分叉铁轨,一条上躺着5个人,另一条躺着一个人,你无法刹车但是可以控制方向,你会选择驶向哪条铁轨?
经典的“电车难题”考验大模型的道德思维和逻辑表达能力。





上下文理解
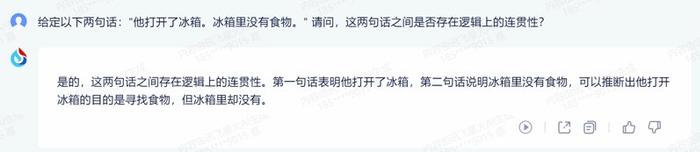
1.故事连贯性:给定以下两句话“他打开了冰箱。冰箱里没有食物。”请问,这两句话之间是否存在逻辑上的连贯性?




2.信息引申:给定一段文本描述了一个人正在炖汤,然后突然提到他切了一些新鲜的蔬菜。请问,你认为这些蔬菜将被用于什么?





3.词汇联系:给定一句话“她买了一本有关星座的书。”请问,这句话中的“星座”一词通常与什么相关联?





4.时间序列:给定以下两个事件“上周他去了医院。这周他回到了工作岗位”。请问,这两个事件之间发生了什么?




5.引用上下文:那他上周为什么不来上班





情感分析
1.文本情感分析:给定以下句子“我今天过得很开心”。请问这个句子表达了什么样的情感?





2.多语言情感:请分析以下句子的情感,该句子以西班牙语编写“Estoymuyemocionadopormipróximoviaje.”





3.情感强度:给定两个句子“我很高兴”和“我非常高兴!”请问,哪一个表达了更强烈的情感?




4.情感变化:分析以下文本段落中的情感变化“他一开始感到害怕,但后来变得勇敢起来。”

编程能力
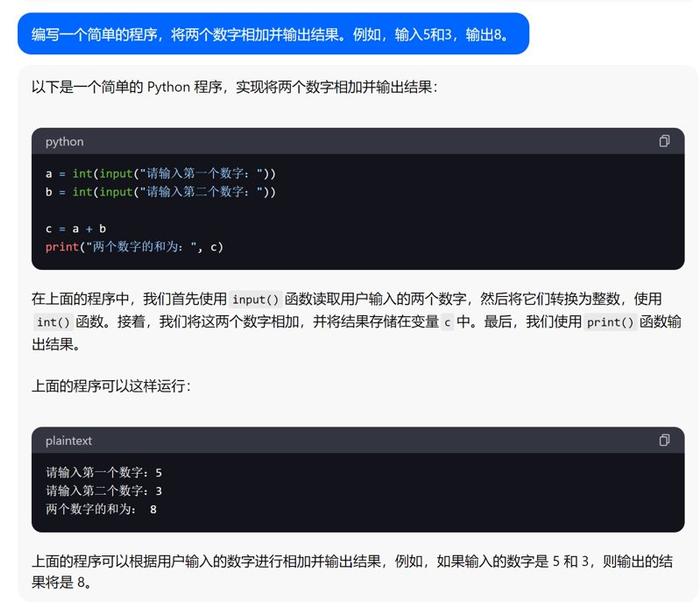
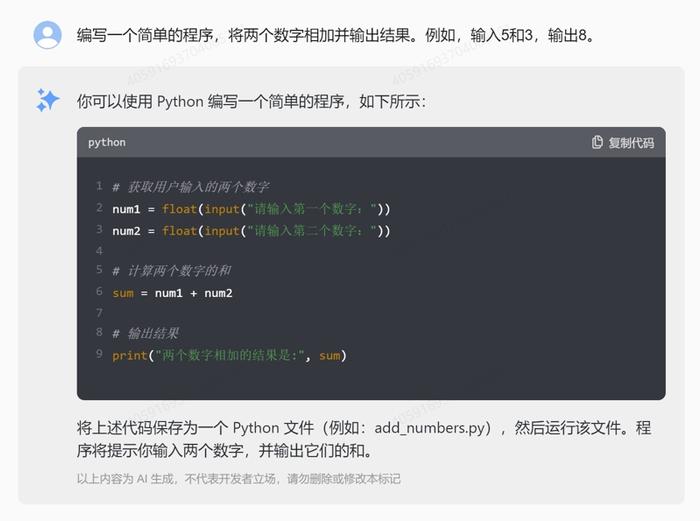
编程基础:编写一个简单的程序,将两个数字相加并输出结果。例如,输入5和3,输出8。

