
ChatGPT 价格里掩盖的算力分布秘密 | 新程序员
【导读】当前,大语言模型的商业化持续进行,本文聚焦这一变革背景下的ChatGPT定价机制,深入剖析其核心技术内涵。通过细致研究ChatGPT-3.5turbo采用的Decode-Only架构,作者系统地探讨了模型在接收到输入提示并生成相应输出的过程中,如何差异化利用GPU算力资源,进而阐明了支撑该定价策略的独特技术原理。
本文精选自《新程序员 007:大模型时代的开发者》,《新程序员007》聚焦开发者成长,其间既有图灵奖得主JosephSifakis、前OpenAI科学家JoelLehman等高瞻远瞩,又有对于开发者们至关重要的成长路径、工程实践及趟坑经验等,欢迎大家点击订阅年卡。
作者|李波
责编| 王启隆
出品|《新程序员》编辑部

2022年8月,美国科罗拉多州举办艺术博览会,《太空歌剧院》获得数字艺术类别冠军,此作品是游戏设计师JasonAllen使用AI绘图工具Midjourney生成;同年11月30日由OpenAI研发的一款聊天机器人程序ChatGPT发布,生成式AI(AIGC)概念开始极速式地席卷全球,逐渐深入人心,预示着一个新的AI时代。

现在回过头来看这幅《太空歌剧院》,你有什么感觉?
随着ChatGPT用户爆发式的增长,大型语言模型(LargeLanguageModel,简称LLM)受到企业、政府、大众的广泛关注。由于ChatGPT的闭源策略,开源大语言模型在2023年迭代频繁,种类繁多。随着语言模型研究的深入,大多数从业人员对语言模型的本质及其功能有了基本的了解,但在模型商业化方向上,不同的模型到底如何定义模型的服务成本,又为什么该这样的定义,常常无从下手。ChatGPT作为LLM应用的开创者,自然有其答案,但是又如此的不明显或让人困惑。
本文试图通过深入分析模型结构,了解成本成因,提炼ChatGPT的定价方法论,指导通用语言模型推理的基础方向,其中涉及的技术分析均以ChatGPT-3.5turbo采用的Decode-Only架构结构为基础,重点讨论宏观逻辑方向,并不做精确指向。

令人困惑的价格
ChatGPT是一个复杂的自然语言处理平台,利用先进的机器学习算法来分析和创建类似人类的文本或说话方式。它的功能非常广泛,包括文本推演、文本分类和语言翻译等。针对这类模型,合理的定价方式会是一个有意思的问题。
对此,OpenAI给出的答案非常新颖,其ChatGPT平台并没有按调用次数定价,而是对数据处理进行定价,这让人有点匪夷所思,甚至违反常识(参见图1)。更有特点的是,ChatGPT定价针对输入数据与输出数据的差异,可见其不仅在应用层面带来惊艳,定价也是与众不同。
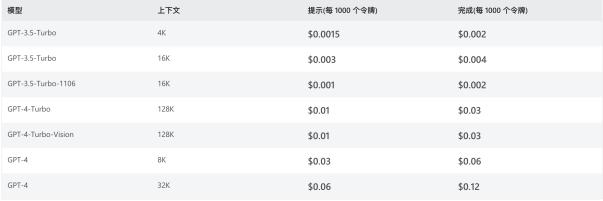
我曾与Gartner高级分析师就此问题展开过讨论,对方的观点更倾向于OpenAI是出于商业竞争考虑做出的定价策略,此策略对成本的相关性较弱,为了更快速的市场占有率而制定。我同意这样的观点。
由于ChatGPT的模型结构、部署卡数、限流策略、服务器资源的水位控制、最大的并发能力以及首token的延迟标准等影响推理系统的重要信息未被披露,我们无法计算出真实的推理成本以及他们的API毛利率。但作为世界上用户人数增长最快的应用,先拉低初次使用费用,再利用规模效应,优化算法与推理系统,以达到低成本的长尾收获,不失为一种冷启动的商业模式。只是,这种思路并没有完整的回答我内心的关于输入与输出定价不同的问题:它们之间的价格为什么是成倍的?且大多为2倍?这似乎隐约映射着某种底层逻辑。
我们先回顾一下图1中的几处关键概念:
token
token是大语言模型的一个基本概念,它本质上是用于分析和处理的语言的构建块。在像ChatGPT这样的语言模型中,token对于理解和生成自然语言文本方面起着至关重要的作用。
上下文窗口
上下文窗口是语言模型在处理文本时可以考虑的最大文本量。ChatGPT系列的模型中都带有一个上下文窗口,如GPT-416K,GPT-432K这类,其中的16K就是指的模型可以一次性处理的token数量;如果用户输入的提示超出了模型的上下文窗口限制,它就会忘记限制之后的内容。
提示词
提示词是大语言模型的输入,是对话的开始,亦是一段指令、背景描述、几个例子或任何用户想告诉大语言模型的事情。
我们再看一下通用模型的一般服务成本:
推理成本,即调用LLM生成响应的成本。
为硬性支出成本,表现为 GPU物理服务器或云GPU服务器成本,高速网络成本,存储成本等。
调整成本,即调整定制的 LLM预训练/微调模型响应的成本。
为软性支出成本,主要表现为研发人力的投入,对模型加速、服务化、监控等方面的投入成本。
托管成本,即部署和维护 API背后的模型、支持推理或调优的成本。
为硬性支持成本,私有化或云的托管费用。
也许还有更多成本与商业定价策略未包含其中,但是以上3点会在定价策略中优先考虑,其中推理成本占比最高,尤其是其中的GPU算力成本,为了便于讨论,我们姑且将ChatGPT的定价策略都归因到算力上。

