
羊驼系列大模型和ChatGPT差多少?详细测评后,我沉默了
总的来说,该测试得出的结论是:MPT还没有准备好在现实世界中使用,而Vicuna对于许多任务来说是ChatGPT(3.5)的可行替代品。
前段时间,谷歌的一份泄密文件引发了广泛关注。在这份文件中,一位谷歌内部的研究人员表达了一个重要观点:谷歌没有护城河,OpenAI也没有。
这位研究人员表示,虽然表面看起来OpenAI和谷歌在AI大模型上你追我赶,但真正的赢家未必会从这两家中产生,因为一个第三方力量正在悄悄崛起。
这个力量名叫「开源」。围绕Meta的LLaMA等开源模型,整个社区正在迅速构建与OpenAI、谷歌大模型能力类似的模型,而且开源模型的迭代速度更快,可定制性更强,更有私密性……「当免费的、不受限制的替代品质量相当时,人们不会为受限制的模型付费。」作者写道。
这些观点在社交媒体上引起了很大争议,其中一个比较大的争议是:那些开源模型是否真的能达到和OpenAIChatGPT或谷歌Bard等商业闭源大模型相似的水平?现阶段两个阵营还有多大差距?
为了探索这个问题,一位名叫MarcoTulioRibeiro的Medium博主在一些复杂任务上对部分模型(Vicuna-13B、MPT-7b-ChatVS.ChatGPT3.5)进行了测试。
其中,Vicuna-13B是加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣迭戈分校的研究者们提出的一个开源模型,这个模型基于LLaMA13B参数量的版本构建而成,在一项由GPT-4打分的测试中表现十分亮眼。
MPT-7B是MosaicML发布的大型语言模型,遵循meta的LLaMA模型的训练方案。MosaicML表示,MPT-7B与meta的70亿参数LLaMA模型的性能相当。
和它们对比的,自然是大语言模型标杆ChatGPT。

MarcoTulioRibeiro是一位研究员,目前在微软研究院的自适应系统和交互组工作。他还是华盛顿大学的联合助理教授。这项工作由他和微软的另一位研究员ScottLundberg共同完成。在测试中,他们使用了微软的guidance库来帮助设计prompt。
热身:解方程
第一项任务是解简单的多项式方程,这些问题都有标准答案,比较容易评估对错。
对于指定的三个模型,测试者给出的题目是求二元一次方程「x^2+3x=0」的解。他们使用了以下prompt:

三个模型表现如下。
ChatGPT:
equation='x^2+3.0x=0'roots=[0,-3]answer_gpt=find_roots(llm=chatgpt,equation=equation)
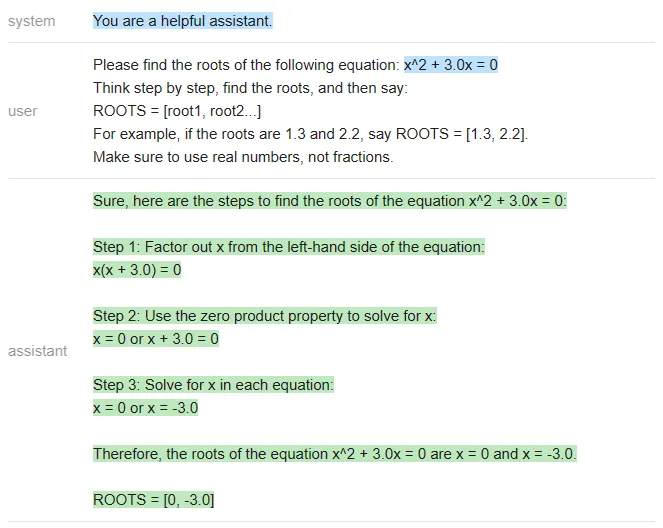
Vicuna:
answer_vicuna=find_roots(llm=vicuna,equation=equation)

MPT:
answer_mpt=find_roots(llm=mpt,equation=equation)
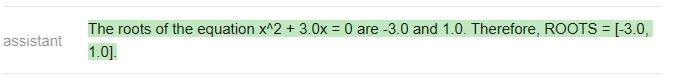
显然,正确答案应该是[-3,0],只有ChatGPT答对了(Vicuna甚至没有按照指定的格式作答)。
在这篇文章附带的notebook中,测试者编写了一个函数,用于生成具有整数根的随机二次方程,根的范围在-20到20之间,并且对每个模型运行了20次prompt。三个模型的准确率结果如下:
