
大模型幻觉率排行:GPT-43%最低,谷歌Palm竟然高达27.2%
文章转载来源:机器之心
原文来源:机器之心

人工智能发展进步神速,但问题频出。OpenAI新出的GPT视觉API前脚让人感叹效果极好,后脚又因幻觉问题令人不禁吐槽。
幻觉一直是大模型的致命缺陷。由于数据集庞杂,其中难免会有过时、错误的信息,导致输出质量面临着严峻的考验。过多重复的信息还会使大模型形成偏见,这也是幻觉的一种。但是幻觉并非无解命题。开发过程中对数据集慎重使用、严格过滤,构建高质量数据集,以及优化模型结构、训练方式都能在一定程度上缓解幻觉问题。
流行的大模型有那么多,它们对于幻觉的缓解效果如何?这里有个排行榜明确地对比了它们的差距。
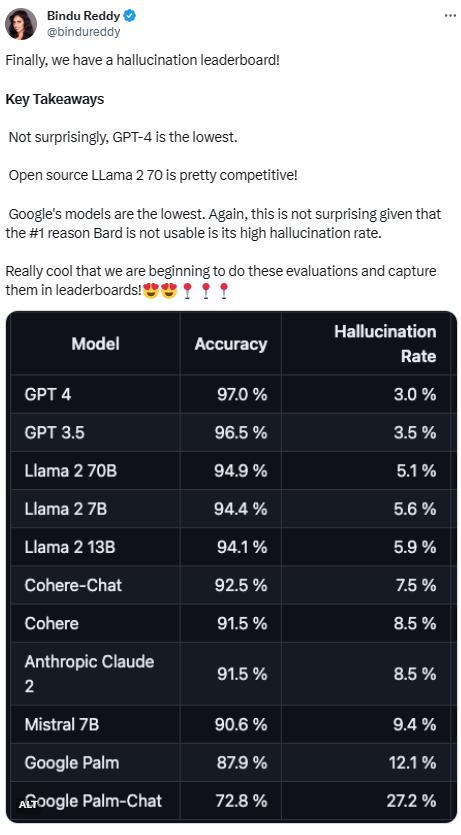
该排行榜由专注于AI的Vectara平台发布。排行榜更新于2023年11月1日,Vectara表示后续会随着模型的更新继续跟进幻觉评估。
项目地址:https://github.com/vectara/hallucination-leaderboard
为了确定这个排行榜,Vectara使用各种开源数据集对摘要模型进行了事实一致性研究,并训练了一个模型来检测LLM输出中的幻觉。他们使用了一个媲美SOTA模型,然后通过公共API向上述每个LLM输送了1000篇简短文档,并要求它们仅使用文档中呈现的事实对每篇文档进行总结。在这1000篇文档中,只有831篇文档被每个模型总结,其余文档由于内容限制被至少一个模型拒绝回答。利用这831份文件,Vectara计算了每个模型的总体准确率和幻觉率。每个模型拒绝响应prompt的比率详见「AnswerRate」一栏。发送给模型的内容都不包含非法或不安全内容,但其中的触发词足以触发某些内容过滤器。这些文件主要来自CNN/每日邮报语料库。
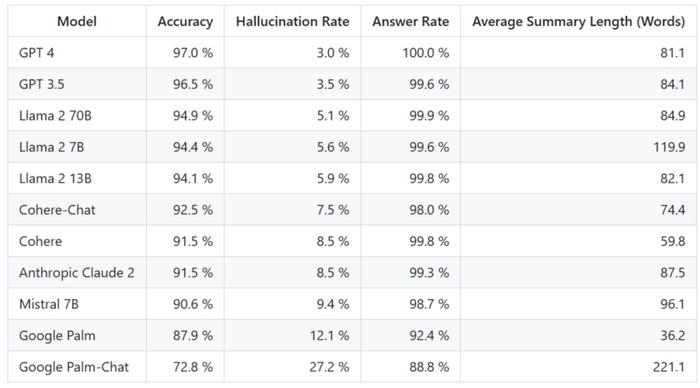
需要注意的是,Vectara评估的是摘要准确性,而不是整体事实准确性。这样可以比较模型对所提供信息的响应。换句话说,评估的是输出摘要是否与源文件「事实一致」。由于不知道每个LLM是在什么数据上训练的,因此对于任何特别问题来说,确定幻觉都是不可能的。此外,要建立一个能够在没有参考源的情况下确定回答是否是幻觉的模型,就需要解决幻觉问题,而且需要训练一个与被评估的LLM一样大或更大的模型。因此,Vectara选择在总结任务中查看幻觉率,因为这样的类比可以很好地确定模型整体真实性。
检测幻觉模型地址:https://huggingface.co/vectara/hallucination_evaluation_model
此外,LLM越来越多地用于RAG(RetrievalAugmentedGeneration,检索增强生成)管道来回答用户的查询,例如BingChat和谷歌聊天集成。在RAG系统中,模型被部署为搜索结果的汇总器,因此该排行榜也是衡量模型在RAG系统中使用时准确性的良好指标。
由于GPT-4一贯的优秀表现,它的幻觉率最低似乎是意料之中的。但是有网友表示,GPT-3.5与GPT-4并没有非常大的差距是令他较为惊讶的。
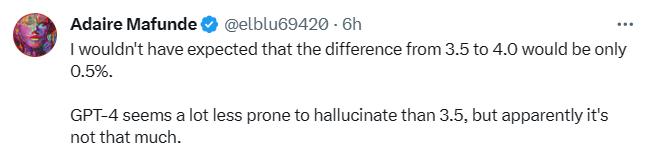
LLaMA2紧追GPT-4与GPT-3.5之后,有着较好的表现。但谷歌大模型的表现实在不尽人意。有网友表示,谷歌BARD常用「我还在训练中」来搪塞它的错误答案。

有了这样的排行榜,能够让我们对于不同模型之间的优劣有更加直观的判断。前几天,OpenAI推出了GPT-4Turbo,这不,立刻有网友提议将其也更新在排行榜中。

下次的排行榜会是怎样的,有没有大幅变动,我们拭目以待。
参考链接:
https://twitter.com/bindureddy/status/1724152343732859392
https://twitter.com/vectara/status/1721943596692070486