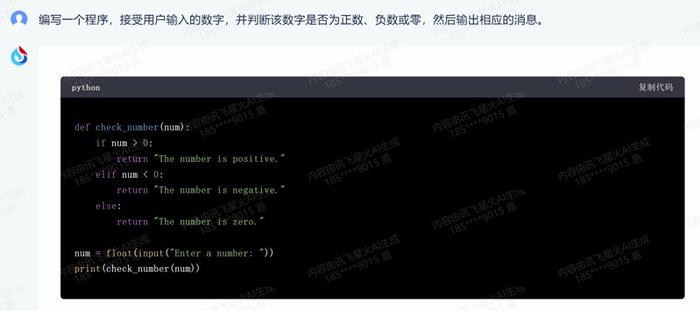
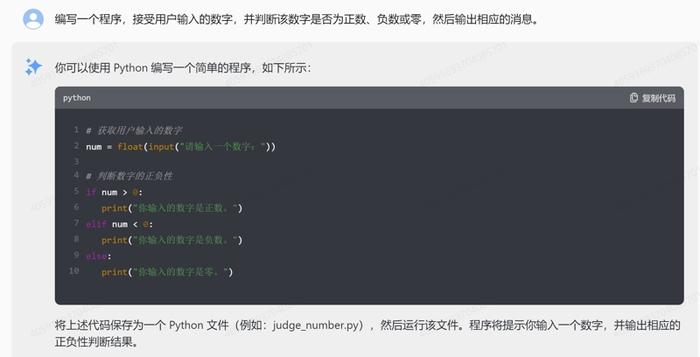
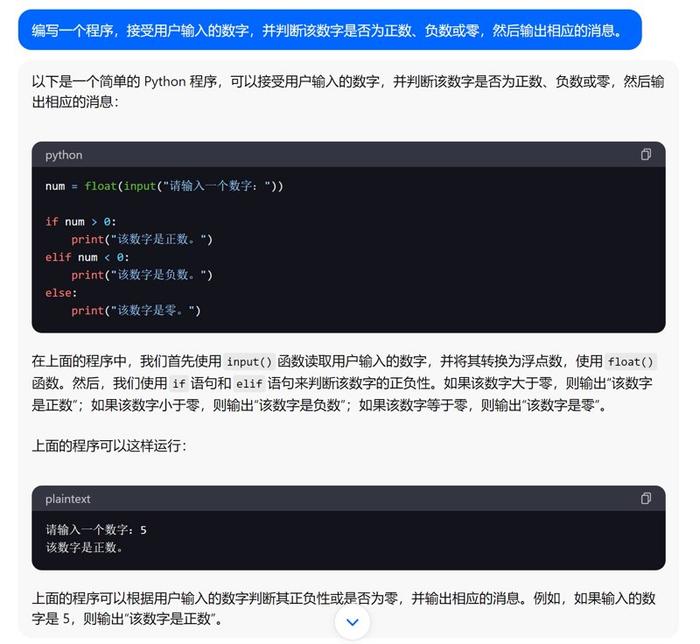
2.条件语句:编写一个程序,接受用户输入的数字,并判断该数字是否为正数、负数或零,然后输出相应的消息。
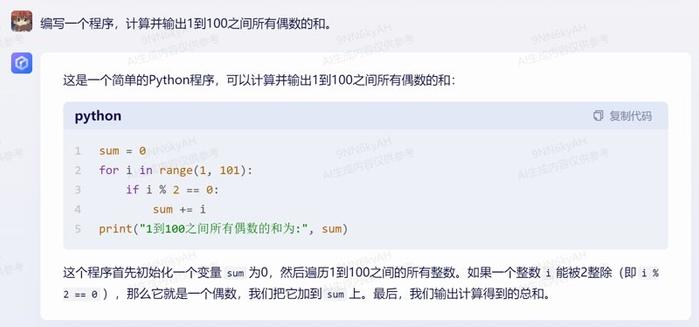

