
英伟达新芯片,困难重重
如果您希望可以时常见面,欢迎标星收藏哦~
来源:内容由半导体行业观察(ID:icbank)编译自semianalysis,谢谢。
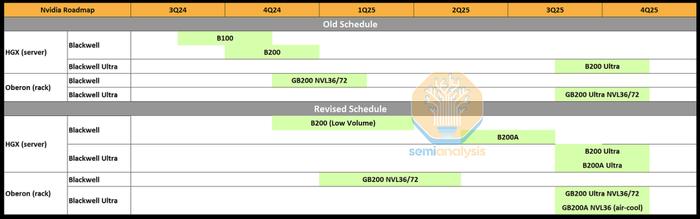
如昨日报道所说,Nvidia的Blackwell系列在实现大批量生产方面遇到了重大问题。这一挫折影响了他们2024年第三季度/第四季度以及明年上半年的生产目标。这影响了Nvidia的产量和收入。
简而言之,Nvidia的Hopper的使用寿命和出货量有所延长,以弥补大部分延迟。Blackwell的产品时间表有所推迟,但产量受到的影响比第一批出货时间表更大。
技术挑战也迫使Nvidia匆忙创建之前未计划的全新系统,这对数十家下游和上游供应商产生了巨大影响。今天,我们将讨论Nvidia面临的技术挑战、Nvidia修改后的时间表,并详细介绍Nvidia新系统(包括新的MGXGB200AUltraNVL36)的系统和组件架构。我们还将深入探讨这将对从客户到OEM/ODM再到Nvidia组件供应商的整个供应链产生的影响。
NvidiaBlackwell系列中技术最先进的芯片是GB200,Nvidia在系统层面的多个方面做出了积极的技术选择。72GPU机架的功率密度为每机架约125kW,而大多数数据中心部署的标准为每机架约12kW至约20kW。
这是前所未有的计算和功率密度,考虑到所需的系统级复杂性,这一提升极具挑战性。出现了许多与电力输送、过热、水冷供应链提升、快速断开漏水以及各种电路板复杂性挑战有关的问题。虽然这些问题让供应链上的一些供应商和设计师手忙脚乱,但大多数问题都是小问题,并不是Nvidia减少产量或重大路线图重做的原因。
影响出货量的核心问题与Nvidia的Blackwell架构设计直接相关。由于台积电的封装问题以及Nvidia的设计,原始Blackwell封装的供应有限。Blackwell封装是首款采用台积电CoWoS-L技术进行封装的大批量设计。
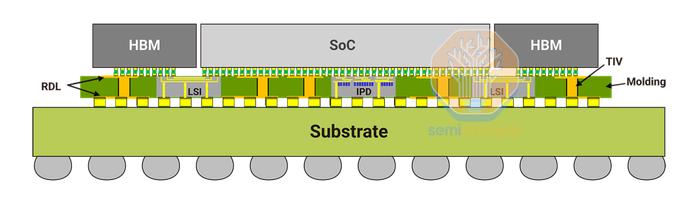
总结一下,CoWoS-L使用RDL中介层,其中嵌入了局部硅互连(LSI)和桥接芯片,以桥接封装上各种计算和内存之间的通信。相比之下,CoWoS-S表面上看起来要简单得多,是一块巨大的硅片。
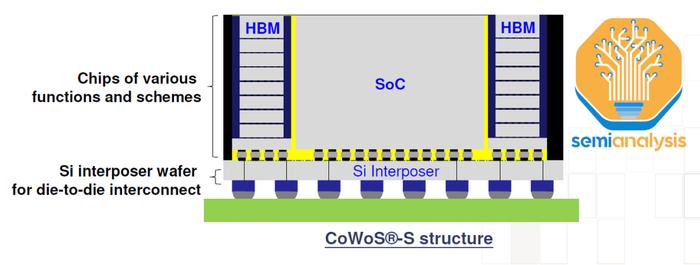
CoWoS-L是CoWoS-S的继任者,因为随着未来的AI加速器容纳更多的逻辑、内存和IO,CoWoS-S封装尺寸的增长和性能面临挑战。台积电已使用AMD的MI300将CoWoS-S缩小到约3.5倍光罩大小的中介层,但这是实际极限。有多个门控因素(gatingfactors),但关键因素是硅易碎,随着中介层变大,处理非常薄的硅中介层变得越来越困难。随着越来越多的光刻光罩拼接,这些大型硅中介层的成本也越来越高。
