
OpenAI再次加塞砸场?谷歌展示自己才是AI灭霸
OpenAI为什么总要故意砸场,谷歌今天又给出了什么回应?
OpenAI又一次加塞砸场
这已经不是第一次了。OpenAI摆明了是要加塞,故意在谷歌发布会前一天发布自己的产品,砸直接竞争对手的场子,抢占媒体报道风头。因为是创业公司,OpenAI总能比谷歌更快作出反应,灵活安排活动时间。
他们上次这么做还是是2月份,谷歌发布了多模态大模型Gemini1.5Pro,直接将性能拉到支持百万Token的业界新高。但这并没有成为那天的焦点,因为OpenAI在同一天发布了文生视频工具Sora,诸多栩栩如生又极具想象力的AI视频随即成为了社交媒体上的爆款,抢尽了谷歌Gemini的几乎所有风头。
这一次OpenAI又搞突然袭击。谷歌I/O大会的日期是提前数月就宣布的,但OpenAI上周突然宣布在谷歌大会前一天召开发布会,在

昨天发布了最新大模型GPT-4o(o代表着Omnimodel全能模型),提前引爆了AI大模型的关注热度,再次打乱了谷歌即将发布AI新品的传播节奏。
GPT-4o不仅是完全免费的,而且覆盖了桌面与移动App,不仅性能大幅提升,而且可以综合处理文本、图片和音频,人机交互更加自然简单。举例来说,可以让GPT-4o加入网络会议,给用户记录发言总结概要。
GPT-4o具体有什么用?用户可以让GPT-4o处理眼前的问题,极大提升生产力,可以与AI实时语音对话,就像是与真人聊天一样自然流畅,AI处理反应已经达到人类的速度,甚至还可以理解用户的情绪,以相应的情感作出回应。
那么,面对OpenAI的故意撞车和抢占风头,谷歌在今天的I/O大会上又拿出了怎样的AI产品,是否带来了足够的震撼与新意?
Gemini1.5Pro支持两百万Token
谷歌I/O开发者大会今年已经进入了第16个年头,AI早已成为I/O大会的绝对乃至唯一的主角。谷歌CEO皮查伊更是在结束时宣布,整场发布会一共说了121次AI,引发了全场大笑。(这个梗是因为去年媒体统计谷歌在I/O上一共说了143次AI,今年谷歌干脆自己公布统计数字)。
虽然整场发布会都没有提及竞争对手,但谷歌CEO皮查伊从主题演讲一开始就开始秀谷歌的AI实力,宣布谷歌已经全面进入Gemini时代。他强调谷歌已经在AI领域投入了十多年时间,贯穿了AI的每一层:研究、产品、基础设施。

虽然AI新贵OpenAI在产品发布方面抢占了先发优势,但谷歌在研究论文、用户规模、产品数量以及算力方面都占据着压倒性优势,这也是OpenAI必须与微软结盟的直接原因,因为两家公司都不可能单独与谷歌掰手腕。
皮查伊还宣布,Gemini大模型已经覆盖了谷歌全平台的20亿用户产品,仅仅三个月时间就有100多万用户注册使用。而两个月前发布的原生多模型Gemini1.5Pro已经得到超过150万开发者的使用。
在性能方面,谷歌就是AI业界的灭霸。Gemini1.5Pro此前直接将Token(上下文处理)性能提升到了百万级别,全面压倒了受困于性能变慢的GPT-4.0Turbo。三个月后,谷歌在今天宣布改进版的Gemini1.5Pro全面开放给Gemini Advanced的用户,并且支持35种语言。