提示Token应该计费吗?又为什么更便宜?
LLM目前的主流模型为Decoder-Only类型中的CausalLM(CausalLanguageModel,因果语言模型),它的算力释放全过程如图2表示。
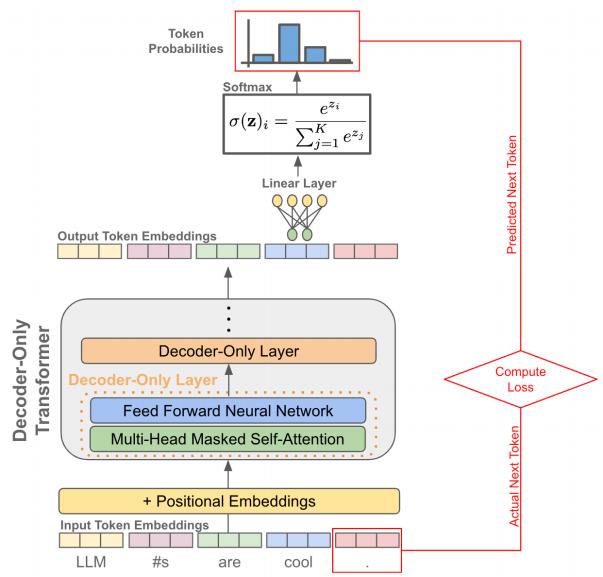
全流程中核心算力密度集中在 Decoder-Only 层,细化步骤如图 3。
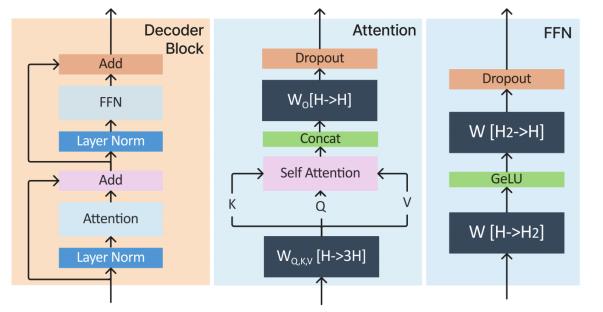
Decoder-Block 主要分2 部分,Attention和FFN:
Attention,模型参数有Q,K,V的权重矩阵WQ,WK,WV 以及Bias,输出权重矩阵Wo以及Bias,4个权重矩阵的维度为[hidden_size,hidden_size],4个Bias的维度是[hidden_size]。
FFN,由2个线性层组成,一般首层会将维度从H映射到3H或者4H,后层再将3H/4H映射回H。
我们继续推演,窥探一下推理过程的算力分布,这里仅列出过程中的关键操作,省略计算的详细推导过程,同时忽略 embedding,位置编码,logits的计算。下面先简短回顾核心公式以及计算张量的维度变化(参见图4、图5、图6、图7)。
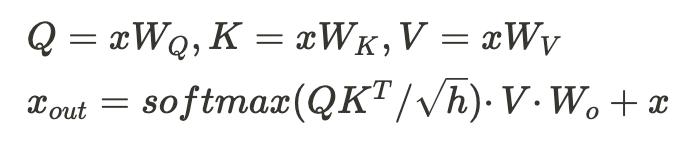
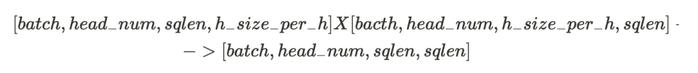

