
Open AI为他新开一页族谱,o1模型强在哪里?
21世纪经济报道见习记者郭聪聪实习生刘欣北京报道
9月13日凌晨,OpenAI在没有任何预告的情况下,扔出了o1-preview模型上线的重磅炸弹。
OpenAI对该模型介绍道,“o1模型是一个新的大型语言模型,经过强化学习(reinforcementlearning,RL)训练,可以执行复杂的推理。o1模型在回应用户之前会产生长串的内部思维链(chainofthought)。”这种内部思维链,类似于人类通过逐步推理来解决问题。
对此OpenAI称,这是一个重要的进展,代表了人工智能能力的新水平。
AI可以思考?o1模型超越人类顶尖水平实力
之前就有人猜测这次发布的模型可能会被命名为GPT-5,但o1系列的创新性令OpenAI不惜舍弃GPT系列命名,以“Orion(猎户座)”重新命名了一个全新的o系列,可以说是新开一页族谱了。OpenAI称该命名存有“将‘计数器’重置为1”的寓意。
OpenAI的研究负责人JerryTworek表示,相较于GPT,o1模型采用了全新的优化算法和专门为其定制的训练数据集进行训练,它能够比人类更快地回答更复杂的问题。
那么o1系列模型到底有多强呢?
OpenAI官方发布了模型的对比测试,作为比较参照数值的是今年5月上新的GPT-4o模型与人类专家水平。
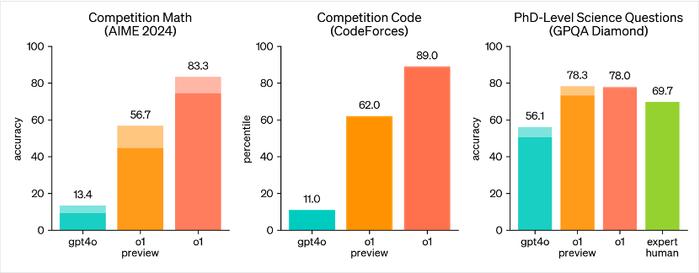
在组图对比成绩中可以直观感受到,o1模型的绝对压制力。OpenAI官网直言,结果表明o1模型在大多数推理任务中明显优于GPT-4o。
无论是在国际数学奥林匹克的选拔考试测试(AIME)、代码竞赛还是博士及科学问题的对比测试中,o1模型都压倒式的碾压目前的GPT-4o模型。在数学竞赛与代码竞赛的正确率上,还未发布的o1正式版是GPT-4o模型的6-8倍。而在博士级科学推理问题(GPQADiamond)测试中,o1模型也表现出了接近甚至超越人类顶尖水平的实力。
比AI更恐怖的是,是AI可以思考。
之所以产生这种质变的正确率,是因为o1系列模型加入了RL技术,逐渐生成“思维链”——这一类似于人类推理的思考方式。该技术通过奖励和惩罚来教导系统,令系统学会了识别和纠正自己的错误,同时也学会了将复杂的步骤分解为更简单的步骤。
OpenAI这次划时代的模型创新带来了人工智能从大语言模型的ScalingLaw到新范式Self-playRL的跨时代转变,这或是对于AGI时代发起的一次冲锋。
从GPT到o1,o1模型强在哪里
自2018年6月GPT-1面世以来,OpenAI一直优化拓展GPT系列模型,至2024年5月已迭代到了GPT-4o,期间还推出了专门设计用于对话生成任务ChatGPT。
在GPT系列模型一路迭代的过程中,目光更多聚焦精进模型参数规模来提升性能,以大语言模型训练模型(ScalingLaw)进行多任务学习,最终在GPT-4o中实现了文本、音频和图像的任何组合作为输入的多模态大模型。
但此次推出的o1模型是OpenAI的革新之举,代表了一种全新的推理能力。
首先是RL技术的差异,想当年,AlphaGo战胜人类棋手,背后就是用的是RL算法。OpenAI研究员JasonWei表示,o1模型是一个在给出最终答案之前进行思考的模型。通过RL技术训练模型,能够更好地执行链式思考。
除了训练方法上的差别外,不同于GPT-4o的多任务能力,o1模型在处理复杂的编程和数学问题时具有独特优势,并能解释其推理过程。在处理复杂的推理任务的评测中,o1模型已证明了自己的绝对实力。
同时为满足不同需求,OpenAI推出了o1-preview与o1-mini两个o1模型。o1-preview注重深度思考与科学推理,每周速率限制为30条消息。o1-mini是一种经济高效的推理模型,非常擅长STEM,尤其是数学和编码,用于需要推理但不需要广泛世界知识的应用场景,每周速率限制为50条。
作为o1的早期模型,o1-preview尚为纯文字版,还不具备ChatGPT处理文本、音频和图像组合输入的能力。
目前,o1模型已经逐步向所有ChatGPTPlus和Team用户开放,后续OpenAI将计划为所有ChatGPT免费用户提供o1-mini访问权限。