有机中介层可以解决这个问题,因为它们不像硅那样易碎,但它们缺乏硅的电气性能,因此无法为更强大的加速器提供足够的I/O。然后可以使用硅桥(无源或有源)来补充信号密度以进行补偿。此外,这些桥的性能/复杂性可以高于大型硅中介层。
CoWoS-L是一项复杂得多的技术,但它代表着未来。Nvidia和台积电的目标是制定一个非常积极的计划,每季度生产超过一百万块芯片。因此,出现了各种各样的问题。
一个问题与在中介层和有机中介层中嵌入多个精细凸块间距桥有关,这可能导致硅片、桥、有机中介层和基板之间的热膨胀系数(CTE)不匹配,从而引起翘曲。
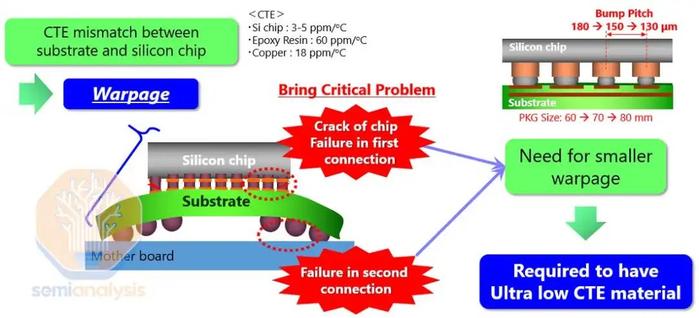
桥接芯片的放置需要非常高的精度,尤其是两个主计算芯片之间的桥接,因为它们对于支持10TB/s芯片间互连至关重要。据传,一个主要的设计问题与桥接芯片有关。这些桥接需要重新设计。还有传言称,Blackwell芯片顶部的几个全局布线金属层和凸块需要重新设计。这是延迟数月的主要原因。
还有一个问题是台积电总体上没有足够的CoWoS-L产能。过去几年,台积电建立了大量CoWoS-S产能,其中Nvidia占据了最大份额。现在,随着Nvidia迅速将其需求转移到CoWoS-L,台积电正在为CoWoS-L建造新的晶圆厂AP6,并在AP3转换现有的CoWoS-S产能。台积电需要转换旧的CoWoS-S产能,否则它将得不到充分利用,CoWoS-L的增长将更加缓慢。这种转换过程使得增长本质上非常不稳定。
结合这两个问题,很明显台积电无法像Nvidia所希望的那样供应足够的Blackwell芯片。因此,Nvidia几乎完全将他们的产能集中在GB200NVL36x2和NVL72机架规模系统上。除了一些初始较低产量外,带有B100和B200的HGX外形尺寸现在实际上已被取消。
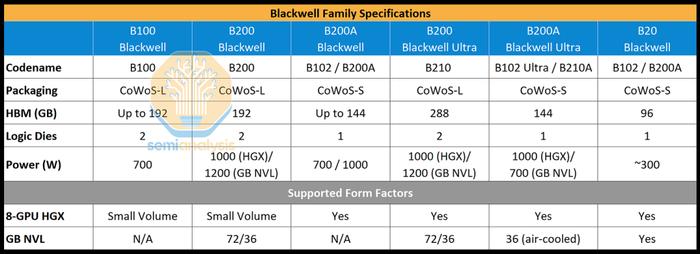
为了满足需求,Nvidia现在将推出一款基于B102芯片的BlackwellGPU,名为B200A。有趣的是,这款B102芯片也将用于中国版Blackwell,名为B20。B102是一个具有4个HBM堆栈的单片计算芯片。重要的是,这允许芯片封装在CoWoS-S上,而不是CoWoS-L,甚至是Nvidia的其他2.5D封装供应商,如Amkor、ASESPIL和三星。原始Blackwell芯片有大量专用于C2CI/O的海岸线区域,这在单片SOC中是不必要的。
B200A将用于满足低端和中端AI系统的需求。并将取代HGX8-GPU规格的B100和B200芯片。它将采用700W和1000WHGX规格,配备高达144GB的HBM3E和高达4TB/s的内存带宽。值得注意的是,这比H200的内存带宽要小。