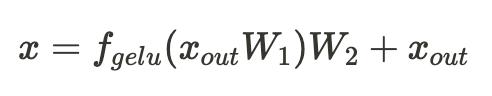
在 embedding维度为 d’ 的情况下,提示 sqlen在第一次推理时的单一token需要的算力分布大致如下,单位为Flops(见图8):
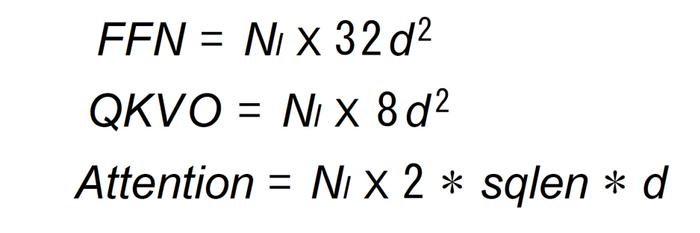
这里重点解释一下Attention的计算为什么不是Nl×4×sqlen×d,针对自回归解码器模型而言,token只会关注先前的token序列,这意味着注意力分数矩阵S是一个下三角矩阵,不需要计算上三角部分,即QKT的计算只计算下三角,为(sqlen+1)×d。另外,在Attention输出变换时(计算图2的维度中,SOFTMAX的返回值为下三角),也能减少一半计算,最后计算量为Nl×2×sqlen×d。
以上是在 BatchSize=1的一次向前推理,后续的每一次推理理论上都需要相同的计算量。实际情况中,由于推理框架加速技术和KVcache的作用,实际计算量会显著下降,但推理速度并不会显著提升,这是因为还涉及到模型的计算需求与访存需求的限制或权衡。
对于访存密集型模型来说,其推理速度受限于 GPU访存带宽,每种不同GPU的访存带宽不一,模型大小不一,其推理速度差别较大,这里只从宏观层面阐述一般性总结,忽略模型数据或中间结果的数据传输与访存带宽之间的关系。
Decoder-OnlyTransformer模型为访存密集型模型,其推理过程分为2个阶段,Stage1(阶段1)是Prefill,Stage2(阶段2)为Decode,Prefill由于可以通过大BatchSize计算,使得这一阶段为计算密集型,推理速度较快。
Decode为逐个token解码,采用自回归形式,期间需要在HBM和SDRAM中频繁搬运数据,导致模型进入访存密集型阶段,推理速度较慢,GPU显存分布可见图9,从上到下,访存带宽指数级减少。
图10和图11是LLaMA-13B在A6000上对输入序列1024的测试表现,我们可以交叉来看,在BatchSize递增时,Prefill的推理时间几乎不变,各类计算阶段涨跌不大,但计算密度在增加;在Decode阶段,BatchSize=1的情况下Decode的延迟达到了Prefill的200+倍,因为其计算密度几乎为0,随着BatchSize递增,计算密度缓慢提高,但(FFN+QKVO)的线性算子的延迟急剧下降到20+倍以下。
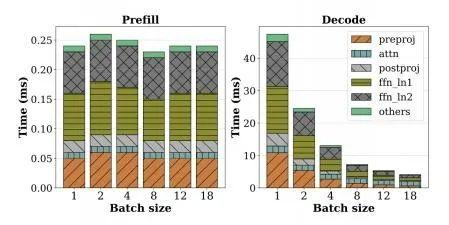
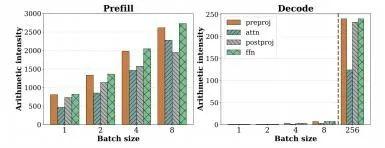
可以推断,Decode阶段增大BatchSize可以提高计算密度,对整体延迟降低有较大帮助,在此例子中如果达到256,Decode会重新回到计算密集型,整体推理延迟会显著下降,但在达到这个临界BatchSize之前,相比Prefill是数量级的缓慢。
在真实的生产场景,由于GPU显存的限制,不可能直线增大BatchSize,因为还要留给KVCache一些空间。就本例而言,BatchSize=18或许已经是最优选择。这里比较有意思的是Attention的计算延迟并没有从大BatchSize中受益,几乎没有变化。最后一句话总结,Decode无论是否真实的占用了GPU算力,都是占用了GPU的使用时间,理论上GPU在单位时间内的价格是固定的,占用时长直接与使用费用成正比。
回到我们的问题,我们很容易分辨出Prefill阶段对应API输入prompt处理,API回复对应Decode阶段的处理。由于对算力占用时长的不同,它们的定价有差异性才是正常,图1定价Prefill阶段几乎是Decode阶段的2倍,但是时长占比可能是20~200倍,似乎中间还有一个scale值;这或是因为我们只是考虑单卡单session的情况,在真实的GPU集群场景下,除了单卡加速外,TP/PP的并行计算,在集群性能的极限并发情况下,scale可能达到10~100倍。另外,由于Prefill的延迟极短,针对单token而言费用极低,从定价策略来说,可能只是象征性的,Decode阶段才是核心,内容是持续产生的,也是我们需要的。某种程度上可以理解为,API的单一定价策略,即总体成本以输出Decode阶段为主。