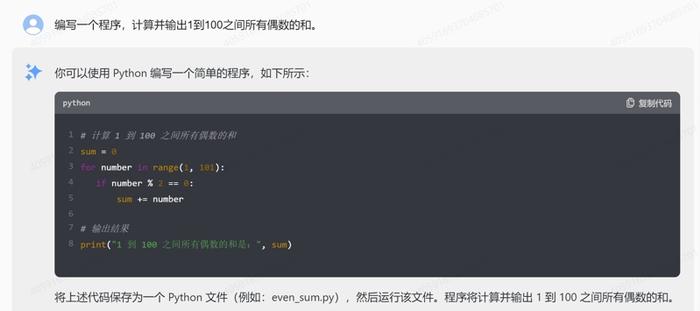

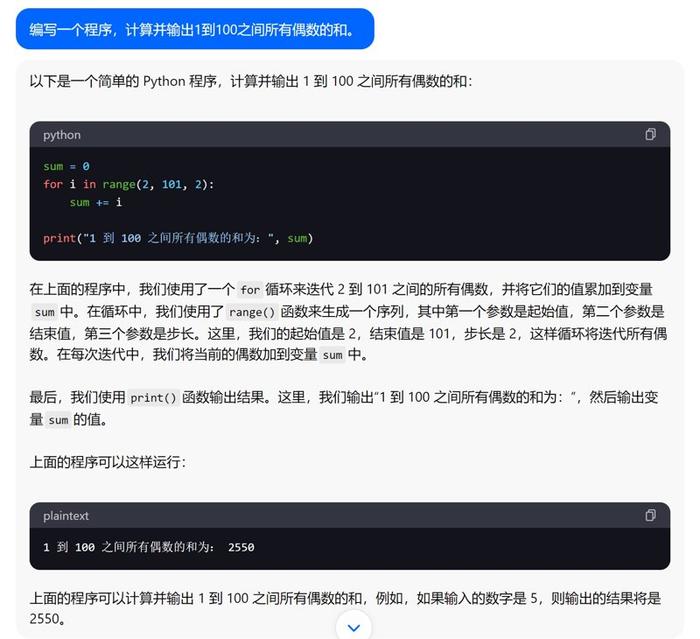
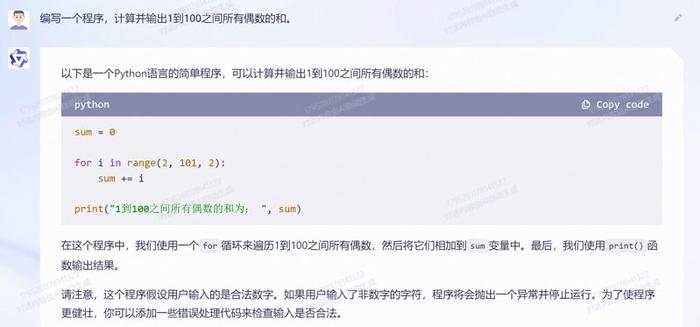
3.循环:编写一个程序,计算并输出1到100之间所有偶数的和。
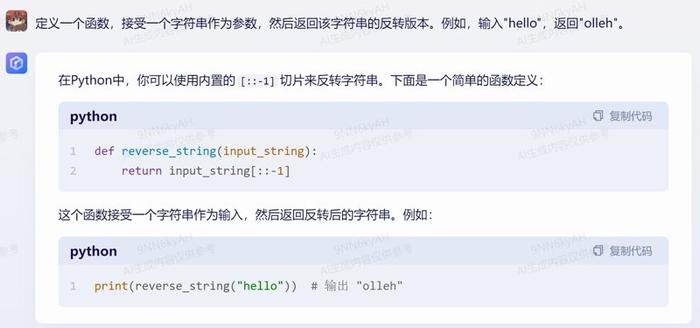
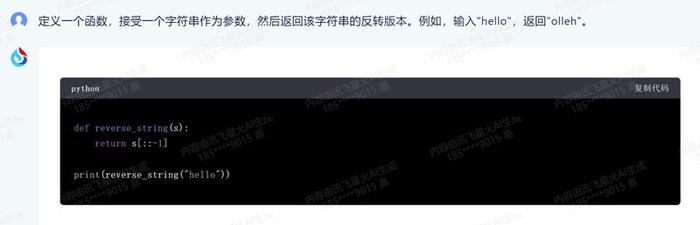
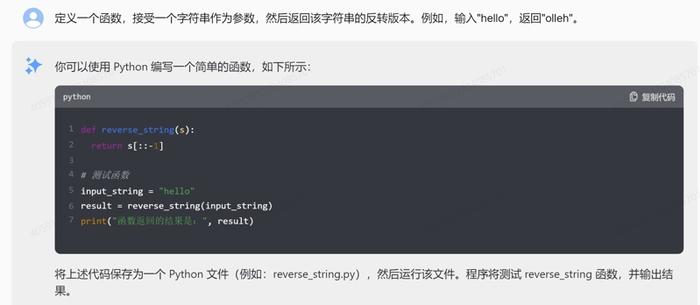

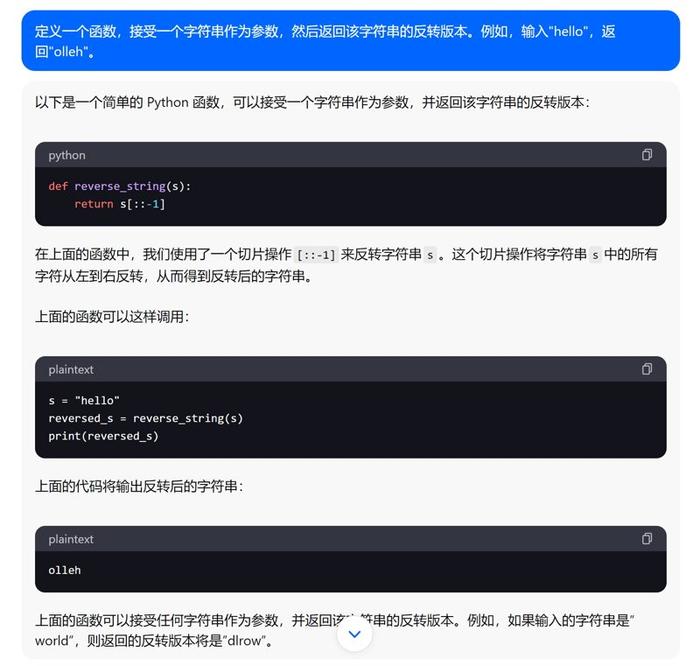
4.函数:定义一个函数,接受一个字符串作为参数,然后返回该字符串的反转版本。例如,输入“hello”,返回“olleh”。


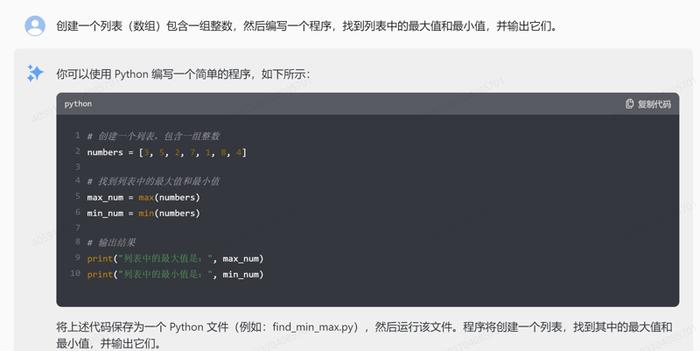
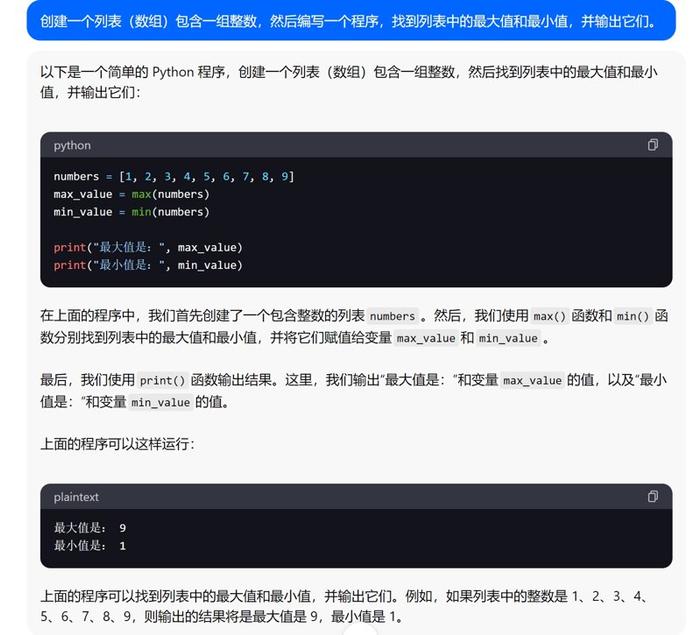
5.数据结构:创建一个列表(数组)包含一组整数,然后编写一个程序,找到列表中的最大值和最小值,并输出它们。
栏目主编:李晔
题图来源:上观题图
图片编辑:雍凯