更为残暴的是,谷歌还将Gemini1.5Pro的上下文窗口处理性能直接翻倍到了200万(暂时只面向开发者提供),在这方面OpenAI只能望尘莫及。皮查伊宣布,这是朝着无限上下文的最终目标迈出的重要一步。
Gemini1.5Pro可以给用户带来怎样的实际体验?谷歌用Workspace办公组件展示了AI给生产力带来的巨大变化。举例来说,如果是通过Google Meets进行远程会议,哪怕用户无法参会,也可以让Gemini为自己录音并列出会议纪要。
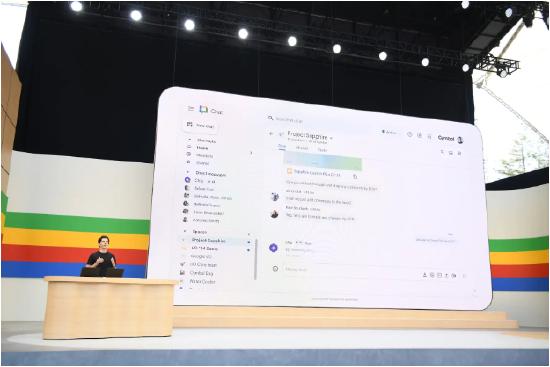
有了Gemini,Gmail邮箱就有了灵魂。代写邮件已经是基本操作了。用户可以让Gemini帮助自己整理和总结Gmail的海量邮件,根据最近的收据和信用卡账单邮件整理归纳出用户的消费支出,给出一份专业又具体的财务支出清单。
在电商时代,Gemini还能扮演智能管家的角色。用户甚至可以让Gemini自动在邮件中找到收据邮件,并进入商家平台申请退货,还能让快递上门取货。这一切都只需要用户向Gemini下达指令。Gemini1.5Pro从今天开始全面入驻Workspace Labs。
轻量AI模型Flash
Gemini模型家族的新品还不仅于此。谷歌DeepMind CEO哈撒比斯(Demis Hassabis)在主题演讲中介绍了Gemini的新成员:轻量、迅捷、高效的模型1.5Flash,以及未来AI助手Project Astra。
去年12月,谷歌发布了第一代原生多模型Gemini1.0,包括了Ultra、Pro以及Nano三个版本。三个月后谷歌发布了百万Token处理能力的Gemini1.5Pro。今天谷歌将Gemini1.5Pro处理能力提升到200万级别之外,还推出了轻量模型Gemini1.5Flash。
虽然Gemini1.5Flash的上下文处理能力同样达到了百万级别,但却比1.5Pro更为轻便迅速,针对低延迟和专注成本的任务进行了优化,更适合规模化构建。Gemini1.5Flash今天就会在通过谷歌AI Studio和Vertex AI两大平台向开发者提供。
Project
Astra是谷歌DeepMind打造的未来通用智能AI助手,也是对标OpenAI GPT-4o的产品。Astra不仅具备多模态处理,可以无缝应对文本图片视频等多媒体内容,还能以更为智能实时的方式与用户进行对话。
或许略微遗憾的是,OpenAI已经在昨天抢先发布了GPT-4o的类似功能,晚了一天亮相的Astra少了诸多惊喜和震撼,或许这就是OpenAI突然抢先发布的主要原因。因为谁先发布就占据了媒体报道的焦点。如果OpenAI在谷歌Astra之后发布GPT-4o,同样也会失去诸多传播魅力所在。
搜索更加人性与个性
从搜索到邮件,从地图到图片,再到办公组件,谷歌有着太多上亿乃至十亿用户级别的产品可以承载AI落地。横跨iOS与Android平台,移动与桌面两端的20亿+的用户规模,以及几乎覆盖所有领域的产品,更是谷歌AI技术落地的庞大产品军火库。
生成式AI在搜索领域的应用显然是最直接的用户体验。即便微软借助OpenAI试图弯道超车,但过去一年市场份额也只涨了不到一个百分点(目前3.64%)。而谷歌虽然市场份额减少了两个百分点,但目前全球市场占有率依然接近91%。
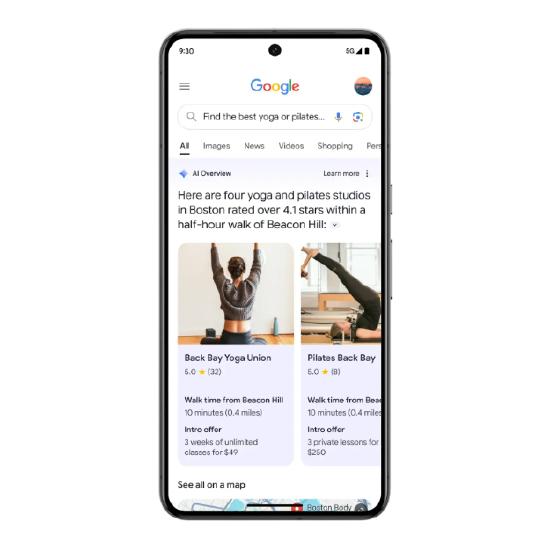
有了Gemini大模型的加持,谷歌搜索得以全面提升,提供一对一的解答。用户可以随心所欲的提问,无论是具体知识,还是寻求建议,谷歌搜索的AI Overviews都可以应答如流,不仅给出实际的回答,更提供信息来源。
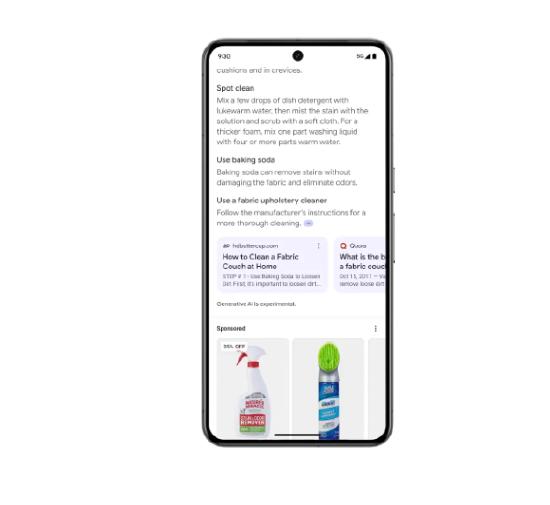
具体来说,用户搜索“如何清洗布质沙发”的问题,AI Overviews不仅会提供几种清洗沙发的方法,还会带来答案的信息来源,再附上清洗产品的链接(购买谷歌搜索广告的商家产品)。未来用户还可以根据自身需求,对AI Overview的回答进行个性化调整,提供更为简明扼要或者细节详尽的回答。