说到BlackwellUltra,它是Blackwell的中期增强版,标准CoWoS-LBlackwellUltra将被称为B210或B200Ultra。BlackwellUltra包含高达288GB的12HiHBM3E内存刷新和高达50%的FLOPS性能增强。
B200A还将推出Ultra版本。值得注意的是,它不会升级内存,但芯片可能会重新设计以提高FLOPS。B200AUltra还引入了全新的MGXNVL36外形尺寸。B200AUltra也将采用HGX配置,就像原来的B200A一样。
对于HPC市场,我们认为GB200NVL72/36x2将继续最具吸引力,因为它在推理过程中对超过2万亿参数的模型具有最高的Performance/TCO。话虽如此,如果超大规模客户无法获得他们想要的GB200NVL72/36x2分配,他们可能仍需要购买MGXGB200ANVL36。此外,在功率密度较低或缺乏许可/无法获得水进行液体冷却改造的数据中心,MGXNVL36看起来更具吸引力。
HGXBlackwell服务器仍将被超大规模企业购买,因为它是可供出租给外部客户的最小计算单元,但其购买量将比以前少得多。对于小型机型,HGX仍然是性能/TCO最佳的机型,因为这些机型不需要大量内存,并且可以装入NVL8的单个内存连贯域中。
HGXBlackwell的性能/TCO在训练运行时也表现出色,训练工作量少于5,000个GPU。话虽如此,MGXNVL36是许多下一代模型的最佳选择,并且通常具有更灵活的基础设施,因此在许多情况下它是最佳选择。
对于neocloud市场,我们认为大多数客户不会购买GB200NVL72/36x2,因为寻找支持液体冷却或高功率密度Sidecar的主机托管提供商非常复杂。此外,由于GB200NVL72/36x2卷有限,大多数neocloud的排名通常比超大规模企业靠后。
我们认为,Coreweave等最大的Neocloud既拥有自己的自建数据中心/改造,又拥有较大的客户,它们将选择GB200NVL72/36x2。对于Neocloud市场的其他部分,大多数将选择HGXBlackwell服务器和MGXNVL36,因为这些服务器可以仅使用空气冷却和较低功率密度机架进行部署。目前,大多数Neocloud部署都是针对Hopper的,功率密度为20kW/机架。我们认为Neocloud可以部署MGXGB200NVL36,因为这只需要40kW/机架的空气冷却。
通过使用冷通道封闭系统并跳过数据中心的行列,每机架40kW的部署并不困难。在NeoCloud规模上,NeoCloud运营商和NeoCloud客户实际上并不倾向于考虑其特定工作负载的TCO性能,而是试图采购当前最受炒作的产品。例如,大多数(如果不是全部)NeoCloud客户不使用FP8训练,而是选择bfloat16训练。对于在bfloat16上训练的小型LLM,A10080GB提供了更好的TCO性能。