新势力带来的新趋势
ChatGPT的tokens价格在业内是极具竞争力的,OpenAI的AIinfra能力起到了决定性的作用,通过量化、TT、模型分布式部署、算子融合、显存管理和CPUoffload等技术,再加之商业让利,是可能达到这样的定价水平。
ChatGPT在2023年的几次降价都说明了OpenAI算法和工程化能力的快速进步,向技术拿收益确实是实打实的,不断降低模型推理成本是推动大语言模型广泛应用及实现AGI目标的关键驱动力。2024年所有的模型创新和推理加速技术创新一定会围绕高性能低成本这个目标。
基于Decoder-OnlyTransformer类似的LLM,存在计算与存储都与输入成二次方的关系,对算力、显存大小、访存带宽都有极高的要求,加上对上下文窗口的限制以及窗口内部分遗忘的问题,对LLM应用也产生了一定阻力,学术界因此也在不断发展新的模型结构,试图解决这些问题。
目前比较有创新力的新模型结构有StripedHyena和Mamba,它们突破了随着文本长度的增加,算力需求成二次方的要求,几乎可以做到算力对输入文本线性增长,并可以分段拆分输入文本,并行计算,极大提高推理速度,使得推理成本会进一步大幅降低。
另外,新的模型组合方式有MistralAI发布的Mixtral-7B×8-MoE(混合专家模型),由8个7B参数组成的网络,这种方式不仅可以提高模型处理信息的效率,提升模型性能(几乎已超越LLaMa-70B),更重要的是降低了运行成本。据官方说明,Mixtral-7B×8-MoE实际参数并非56B,而是45B。该模型中只有前馈层是各专家独有,其余参数与7B模型情况相同,各专家共享。每次推理过程,门控路由网络只会选择2个专家进行实际推理,过程中只会使用其中120亿参数,每个token会被2个模型处理。于是,MoE模型的推理速度和成本与12B参数规模的模型是一样的。当然,这暂时忽略了45B模型的部署成本,部署成本根据模型的量化程度所需要的启动GPU显存开销是不同的,比如FP16精度下,至少需要90GB的空间才能启动,这需要2张A100/800-80GB的卡,或者3张A100-40GB的卡。如果精度降到4bit,只要大于23GB就满足要求。MoE开启了用相对的低算力却可以达到需要高算力才能产生的模型精度的新范式,以独特的维度降低了大模型的服务成本。
2024年,新的模型结构与加速方式,配合新一代GPU硬件的发展,预计将对后续的模型研究产生积极的影响,并可能改写现行的计价模式——回归传统的按调用次数计费。这种转变不仅预期大幅降低使用成本,同时有利于简化计费系统架构设计及其流量控制管理等方面的操作。然而,调用次数计费模式的核心在于揭示了一个趋势:模型能力的价值在定价中的比重将显著提升(当前这一比例接近个位数);与此同时,模型推理成本在定价中的比重则会大幅下降(当前几乎占据了100%)。
随着成本逐渐走低,商业价值得到提升,应用回归商业底层逻辑,最终让大语言模型真正走进千行百业,发挥推动产业变革,企业数字化升级的新手段。

4月25~26日,由CSDN和高端IT咨询和教育平台Boolan联合主办的「全球机器学习技术大会」将在上海环球港凯悦酒店举行,特邀近50位技术领袖和行业应用专家,与1000+来自电商、金融、汽车、智能制造、通信、工业互联网、医疗、教育等众多行业的精英参会听众,共同探讨人工智能领域的前沿发展和行业最佳实践。欢迎所有开发者朋友访问官网http://ml-summit.org、点击「阅读原文」或扫描下方海报中的二维码,进一步了解详情。