实际上,此前已经有不少用户已经通过Search Labs的实验功能体验到了AI Overviews功能。AI Overviews今天正式在美国市场推出,未来会逐步扩展到其他国家市场。谷歌预计,单是本周时间就会有数亿用户使用到AI Overviews,今年年底用户规模或将突破10亿级别。
AI功能全面落地手机端
虽然I/O主题演讲开始78分钟之后,谷歌才开始介绍Android平台的AI新功能,但这并不意味着Android在谷歌AI战略的重要性降低。实际上,移动端才是用户体验谷歌AI功能的最直接平台。
在今年年初三星手机推出谷歌AI技术加持的画圈搜索、全屏翻译等人性功能之后(三星国行版使用百度AI技术),半年时间全球已经有超过1亿设备搭载了谷歌画圈搜索功能。谷歌预计今年年底这一数字将翻一倍,达到两亿设备。

而且,得益于谷歌LearnLM模型,画圈搜索功能还有了更多的实际运用。从今天开始,画圈搜索将帮助学生做家庭作业,替代家教作用,帮助他们更好了解如何做题,而不仅仅是给出直接答案。这也是昨天OpenAI GPT-4o所展示的使用场景。
Gemini on Android是谷歌为Android平台推出的一系列人性化功能。有了这一功能,用户可以用对话的方式,在写邮件和发短信的过程中直接生成和发送个性化图片,可以在YouTube视频中直接寻找想要的内容,在PDF中迅速找到自己所需的内容,而不用再自己费力浏览搜索。
在Android设备端上的Gemini Nano模型还带来了TalkBack和反诈功能,这两大功能都会在今年晚些时候发布。有了TalkBack功能,失明或者弱视患者可以通过手机摄像头,听AI描述眼前的世界,即便没有网络也可以使用。
智能反诈功能则可以根据聊天中的敏感内容(例如骗子要求进行银行转账,询问个人密码时),即使弹出警告窗,提醒用户这可能是诈骗电话。由于Gemini Nano完全是基于设备端,用户不用担心自己的通话内容被监听。
AI图片工具Ask Photos
Google Photos是谷歌在2015年发布的云相册服务,iOS和Android用户可以将自己的所有照片和视频都存入这个云端相册,并在任何联网设备上接入。目前Google Photos每天上传的照片与视频数量超过了60亿。
海量的图片如何整理和搜索,一直是个用户体验难题。现在谷歌推出了AI工具Ask Photos之后,用户可以轻松寻找出任何想要的图片,回忆过去的点滴记忆,再也不担心找不到或者花很长时间才能找到想要的照片。
举例来说,用户想回忆女儿的成长过程,可以向Google Photos提问“女儿是什么时候学会游泳的?”。谷歌就可以迅速展示小女孩最早开始游泳的照片,让用户看到这个温暖的记忆判断。
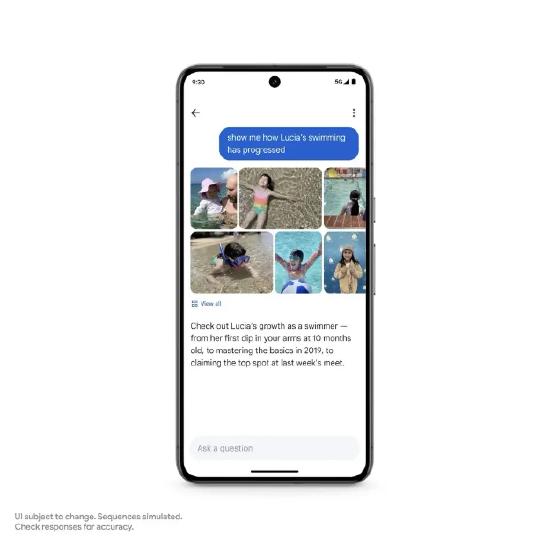
AI甚至还可以帮助用户进行归纳总结。用户可以提出更为复杂的问题,“女儿的游泳技能是怎么提升的?”谷歌不仅会搜索相关的女儿游泳照片,还可以提供一段简单的说法,帮助用户更好的回忆女儿的游泳技能的提升过程。
文生视频模型叫板Sora
谷歌DeepMind的文生视频模型Veo是今天最为惊艳的产品之一。三个月前OpenAI用一波Sora生成视频抢尽了谷歌Gemini1.5Pro的风头,今天谷歌拿出了自己的产品回击Sora。
虽然比OpenAI的Sora晚了三个月发布,但是Veo带来的视频却更为高清流畅自然,看起来更为真实(当然三个月时间,Sora也可能有了重大更新)。Veo可以生成一分钟以上的1080p分辨率视频,可以理解“延时摄影”以及“航拍风景”等术语,展示多种电影与视频风格。