由于Meta的LLAMA模型正在推动许多企业和Neoclouds的基础设施选择,因此最相关的部署单元是能够适应Meta的模型。LLAMA3405B不适合单个H100节点,但勉强适合H200(该模型可以量化,但质量损失很大)。由于405B已经处于H200HGX服务器的边缘,下一代MoELLAMA4肯定不适合BlackwellHGX的单个节点,从而极大地影响每TCO的性能。
因此,对于推动初创企业和企业部署的最有用的开源模型的微调和推理,单个HGX服务器的性能/TCO会更差。我们对MGXB200AUltraNVL36的估计价格表明HGXB200A不太可能畅销。Nvidia有多种强大的动机来稍微降低利润率以推动MGX,因为他们用自己的网络更高的附加率来弥补这一点。
MGXGB200AUltraNVL36的架构
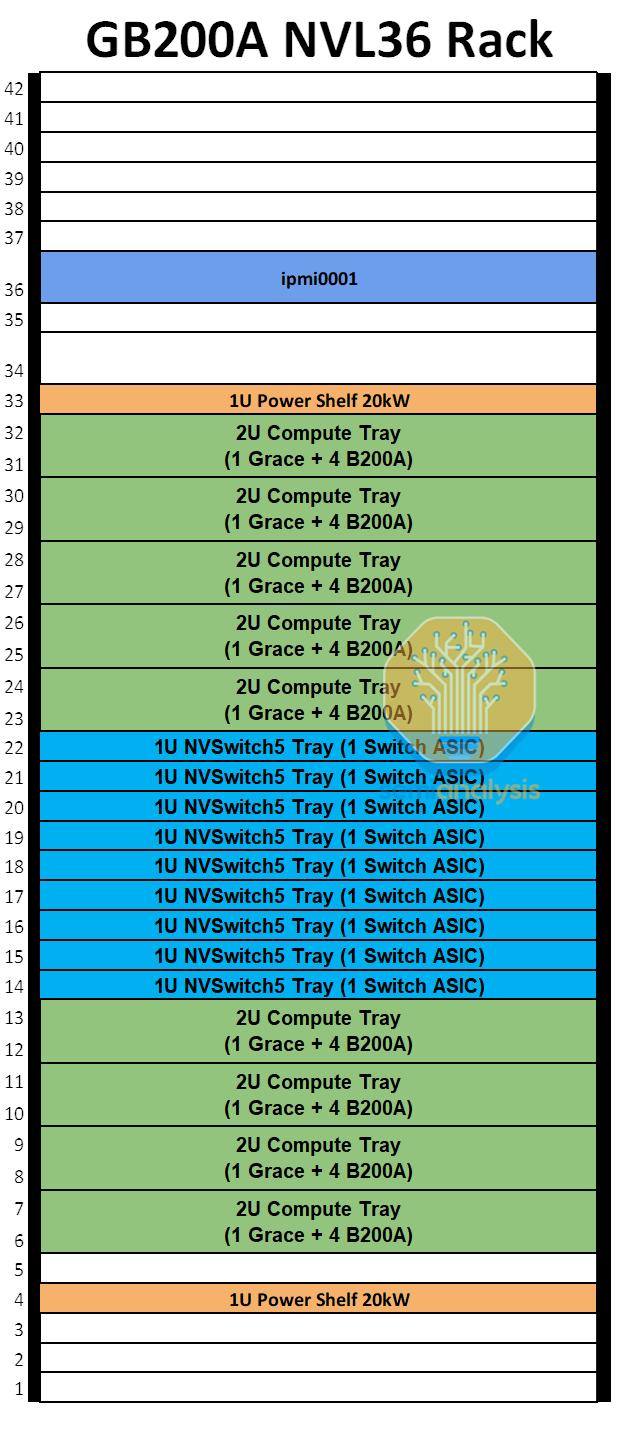
MGXGB200ANVL36SKU是一款完全风冷的40kW/机架服务器,将有36个GPU通过NVLink完全互连。每个机架将有9个计算托盘和9个NVSwitch托盘。每个计算托盘为2U,包含一个GraceCPU和四个700WB200ABlackwellGPU,而GB200NVL72/36x2则有两个GraceCPU和四个1200WBlackwellGPU。
MGXNVL36设计的CPU与GPU比例仅为1:4,而GB200NVL72/36x2的比例为2:4。此外,每个1UNVSwitchTray只有一个交换机ASIC,每个交换机ASIC的带宽为28.8Tbit/s。
由于每机架仅40kW,MGXNVL36可以采用空气冷却。虽然大多数数据中心和当前的H100部署仅为20kW/机架,但40kW/机架H100部署也并不罕见。这是通过跳过数据中心的行并利用冷/热通道遏制来实现的。部署40kWMGXNVL36机架时可以应用同样的技术。这使得现有数据中心运营商可以非常轻松地部署MGXNVL36,而无需重新设计其基础设施。
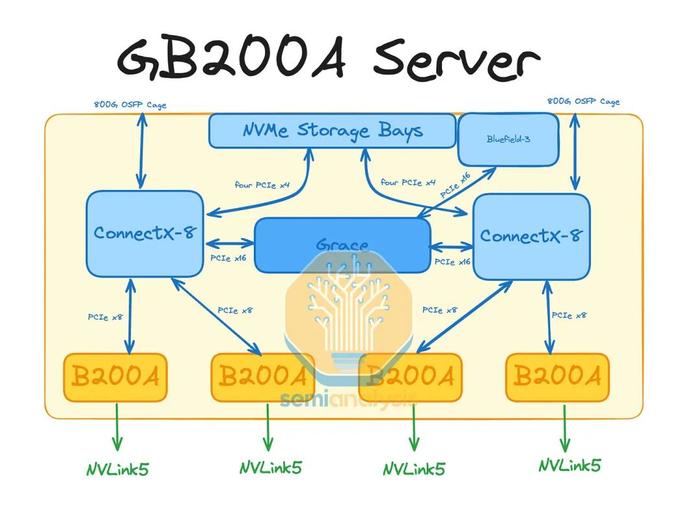
与GB200NVL72/36x2不同,四个GPU与一个CPU的比例更高,这意味着它将无法使用C2C互连,因为每个GPU获得的C2C带宽将是GB200NVl72/36x2的一半。相反,将利用集成的ConnectX-8PCIe交换机来允许GPU与CPU通信。此外,与所有其他现有AI服务器(HGXH100/B100/B200、GB200NVL72/36x2、MI300)不同,每个后端NIC现在将负责两个GPU。这意味着即使ConnectX-8NIC设计可以提供800G的后端网络,每个GPU也只能访问400G的后端InfiniBand/RoCE带宽。
在GB200NVL72/36x2上,通过ConnectX-8后端NIC,每个GPU可以访问高达800G的带宽。
