
大语言模型懂数学?OpenAI发o1模型,解题高手如何炼成的
北京时间9月13日,OpenAI发布了新一代o1系列模型。其首席执行官山姆奥特曼表示,o1是“迄今为止功能最强大,最具有一致性的模型。”“这是一个新范式的开始,人工智能可以进行复杂推理了。”
新京报贝壳财经记者浏览OpenAI公开的技术文档、演示视频及该公司员工的发声内容发现,本次OpenAI更新的方向旨在加固此前大模型的“短板”:数学推理。这种具备更强推理能力的o1系列模型共有三种:o1、o1-mini以及抢先版o1-preview。从今天开始,o1-preview已在ChatGPT中向所有Plus和Team用户推出。
补数学运算“短板” 未来AI或许能在数学问题上超越人类
大语言模型之所以是“语言模型”,就是因为其胜在对语言的解析以及流畅的回答,但一旦涉及数学问题,大语言模型往往会现出真面目,因此数学推理也成为了大语言模型的短板。
而在本次更新中,OpenAI表示,o1系列模型可以推理复杂的任务并解决比以前的科学、编码和数学模型更难的问题。在OpenAI官方展示的视频里,量子物理学家使用GPT-4进行数学运算,可以发现在对话界面,大模型展示出了数学运算细节。
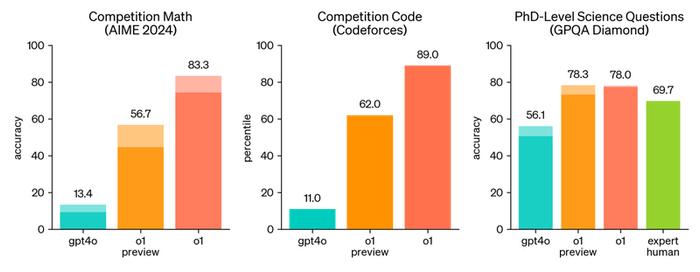
在具体的能力对比上,山姆奥特曼晒出了o1与GPT-4o的数值差异:在数学竞赛中GPT-4o得分为13.4,o1得分高达83.3;编程竞赛中,GPT-4o得分为11.0,o1得分高达89;差异较为不明显的则是博士级别科研问题,GPT-4o得分为56.1,o1得分为78.0,相比之下科研人员的得分是69.7。
OpenAI在官方技术文档中表示,以目前o1模型的成绩,在美国数学邀请赛上可以排名进入美国前500名。
此外,o1-mini也展示出了不俗的实力,OpenAI科学研究员赵生家(音)发文称,该款大模型在运行成本更低的情况下,还能实现70%AIME(美国数学邀请赛)正确率和Codeforces(一个程序员在线竞赛平台)Elo评分1650(专家级水平)的成绩。山姆奥特曼则在赵生家的推文后评论,“你们做出了令人难以置信的工作,这款模型的性价比非常好。”
值得注意的是,在此前达摩院举办的2024阿里巴巴全球数学竞赛初赛中,AI队伍未能达到决赛入围分数线,统计显示,参赛AI队伍的平均分已达到了人类选手平均水平,但离数学高手仍有较大差距。不知此次OpenAI更新o1后,人类与AI在数学能力上的差距是否会有所缩短。
“可以推理复杂的任务”的大模型是如何炼成的?思路链功能揭秘
那么,OpenAI是如何“补足”大语言模型天生的数学短板的呢?
该公司在官网表示,“我们训练这些模型在问题做出响应之前花更多时间思考问题,就像一个人一样。通过培训,他们学会完善自己的思维过程,尝试不同的策略,并认识到自己的错误。”
根据OpenAI披露的官方技术文档,o1在尝试解决问题时会使用一系列思路链(chainofthought),“通过强化学习,o1学会了磨炼其思路链并完善其使用的策略。它学会了认识并纠正错误,将棘手的步骤分解为更简单的步骤。如果当前方法不起作用,它会尝试另一种方法,这个过程极大地提高了模型的推理能力。”

OpenAI官方技术文档中展示的“思路链”(右图)与原回答的区别。
OpenAI的技术文档在密码、数学、编码、字谜、语言、科学等多个维度展示了“思路链”能力。如在语言的案例中,OpenAI展示了大模型对一段阅读理解的回答,对该问题,GPT-4o会直接选择答案A,而o1-preview则经过“思路链”分析了从A到E总共5个选项,最终选择了D。
开源证券研报分析认为,本次o1系列模型问世,代表着模型能通过RL在除训练侧之外的推理侧,引入“思路链”等新技术的方式提升模型的性能,为科学、数学、编码等专业领域提供更准确的答案,这或是生成式AI发展的重要拐点。
新京报贝壳财经记者罗亦丹
编辑岳彩周
校对吴兴发