为了展示Veo在电影行业的潜力,谷歌还邀请了出演过《火星救援》等诸多作品的好莱坞电影人格罗夫(Donald Glover)进行产品试用。此次大会上也展示了格罗夫创意工作室Gilga使用Veo制作的数个看起来极具大片风格的视频片段。
谷歌宣布,Veo从今天开始向特定创作者提供内测,并在未来整合到YouTube Shorts和其他产品中。无论什么AI功能,苹果都有海量用户的产品可以承载。YouTube Shorts是谷歌对标TikTok的短视频服务,发布三年时间之后,目前月活用户已经突破了23亿(当然这是得益于YouTube的庞大体量)。显然,一旦Veo进入YouTube Shorts,其用户规模将是Sora所无法想象的。
此外,谷歌还展示了DeepMind最新的文生图片模型Imagen3,这是对应OpenAI的DALL.E3。谷歌在发布会上展示了Imagen3生成的数张高清图片,据称具有更好的自然语言理解,更好理解文本背后的意图,带来更为细节、更强渲染能力的图片。Imagen3也从今日开始通过谷歌的AI图片工具ImageFX向特定创作者提供测试,未来会整合到谷歌的机器学习平台Vertex AI中。

文本:一个短发胡须男子微笑着看着镜头。背景模糊,可以看到浅影的树木和建筑。

文本:一只手握着一个泥塑小鸟雕像,另外一只手拿着刻刀。可以看到雕刻着的围巾。他的双手沾满粘土。用一张近摄的单反图片突出纹理和雕刻质感。
此外,谷歌还推出了面向音乐爱好者的Music AI Sandbox,用生成式AI音乐模型Lyria,帮助音乐人更为便捷地创作出不同风格的音乐作品。这些功能也会整合进YouTube平台。
第六代TPU芯片Trillium
谷歌在AI领域的强大优势不仅体现在大模型,还体现在他们在AI处理器领域的实力。过去六年时间,行业对机器学习运算能力的需求增长了100万部,而且每年都会增长10倍。而谷歌在这方面则站在了行业价值链的顶端。

早在2016年谷歌就推出了为AI训练设计的第一代TPU(定制张量处理单元)。Gemini大模型完全是在自己的第四代和第五代TPU上进行训练与服务的,谷歌甚至还向Anthropic等其他AI公司提供了TPU训练服务。相比之下,OpenAI目前还只能依靠微软获得训练能力。
今天谷歌在I/O大会上还发布了第六代TPU处理器Trillum,计划今年晚些时候向云服务客户推出,Trillium的每个芯片处理速度比前一代TPU v5e提升了4.7倍。
除了TPU之外,谷歌上个月还发布了第一代基于ARM架构的AI CPU Axiom,并且通过CPU和GPU来支持AI工作负载。皮查伊表示,明年谷歌云将成为首批搭载英伟达Blackwell GPU的服务商。
自OpenAI在2022年底发布ChatGPT起,这场AI军备禁赛已经开始了一年多时间,除了OpenAI和谷歌,微软、Meta、华为等全球主要科技巨头和Anthropic等创业公司都已经投入到这场未来争夺战中。而OpenAI和谷歌则是其中最受瞩目的两大领先者。
虽然OpenAI凭借创业公司的灵活专注优势,屡屡抢占先发优势,每次都能领先谷歌一步发布新品,获得行业一片叫好,但谷歌依然有着自己的独有优势所在。作为最早投入AI研究的科技巨头,谷歌最大的竞争优势不仅在于产品的研发,还包括了基础设施和运算能力,在于庞大的谷歌应用矩阵与数十亿的用户级别。
在昨天OpenAI再次加塞抢发GPT-4o之后,今天谷歌全面展示了自己在AI领域的全方位优势,展示了AI给自己全平台服务与产品带来的体验提升。今天,AI灭霸戴上了手套,打了一个响指。