对于参考设计,GB200ANVL36将每个计算托盘使用一个Bluefield-3前端NIC。与GB200NVL72/36x2每个计算托盘使用两个Bluefield-3相比,这是一种更合理的设计。即使对于MGXNVL36,我们仍然认为许多客户不会选择使用任何Bluefield-3,而是选择在超大规模的情况下使用自己的内部NIC或使用通用前端NIC,例如ConnectX-6/7。
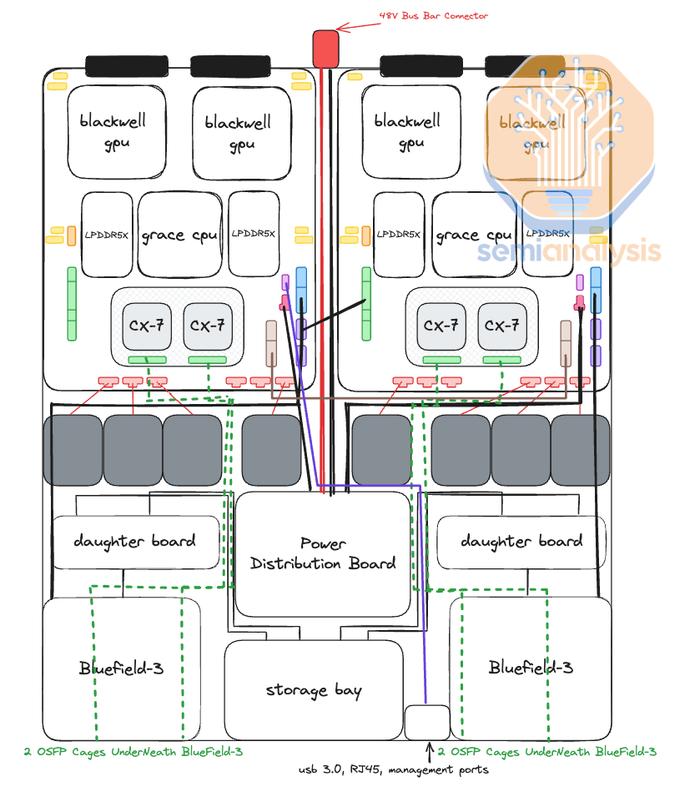
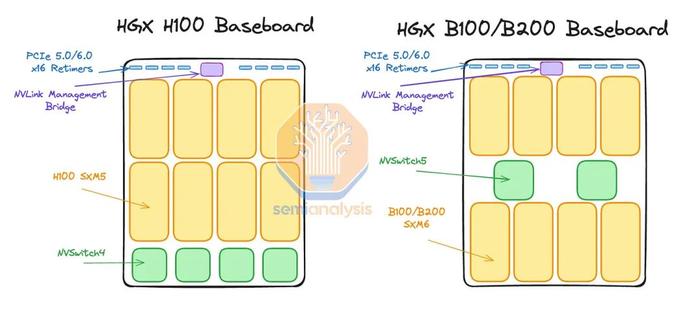
GB200NVL72/NVL36x2计算托盘的核心是Bianca板。Bianca板包含两个BlackwellB200GPU和一个GraceCPU。每个计算托盘都有两个Bianca板,这意味着每个计算托盘总共有两个GraceCPU和四个1200WBlackwellGPU。
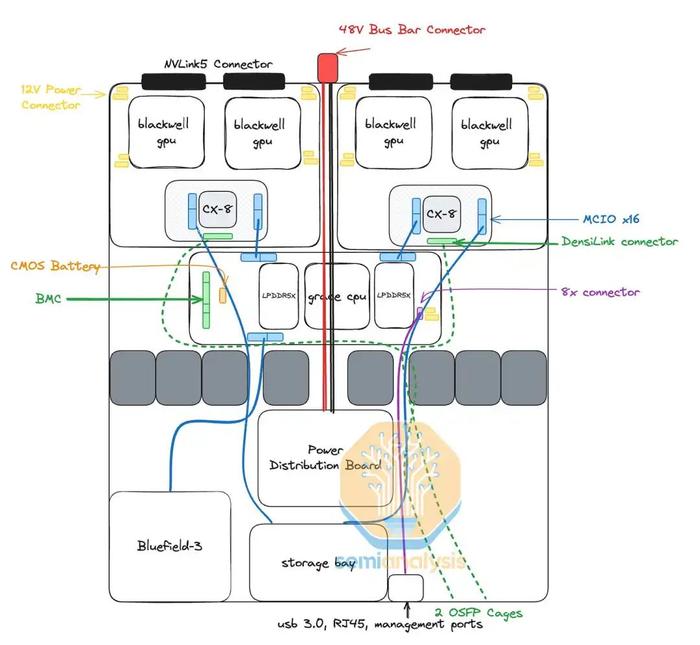
在MGXGB200ANVL36上,CPU和GPU将位于不同的PCB上,类似于HGX服务器的设计。与HGX服务器不同,我们认为每个计算托盘的4个GPU将细分为两个2-GPU板。每个2-GPU板将具有与Bianca板类似的MirrorMezz连接器。这些MirrorMezz连接器将用于连接到ConnectX-8夹层板,该夹层板将ConnectX-8ASIC及其集成PCIe交换机连接到GPU、本地NVMe存储和GraceCPU。
通过将ConnectX-8ASIC置于非常靠近GPU的位置,这意味着GPU和ConnectX-8NIC之间无需重定时器。这与HGXH100/B100/B200不同,后者需要重定时器从HGX基板连接到PCIe交换机。
由于GraceCPU和BlackwellGPU之间没有C2C互连,因此GraceCPU也位于一个完全独立的PCB上,称为CPU主板。该主板将包含BMC连接器、CMOS电池、MCIO连接器等。
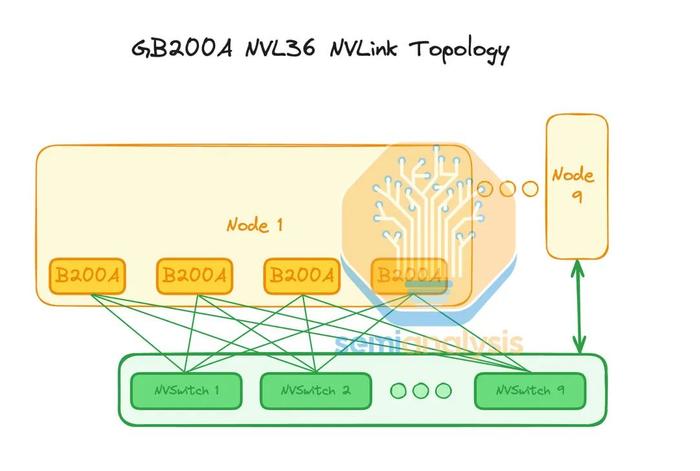
每个GPU的NVLink带宽将为每方向900Gbyte/s,与GB200NVL72/36x2相同。以每FLOP为基础,GPU到GPU带宽大幅增加,这使得MGXNVL36适合某些工作负载。
由于只有1层交换机连接36个GPU,因此仅需9个NVSwitchASIC即可提供无阻塞网络。此外,由于每个1U交换机托盘只有一个28.8Tbit/sASIC,因此空气冷却非常容易。25.6Tbit/s1U交换机(如Quantum-2QM9700)已经很容易通过空气冷却。虽然Nvidia可以通过保留带有2个NVSwitchASIC的交换机托盘来实现NVL36x2设计,但这会增加成本,并且由于前OSFPNVLink笼阻塞气流,可能使空气冷却变得不可能。
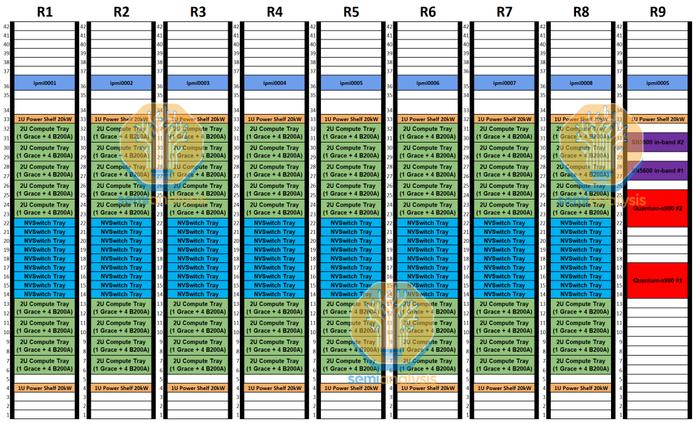
