
从“选择困难症”说起:如何让决策树替你做选择?
序言
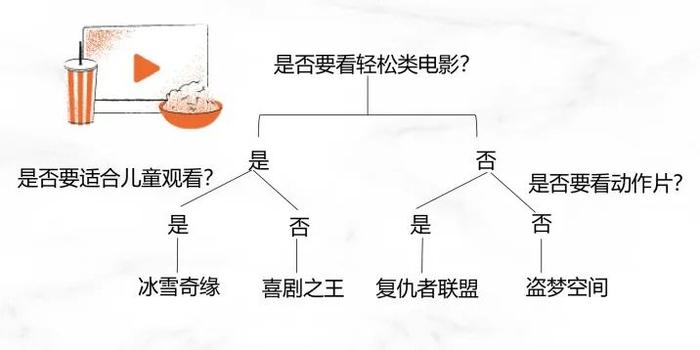
周末晚上,你准备好零食,窝在沙发上,计划来一场“宅家电影之夜”。面对列表中成堆的电影,你陷入了“选择困难症”。
于是,你在心中默问:“我是不是想看轻松类的电影”?答案是肯定的。这时,旁边的小孩哭了起来,你决定挑选一部也适合儿童观看的电影,最后你们全家一起看了《冰雪奇缘》。
这一步步的筛选,就像是沿着一棵树的分支前进,每个选择都会将你引导至不同的电影类型,直到最终找到最合适的那一部。这种逻辑不仅在生活中适用,也在机器学习领域广泛应用,我们称之为“决策树”。
1
什么是决策树?
决策树是一种用于分类和回归的监督学习模型,它从数据集合中提取出一系列的规则,基于特征对实例进行分类,可以理解为一组‘if-then’规则的集合。
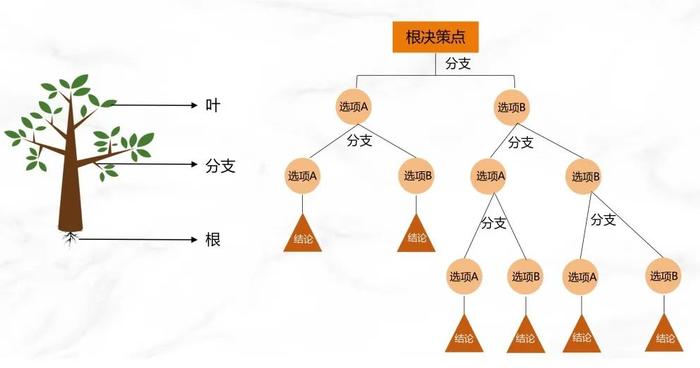
通俗地讲,决策树是一种用来决策和预测的模型,它通过类似树状的结构图,来展示决策过程以及最佳选项。每个“节点”代表一个决策点,每一条“分支”对应一个可能的选项,而一个“叶子节点”则代表决策的最终结果。
决策树的核心思想是找出更为纯净的子集,理想情况下,每个子集中的数据都指向极其单一的结论。
2
如何构建一棵决策树?
在决策树中,有两个至关重要的问题,它们直接影响到树的构建和最终的模型性能:
1、选择分裂特征
这是构建决策树时最核心的问题。每次选择何种特征来分裂数据集,决定了决策树的结构和性能。选择合适的特征可以使得数据集在分裂后尽可能“纯净”,即每个分支中的样本尽可能属于同一个类别。
常见的分裂标准包括:
信息增益(InformationGain):衡量通过某个特征进行分裂后,数据集的熵(不确定性)降低了多少。信息增益大的特征通常是优先选择的。
基尼系数(GiniIndex):用于评估数据集的纯度,基尼系数越低,表示数据集越纯,决策树会优先选择使基尼系数降低最多的特征。
卡方检验(Chi-squareTest):用于检测类别与特征之间的独立性,卡方值大的特征意味着它对分类的重要性更高。
增益率(GainRatio):对信息增益的改进,解决了信息增益偏向多值特征的问题。
2、何时停止分裂?
这是另一个影响决策树性能的重要问题。决策树的分裂过程不能无限制地进行,否则可能导致模型过拟合——过度适应训练数据,而在新数据上表现不佳。因此,合理地设置停止条件至关重要。
常见的停止条件包括:
最大深度(MaxDepth):限制决策树的深度,以避免树过深导致过拟合。
最小样本分裂数(MinSamplesSplit):如果一个节点中的样本数少于这个值,则停止分裂。
最小叶子节点样本数(MinSamplesLeaf):确保每个叶子节点包含足够多的样本,以避免分裂后产生过于小的叶子节点。
信息增益阈值(InformationGainThreshold):如果分裂后的信息增益小于某个阈值,则停止分裂,因为继续分裂的收益可能不足以提升模型的性能。
数据集纯度:当一个节点中的数据已经足够纯净(如所有样本都属于同一个类别)时,可以停止分裂。
决定何时停止分裂是防止过拟合、提高模型泛化能力的关键步骤。过早停止可能导致欠拟合,而过迟停止则可能导致过拟合,因此需要在两者之间找到平衡。
3
决策树在量化投资上的应用
量化投资依赖大量的、数据和复杂的模型,而决策树算法不仅能够将数据转化为易于理解的层次化结构,还能捕捉因子与股票涨跌的非线性关系。
接下来,我们以预测股票的涨跌作为一个小例子。
假设你拥有大量历史数据,包含基本面和技术面、市场情绪、大盘趋势等数据。接着,我们可以使用训练集来构建决策树模型:
根节点
🔹公司基本面改善(例如,过去一个季度的净利润增长>10%)
继续分析
不继续分析
第一层节点
🔹技术指标符合预期(例如,RSI<30表示超卖)
继续分析
不继续分析
第二层节点
🔹市场情绪积极(例如,新闻情绪指数>0.7,市场参与者普遍看好)
继续分析
不继续分析
第三层节点
🔹大盘趋势向好(例如,主要指数的移动平均线呈上升趋势)
继续分析
不继续分析
最终预测
如果满足所有条件,预测该股票在未来一段时间内有较大概率上涨,因此可以考虑买入。
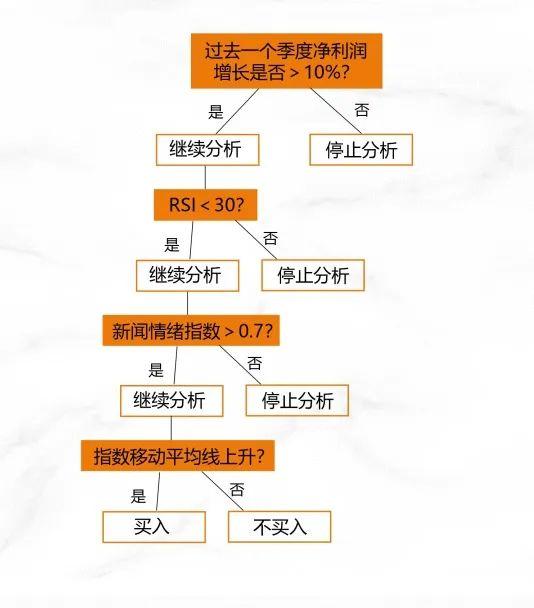
这个决策树的例子展示了在量化交易中如何结合各项指标做出投资决策,每个节点的决策依据都可以通过历史数据进行验证和优化,以确保模型的有效性。当然,这只是一个简单的示例。在实际操作中,机器处理的数据和构建的模型要复杂得多。
最后,学以致用,让决策树帮助小岩做一个选择吧~