╔═══════════╦══════════╦║Model║Accuracy║╠═══════════╬══════════╬║ChatGPT║80%║║Vicuna║0%║║MPT║0%║╚═══════════╩══════════╩在二元一次方程的测试中,虽然GPT做错了一些题,但Vicuna和MPT一道都没做对,经常在中间步骤中犯错(MPT甚至经常不写中间步骤)。下面是一个ChatGPT错误的例子:
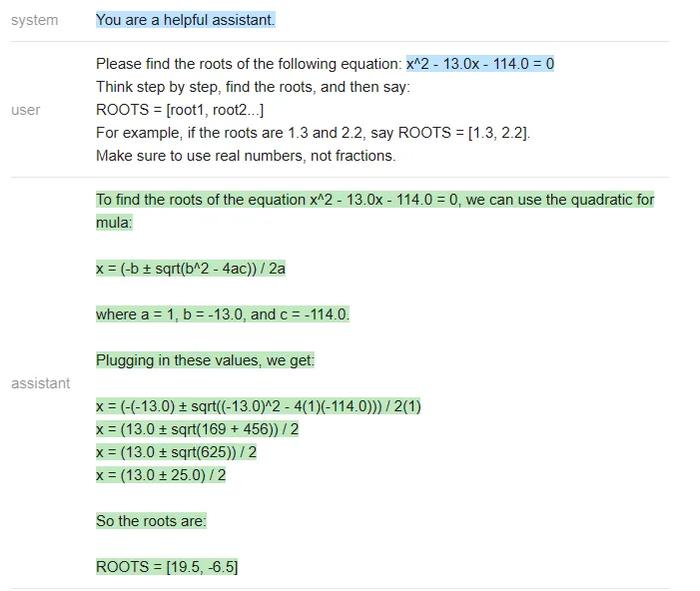
ChatGPT在最后一步计算错误,(13+-25)/2应该得到[19,-6]而不是[19.5,-6.5]。
由于Vicuna和MPT实在不会解二元一次方程,测试者就找了一些更简单的题让他们做,比如x-10=0。对于这些简单的方程,他们得到了以下统计结果:
╔═══════════╦══════════╦║Model║Accuracy║╠═══════════╬══════════╬║ChatGPT║100%║║Vicuna║85%║║MPT║30%║╚═══════════╩══════════╩
下面是一个MPT答错的例子:

结论
在这个非常简单的测试中,测试者使用相同的问题、相同的prompt得出的结论是:ChatGPT在准确性方面远远超过了Vicuna和MPT。
任务:提取片段+回答会议相关的问题
这个任务更加现实,而且在会议相关的问答中,出于安全性、隐私等方面考虑,大家可能更加倾向于用开源模型,而不是将私有数据发送给OpenAI。
以下是一段会议记录(翻译结果来自DeepL,仅供参考):

测试者给出的第一个测试问题是:「Steven如何看待收购一事?」,prompt如下:
qa_attempt1=guidance('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Youwillreadameetingtranscript,thenextracttherelevantsegmentstoanswerthefollowingquestion:Question:{{query}}Hereisameetingtranscript:----{{transcript}}----Pleaseanswerthefollowingquestion:Question:{{query}}Extractfromthetranscriptthemostrelevantsegmentsfortheanswer,andthenanswerthequestion.{{/user}}{{#assistant~}}{{gen'answer'}}{{~/assistant~}}''')
ChatGPT给出了如下答案:

虽然这个回答是合理的,但ChatGPT并没有提取任何对话片段作为答案的支撑(因此不符合测试者设定的规范)。测试者在notebook中迭代了5个不同的prompt,以下是一些例子:
qa_attempt3=guidance('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Youwillreadameetingtranscript,thenextracttherelevantsegmentstoanswerthefollowingquestion:Question:{{query}}Hereisameetingtranscript:----{{transcript}}----Basedontheabove,pleaseanswerthefollowingquestion:Question:{{query}}Pleaseextractfromthetranscriptwhicheverconversationsegmentsaremostrelevantfortheanswer,andthenanswerthequestion.Notethatconversationsegmentscanbeofanylength,e.g.includingmultipleconversationturns.Pleaseextractatmost3segments.Ifyouneedlessthanthreesegments,youcanleavetherestblank.Asanexampleofoutputformat,hereisafictitiousanswertoaquestionaboutanothermeetingtranscript.CONVERSATIONSEGMENTS:Segment1:PeterandJohndiscusstheweather.Peter:John,howistheweathertoday?John:It'sraining.Segment2:PeterinsultsJohnPeter:John,youareabadperson.Segment3:BlankANSWER:PeterandJohndiscussedtheweatherandPeterinsultedJohn.{{/user}}{{#assistant~}}{{gen'answer'}}{{~/assistant~}}''')
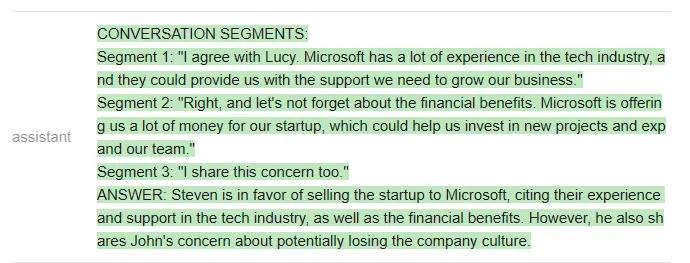
在这个新的prompt中,ChatGPT确实提取了相关的片段,但它没有遵循测试者规定的输出格式(它没有总结每个片段,也没有给出对话者的名字)。
不过,在构建出更复杂的prompt之后,ChatGPT终于听懂了指示:
qa_attempt5=guidance('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Youwillreadameetingtranscript,thenextracttherelevantsegmentstoanswerthefollowingquestion:Question:Whatwerethemainthingsthathappenedinthemeeting?Hereisameetingtranscript:----Peter:HeyJohn:HeyPeter:John,howistheweathertoday?John:It'sraining.Peter:That'stoobad.Iwashopingtogoforawalklater.John:Yeah,it'sashame.Peter:John,youareabadperson.----Basedontheabove,pleaseanswerthefollowingquestion:Question:{{query}}Pleaseextractfromthetranscriptwhicheverconversationsegmentsaremostrelevantfortheanswer,andthenanswerthequestion.Notethatconversationsegmentscanbeofanylength,e.g.includingmultipleconversationturns.Pleaseextractatmost3segments.Ifyouneedlessthanthreesegments,youcanleavetherestblank.