在后端网络上,由于每个计算托盘只有两个800G端口,我们认为它将使用2轨优化的行尾网络。每八个GB200ANVl36机架将有两个Quantum-X800QM3400交换机。
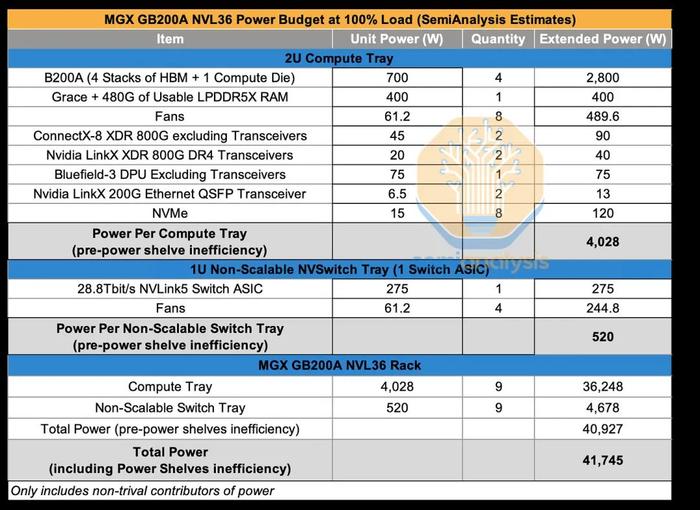
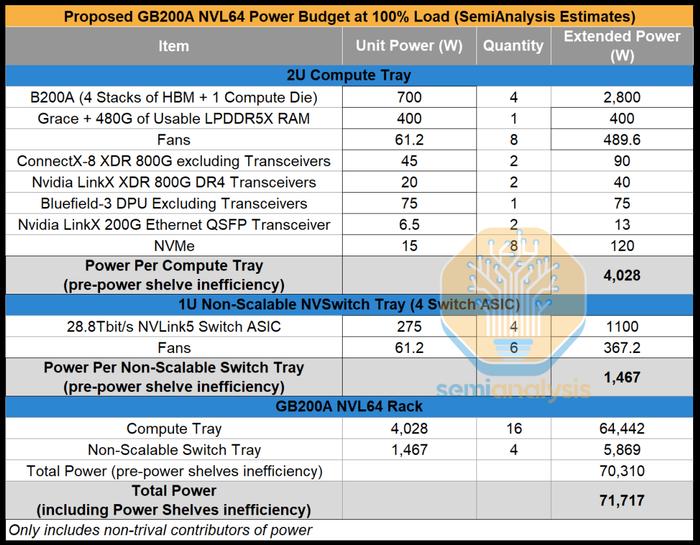
我们估计,每GPU700W的功耗,GB200ANVL36很可能每机架40kW左右。2U计算托盘将需要大约4kW的功率,但每2U空间4kW的空气冷却散热将需要专门设计的散热器和高速风扇。

我们将在本文后面讨论这方面的散热挑战,但这对于Nvidia在MGXNVL36设计上来说是一个重大风险。
MGXGB200ANVL36的挑战
对于GB200NVL72/NVL36x2,唯一不使用Connect-X7/8后端NIC的客户是亚马逊。正如我们在GB200架构分析中所讨论的那样,这已经带来了重大的工程挑战,因为将不会出现ConnectX-7/8或Bluefield-3,这两者都具有集成的PCIe交换机。因此,需要Broadcom或AsteraLabs的专用PCIe交换机将后端NIC连接到CPU、GPU和本地NVMe存储。这会消耗额外的电力并增加BoM成本。
在SemiAnalysisGB200组件和供应链模型中,我们细分了所有组件供应商的份额、数量和ASP,包括PCIe交换机。由于GB200ANVL36完全采用风冷,因此在2U机箱前端除了PCIe规格NIC之外还配备专用PCIe交换机,这将大大增加热工程挑战。
因此我们认为,基本上不可能有人能在GB200ANVL36上做定制后端NIC。
由于GraceCPU和BlackwellGPU位于单独的PCB上,我们相信也可能有x86+B200ANVL36版本。由于许多ML依赖项都是针对x86CPU编译和优化的,这可能是此SKU的额外优势。此外,与Grace相比,x86CPU平台提供更高的峰值性能CPU。不幸的是,对于愿意提供x86版本的OEM来说,将面临散热挑战,因为CPU的功耗大约高出100瓦。我们相信,即使Nvidia提供x86B200ANVL36解决方案,他们也会推动大多数客户转向GB200ANVL36解决方案,因为它可以销售GraceCPU。
GB200ANVL36的主要卖点是它是一款每机架40kW的风冷系统。对客户的主要吸引力在于,许多客户仍然无法支持每机架~125kWGB200NVL72(或36x2,两个机架超过130kW)所需的液体冷却和电源基础设施。
没有任何液体冷却意味着与GB200NVL72/36x2相比,散热解决方案将简化整体散热解决方案,基本上归结为散热器(3DVaporChamber,3DVC)和一些风扇。然而,鉴于GB200ANVL36的计算托盘使用的是2U机箱,3DVC设计将需要进行大量调整。
TDP为700W的H100目前使用4U高的3DVC,而1000W的H200使用6U高的3DVC。相比之下,2U机箱中TDP为700W的MGXB200ANVL36则受到很大限制。我们认为需要一个水平扩展成阳台状的散热器,以增加散热器的表面积。
除了需要更大的散热器外,风扇还需要提供比GB200NVL72/36x22U计算托盘或HGX8GPU设计的风扇更大的气流。我们估计,在40kW机架中,总系统功率的15%到17%将分配给内部机箱风扇。因此,GB200ANVL36的TUE数值(一种更好地表示空气冷却和液体冷却之间的能效增益的指标)将比GB200NVL72/NVL36高得多。
即使对于HGXH100等风冷服务器,我们认为风扇也只消耗系统总功率的6%到8%。由于MGXGB200ANVL36需要大量风扇功率才能工作,因此这种设计效率极低。此外,这种设计也有可能行不通,Nvidia就必须重新设计,尝试制作3U计算托盘或缩小NVLink世界大小。
在讨论GB200ANVL36的硬件子系统和组件变化(这些变化会影响供应链中的众多参与者)之前,让我们先讨论一下GB200ANVL64。
Nvidia为何取消GB200ANVL64
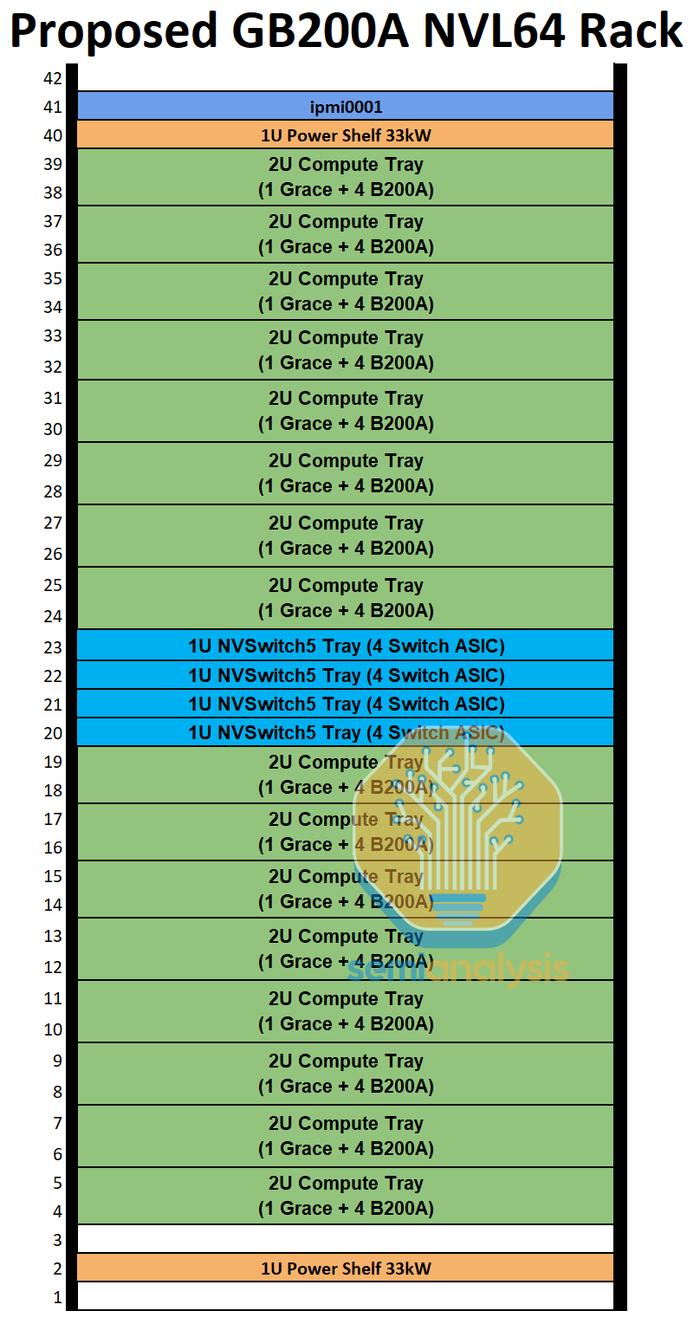
在Nvidia推出MGXGB200ANVL36之前,他们也在试验一种风冷NVL64机架设计。这款完全风冷的60kW机架将有64个GPU通过NVLink完全互连。我们对这个提议的SKU进行了广泛的工程分析,由于下面讨论的各种问题,我们认为这款产品不可行,不会出货。
在建议的NVL64SKU中,有16个计算托盘和4个NVSwitch托盘。每个计算托盘为2U,包含一个GraceCPU和四个700WBlackwellGPU,就像MGXGB200ANVL36一样。交换机NVSwitch托盘是进行重大修改的地方。Nvidia并没有将GB200的每个托盘两个NVSwitch减少到每个托盘一个NVSwitch,而是尝试将其增加到四个交换机ASIC。

尽管Nvidia提出的设计方案称NVL64将是60kW机架,但我们估算了功率预算,认为下限更接近每机架70kW。无论哪种方式,仅使用空气冷却每机架60kW或70kW都是疯狂的,通常需要后门热交换器,但这破坏了风冷机架架构的意义,因为仍然依赖于液体冷却供应链,并且这种解决方案仍然需要对大多数数据中心进行设施级改造,以便将设施水输送到后门热交换器。
另一个非常成问题的散热问题是NVSwitchTray在单个1U机箱中配备四个28.8Tbit/s交换机ASIC,需要近1,500W的散热。1U机箱的散热量为1,500W本身并不疯狂,但一旦考虑到冷却挑战,就会发现这很疯狂,因为从交换机ASIC到背板连接器的Ultrapass跨接电缆会阻挡大量气流。
鉴于风冷MGXNVL机架正以极快的速度进入市场,而Nvidia试图在设计开始后仅6个月内发货产品,对于工程资源已经捉襟见肘的行业来说,设计新的交换机托盘和供应链是相当困难的。