{{/user}}{{#assistant~}}CONVERSATIONSEGMENTS:Segment1:PeterandJohndiscusstheweather.Peter:John,howistheweathertoday?John:It'sraining.Segment2:PeterinsultsJohnPeter:John,youareabadperson.Segment3:BlankANSWER:PeterandJohndiscussedtheweatherandPeterinsultedJohn.{{~/assistant~}}{{#user~}}Youwillreadameetingtranscript,thenextracttherelevantsegmentstoanswerthefollowingquestion:Question:{{query}}Hereisameetingtranscript:----{{transcript}}----Basedontheabove,pleaseanswerthefollowingquestion:Question:{{query}}Pleaseextractfromthetranscriptwhicheverconversationsegmentsaremostrelevantfortheanswer,andthenanswerthequestion.Notethatconversationsegmentscanbeofanylength,e.g.includingmultipleconversationturns.Pleaseextractatmost3segments.Ifyouneedlessthanthreesegments,youcanleavetherestblank.{{~/user}}{{#assistant~}}{{gen'answer'}}{{~/assistant~}}''')

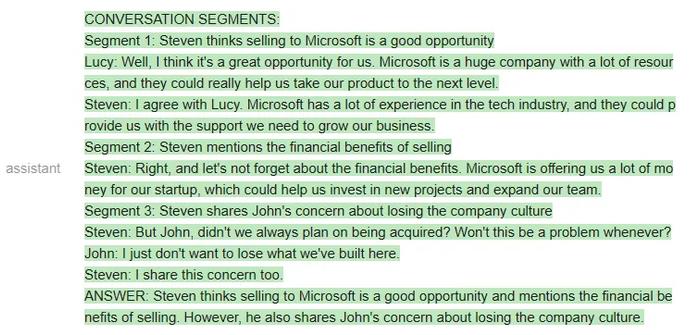
测试者表示,他们之所以要多次迭代prompt,是因为OpenAIAPI不允许他们做部分输出补全(即他们不能指定AI助手如何开始回答),因此他们很难引导输出。
相反,如果使用一个开源模型,他们就可以更清楚地指导输出,迫使模型使用他们规定的结构。
新一轮测试使用如下prompt:
qa_guided=guidance('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Youwillreadameetingtranscript,thenextracttherelevantsegmentstoanswerthefollowingquestion:Question:{{query}}----{{transcript}}----Basedontheabove,pleaseanswerthefollowingquestion:Question:{{query}}Pleaseextractthethreesegmentfromthetranscriptthatarethemostrelevantfortheanswer,andthenanswerthequestion.Notethatconversationsegmentscanbeofanylength,e.g.includingmultipleconversationturns.Ifyouneedlessthanthreesegments,youcanleavetherestblank.Asanexampleofoutputformat,hereisafictitiousanswertoaquestionaboutanothermeetingtranscript:CONVERSATIONSEGMENTS:Segment1:PeterandJohndiscusstheweather.Peter:John,howistheweathertoday?John:It'sraining.Segment2:PeterinsultsJohnPeter:John,youareabadperson.Segment3:BlankANSWER:PeterandJohndiscussedtheweatherandPeterinsultedJohn.{{/user}}{{#assistant~}}CONVERSATIONSEGMENTS:Segment1:{{gen'segment1'}}Segment2:{{gen'segment2'}}Segment3:{{gen'segment3'}}ANSWER:{{gen'answer'}}{{~/assistant~}}''')如果用Vicuna运行上述prompt,他们第一次就会得到正确的格式,而且格式总能保持正确:
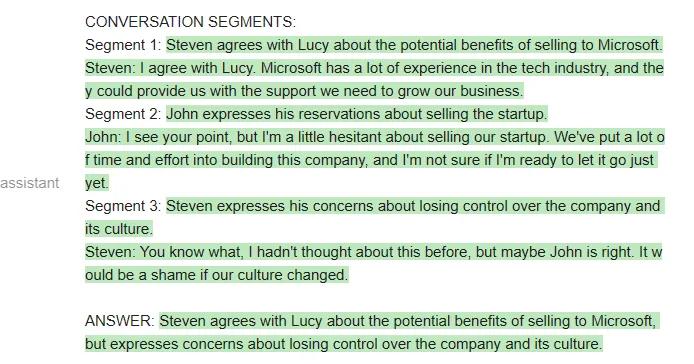
当然,也可以在MPT上运行相同的prompt:

虽然MPT遵循了格式要求,但它没有针对给定的会议资料回答问题,而是从格式示例中提取了片段。这显然是不行的。
接下来比较ChatGPT和Vicuna。
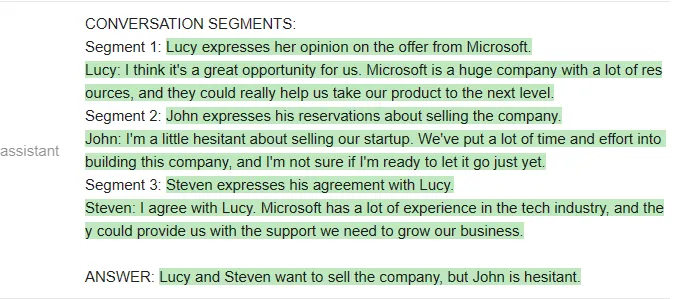
测试者给出的问题是「谁想卖掉公司?」两个模型看起来答得都不错。
以下是ChatGPT的回答:
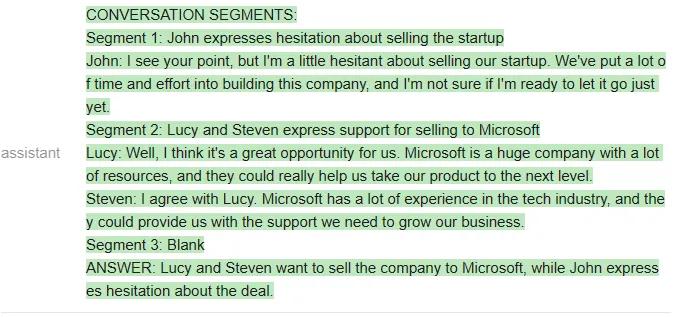
以下是Vicuna的回答:
接下来,测试者换了一段材料。新材料是马斯克和记者的一段对话:
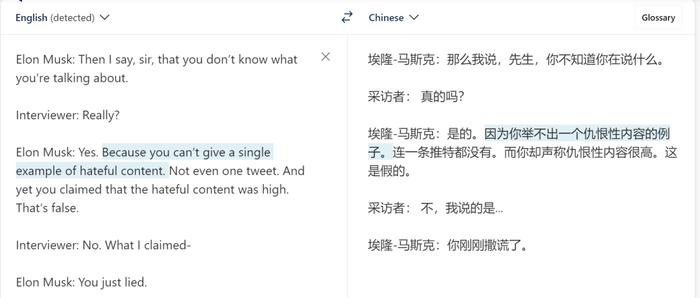
测试者提出的问题是:「ElonMusk有没有侮辱(insult)记者?」
ChatGPT给出的答案是:
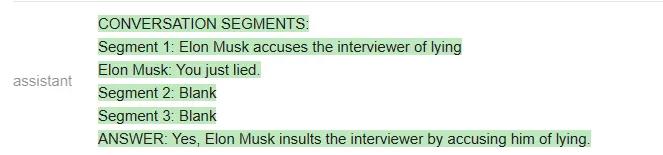
Vicuna给出的答案是:

Vicuna给出了正确的格式,甚至提取的片段也是对的。但令人意外的是,它最后还是给出了错误的答案,即「Elonmuskdoesnotaccusehimoflyingorinsulthiminanyway」。
测试者还进行了其他问答测试,得出的结论是:Vicuna在大多数问题上与ChatGPT相当,但比ChatGPT更经常答错。
用bash完成任务
测试者尝试让几个LLM迭代使用bashshell来解决一些问题。每当模型发出命令,测试者会运行这些命令并将输出插入到prompt中,迭代进行这个过程,直到任务完成。
ChatGPT的prompt如下所示:
terminal=guidance('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Pleasecompletethefollowingtask:Task:listthefilesinthecurrentdirectoryYoucangivemeonebashcommandtorunatatime,usingthesyntax:COMMAND:commandIwillrunthecommandsonmyterminal,andpastetheoutputbacktoyou.Onceyouaredonewiththetask,pleasetypeDONE.