拟议的GB200ANVL64的另一个主要问题是,每个机架有64个800G后端端口,但每个XDRQuantum-X800Q3400交换机有72个800G下行端口,这两者之间的端口不匹配。这意味着,采用轨道优化的后端拓扑会浪费端口,每个交换机都有额外的16个800G端口闲置。昂贵的后端交换机上有空端口会严重损害网络性能/TCO,因为交换机价格昂贵,尤其是高基数模块化交换机,如Quantum-X800。
此外,在同一个NVLink域内使用64个GPU并不理想。从表面上看,这可能听起来很棒,因为它是2的偶数倍——非常适合不同的并行化配置,例如(张量并行TP=8、专家并行EP=8)或(TP=4、完全分片数据并行FSDP=16)。不幸的是,由于硬件不可靠,Nvidia建议每个NVL机架至少保留一个计算托盘,以便GPU离线进行维护,从而用作热备用。
如果每个机架中没有至少一个计算托盘处于热备用状态,那么即使机架上有一个GPU发生故障,其影响范围也会导致整个机架被迫停止服务相当长一段时间。这类似于8-GPUHGXH100s服务器上的情况,服务器上只要有一个GPU发生故障,就会迫使所有8个H100停止服务,无法继续为工作负载做出贡献。
保留至少一个计算托盘作为热备用,每个机架上只有60个GPU参与工作负载。虽然64是一个更合适的数字,因为它有2、4、8、16和32作为公因数,可以实现更好的并行组合,但60就不行了。
这就是为什么在NVL36*2或NVL72配置中在GB200上总共选择72个GPU是非常慎重的-它允许两个计算托盘处于热备用状态,从而使用户每个机架有64个GPU为工作负载做出贡献。
GB200ANVL36可让一个计算托盘处于热备用状态,并以2、4、8、16作为并行方案的共同因素,从而在实际工作负载中实现更高的可靠性。
由此可见,Blackwell最初推出MGXGB200A的延迟对OEM、ODM和零部件的影响。我们预计GB200NVL72/36x2的出货量/推出量会减少,B100和B200HGX的销量会大幅减少。相反,我们预计Hopper的出货量将在2024年第四季度至2025年第一季度增加。此外,下半年GPU的订单将从HGXBlackwell和GB200NVL36x2转移到MGXGB200ANVL36。
这将影响所有ODM和零部件供应商,因为出货/收入计划在2024年第三季度至2025年第二季度发生巨大变化。对每个供应商的影响程度还取决于供应商是GB200NVL72/36、MGXNVL36的赢家还是输家,以及他们是否在Hopper系列中占有很大的份额(从而受益于更长的Hopper生命周期)。
组件影响包括冷却、PCB、CCL、基板、NVLink铜背板内容、ACC电缆内容、光纤内容、BMC、电源内容等。
参考链接
https://www.semianalysis.com/p/nvidias-blackwell-reworked-shipment
点这里加关注,锁定更多原创内容