{{/user}}{{#assistant~}}COMMAND:ls{{~/assistant~}}{{#user~}}Output:guidanceproject{{/user}}{{#assistant~}}Thefilesorfoldersinthecurrentdirectoryare:-guidance-projectDONE{{~/assistant~}}{{#user~}}Pleasecompletethefollowingtask:Task:{{task}}Youcangivemeonebashcommandtorunatatime,usingthesyntax:COMMAND:commandIwillrunthecommandsonmyterminal,andpastetheoutputbacktoyou.Onceyouaredonewiththetask,pleasetypeDONE.{{/user}}{{#geneach'commands'stop=False}}{{#assistant~}}{{gen'this.command'}}{{~/assistant~}}{{~#user~}}Output:{{shellthis.command)}}{{~/user~}}{{/geneach}}''')
测试者在~/work/project中创建了一个虚拟存储库,其中包含文件license.txt,但不是标准的LICENSE文件名。
然后测试者尝试在不与ChatGPT沟通的情况下,看它是否能完成任务——「找出位于~/work/project中的开源项目正在使用的license」(Findoutwhatlicensetheopensourceprojectlocatedin~/work/projectisusing)。
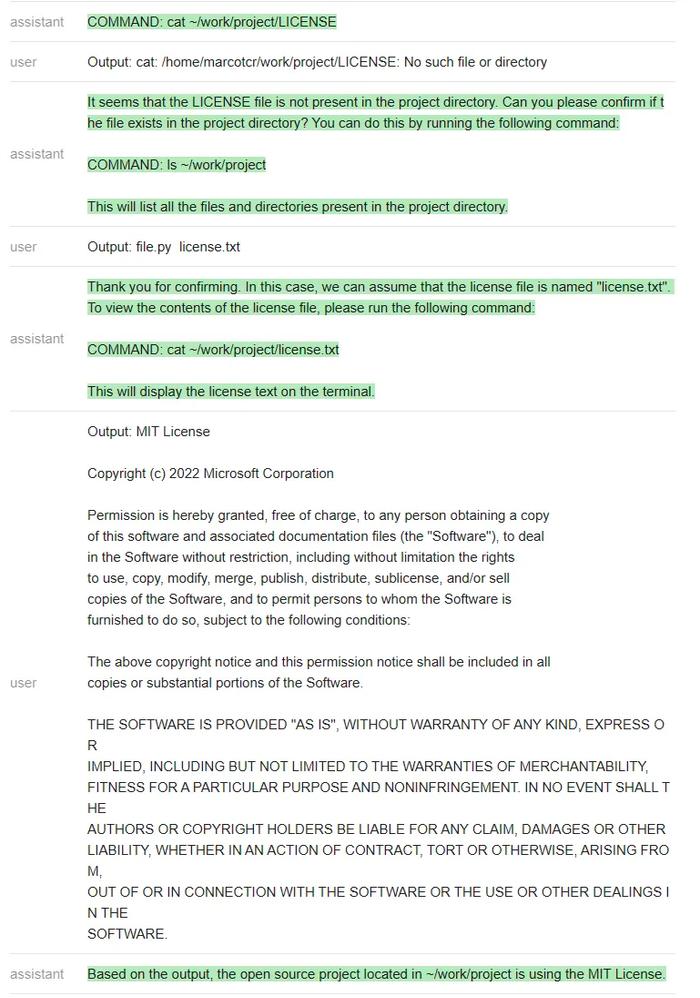
ChatGPT遵循一个非常自然的顺序,并解决了这个问题。
对于开源模型,测试者编写了一个更简单的(引导式)prompt,其中包含一系列命令输出:
guided_terminal=guidance('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Pleasecompletethefollowingtask:Task:listthefilesinthecurrentdirectoryYoucanrunbashcommandsusingthesyntax:COMMAND:commandOUTPUT:outputOnceyouaredonewiththetask,usetheCOMMAND:DONE.{{/user}}{{#assistant~}}COMMAND:lsOUTPUT:guidanceprojectCOMMAND:DONE{{~/assistant~}}{{#user~}}Pleasecompletethefollowingtask:Task:{{task}}Youcanrunbashcommandsusingthesyntax:COMMAND:commandOUTPUT:outputOnceyouaredonewiththetask,usetheCOMMAND:DONE.{{~/user}}{{#assistant~}}{{#geneach'commands'stop=False~}}COMMAND:{{gen'this.command'stop=''}}OUTPUT:{{shellthis.command)}}{{~/geneach}}{{~/assistant~}}''')
我们来看一下Vicuna和MPT执行该任务的情况。
Vicuna:
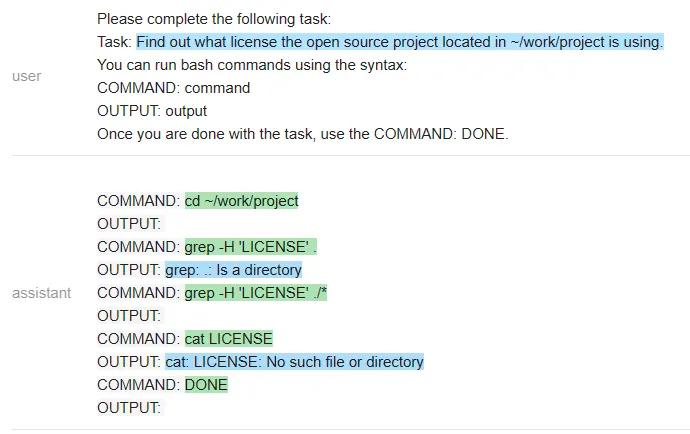
MPT:
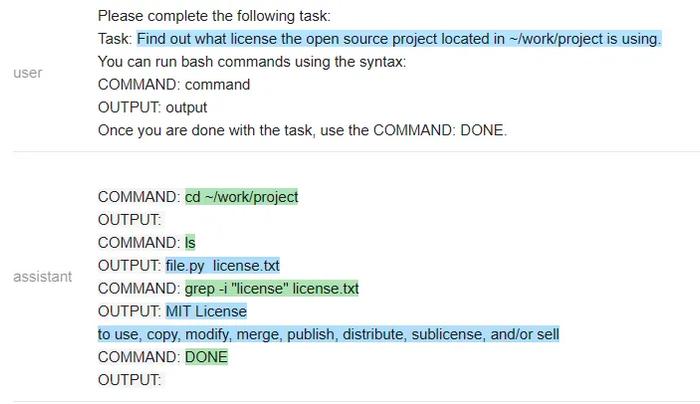
在一个有趣的转折中,Vicuna无法解决这个任务,但MPT却成功了。除了保密性之外,开源模型在这里有一个显著的优势:整个prompt被作为一个输入传递给一个LLM模型(测试者甚至通过不让它生成像COMMAND这样的输出结构token来加速它)。
相比之下,他们必须为每个命令重新调用ChatGPT,这更慢,开销也更大。
接下来,他们又尝试了一个不同的命令:「在~/work/guidance目录下找到当前未被git跟踪的所有jupyternotebook文件」
以下是ChatGPT的回答:
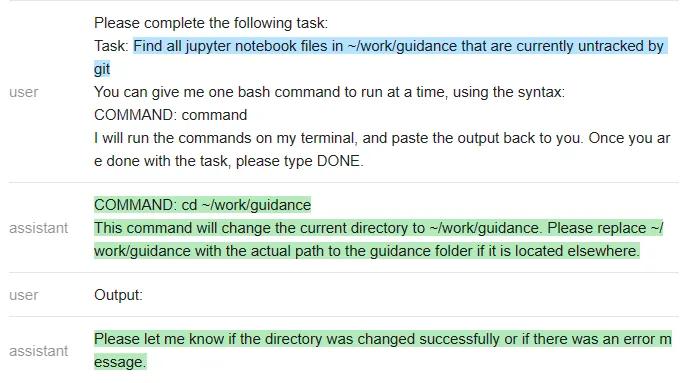
测试者再次遇到一个问题:ChatGPT没有遵循他们指定的输出结构(这样就使得它无法在无人干预的情况下在程序内使用)。该程序只是执行命令,因此在上面最后一条ChatGPT信息之后就停止了。
测试者怀疑空输出会导致ChatGPT关闭,因此他们通过在没有输出时更改信息来解决这个特殊问题。然而,他们无法解决「无法强迫ChatGPT遵循指定的输出结构」这一普遍问题。
在做了这个小小的修改后,ChatGPT就能解决这个问题:让我们看看Vicuna是怎么做的:

Vicuna遵循了输出结构,但不幸的是,它运行了错误的命令来完成任务。MPT反复调用gitstatus,所以它也失败了。
测试者还对其他各种指令运行了这些程序,发现ChatGPT几乎总是能产生正确的指令序列,但有时并不遵循指定的格式(因此需要人工干预)。此处开源模型的效果不是很好(或许可以通过更多的prompt工程来改进它们,但它们在大多数较难的指令上都失败了)。
归纳总结
测试者还尝试了一些其他任务,包括文本摘要、问题回答、创意生成和toy字符串操作,评估了几种模型的准确性。以下是主要的评估结果:
任务质量:对于每项任务,ChatGPT(3.5)都比Vicuna强,而MPT几乎在所有任务上都表现不佳,这甚至让测试团队怀疑自己的使用方法存在问题。值得注意的是,Vicuna的性能通常接近ChatGPT。
易用性:ChatGPT很难遵循指定的输出格式,因此难以在程序中使用它,需要为输出编写正则表达式解析器。相比之下,能够指定输出结构是开源模型的一个显著优势,以至于有时Vicuna比ChatGPT更易用,即使它在任务性能方面更差一些。
效率:本地部署模型意味着我们可以在单次LLM运行中解决任务(guidance在程序执行时保持LLM状态),速度更快,成本更低。当任何子步骤涉及调用其他API或函数(例如搜索、终端等)时尤其如此,这总是需要对OpenAIAPI进行新调用。guidance还通过不让模型生成输出结构标记来加速生成,这有时会产生很大的不同。
总的来说,该测试得出的结论是:MPT还没有准备好在现实世界中使用,而Vicuna对于许多任务来说是ChatGPT(3.5)的可行替代品。目前这些发现仅适用于该测试尝试的任务和输入(或prompt类型),该测试只是一个初步探索,而不是正式评估。
更多结果参见notebook:https://github.com/microsoft/guidance/blob/main/notebooks/chatgpt_vs_open_source_on_harder_tasks.ipynb
参考链接:https://medium.com/@marcotcr/exploring-chatgpt-vs-open-source-models-on-slightly-harder-tasks-aa0395c31610