
AMD向Arm芯片开炮,英伟达回击
如果您希望可以时常见面,欢迎标星收藏哦~
来源:内容由半导体行业观察(ID:icbank)编译自theregister,谢谢。
AMD声称,其当前的数据中心硅片的速度已经比Nvidia的GraceCPU超级芯片快两倍多,效率高达2.75倍。
该芯片设计公司是在上周发布的自己的测试之后做出上述断言的,在测试中该公司考虑了Nvidia的2022GraceCPU超级芯片。
该产品结合了一对CPU芯片,每个芯片包含72个ArmNeoverseV2内核,通过900GB/秒的NVLink芯片间互连将它们连接起来,并支持高达960GB的高速LPDDR5x内存。不过,AMD似乎正在测试480GB版本。
需要明确的是,这不是Nvidia的Grace-HopperSuperchip(GH200),它结合了单个GraceCPU、高达480GB的LPDDR5x和144GBH100GPU芯片。
与Nvidia的GraceCPU相比,AMD测试了运行Epyc4Genoa(9654)和Bergamo(9754)的单插槽和双插槽系统,每个系统都配备768GB的DDR54800MT/秒内存。
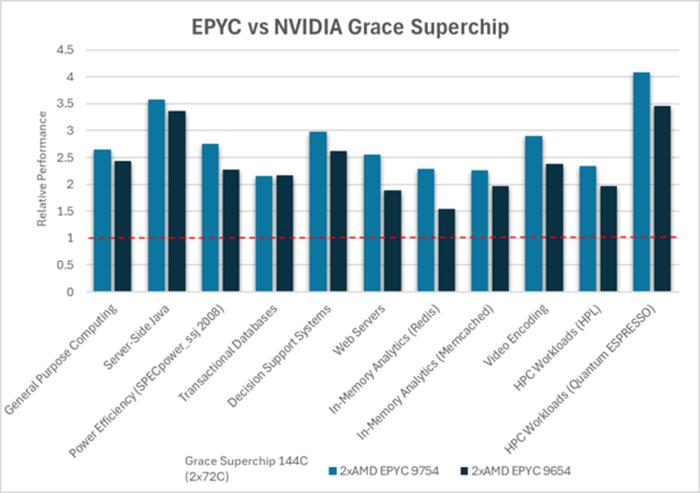
在十种工作负载)中,AMD宣称其套件的性能是Nvidia芯片的1.5倍到4倍。
值得一提的是,与任何供应商提供的基准测试一样,读者请谨慎对待。
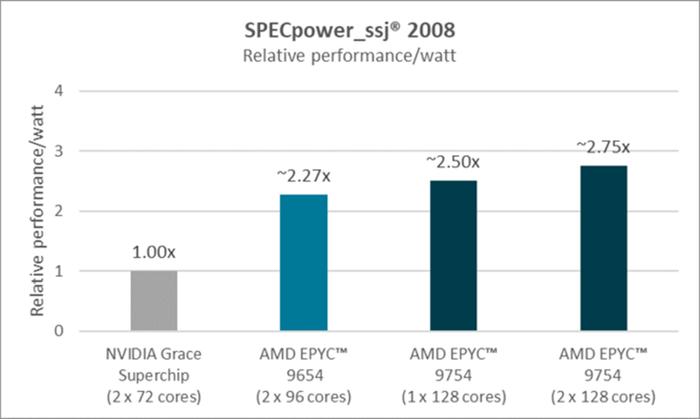
在SPECpower-ssj2008基准测试中,AMD声称单个128核Epyc9754的每瓦性能比Nvidia基于ArmNeoverseV2的芯片高出约2.5倍,而一对BergamoEpycs将这一优势提升至2.75倍。
对于那些一直关注Grace开发的人来说,这一切都不应该感到惊讶——尽管情况并不像AMD让你相信的那么简单。
正如TheNextPlatform在二月份报道的那样,斯托尼布鲁克大学和布法罗大学的研究人员比较了从多个科研机构和一个云构建商收集的Nvidia的GraceCPU超级芯片和几台x86处理器的性能数据。
当然,这些测试大多以HPC为中心,包括Linpack、高性能共轭梯度法(HPCG)、OpenFOAM和Gromacs。虽然Grace系统的性能在测试中差异很大,但最差的情况下,它介于英特尔的Skylake架构(大约2015年)和其IceLake(2019年)技术之间,击败了AMD的Milan(自2021年开始),与2023年初推出的XeonMax相差无几。
研究结果表明,在正确的基准上,AMD最强大的Genoa和BergamoEpyc处理器可能会击败Nvidia的首款数据中心CPU。
但正如我们之前提到的,所有这些都取决于工作负载。在其GraceCPUSuperchip数据表中,Nvidia显示,该芯片的性能是双96核Epyc9654s(与AMD测试中使用的GenoaEpyc相同)的90%到2.4倍,并且在各种云和HPC服务中的吞吐量高达三倍。
虽然传统的CPU较量可能有意义——归根结底,Grace和Epyc都是数据中心CPU平台——但我们还没有真正看到Nvidia的GraceCPU超级芯片在HPC应用之外得到广泛部署,通常是为了准备更大规模部署下一代GH200芯片。英国的Isambard-3和Isambard-AI超级计算机就是该战略付诸实践的典范。
Nvidia自己将CPU超级芯片宣传为旨在“处理海量数据以最大程度地提高能源效率”的芯片,并特别提到了人工智能、数据分析、超大规模云应用程序和HPC应用程序。
此外,在GH200配置中,大部分计算都由GPU完成-Grace主要为加速器提供数据。显然,Nvidia认为Grace及其NVLink-C2C互连能够胜任这项任务,因为它选择在即将推出的GB200超级芯片上重复使用CPU,我们在Nvidia的GTC开发者大会上回顾了这款芯片。
可以说,这就是Nvidia需要Grace做的一切,才能取得成功。这也解释了为什么这家加速冠军已经开始着手开发其继任产品。
我们必须想象,将Grace-Grace与第四代Epyc进行交叉购买的人数(当然,在HPC领域之外)是一个相当短的名单。老实说,我们更有兴趣看到GH200与AMD的MI300AAPU之间的正面交锋。
AMD最后讨论了Arm兼容性——这个主题值得进行更多基准测试。
我们感觉AMD的测试可能只是为了消除人们对x86失去动力和Arm接管的担忧。
Arm对HPC社区或云来说并不是新事物,这些市场远没有拒绝这种架构。事实上,现在每个主要的美国云提供商都拥有自己的ArmCPU。
但如果这真的是关于AMD的Zen4和Zen4c内核与Arm的NeoverseV2架构的比较,那么与亚马逊网络服务的Graviton4进行比较会更有用。
Graviton4于2023年末发布,基于与Grace相同的NeoverseV2核心,但拥有96个核心并支持标准双插槽配置和12个DDR4通道,而不是Grace的焊接LPDDR5x模块。
运行Graviton4的实例已在预览版中推出数月,并于上周正式推出。或许更重要的是,AWS同时提供基于Epyc4和Graviton4的实例,这使得人们将两者进行比较的可能性大大提高。
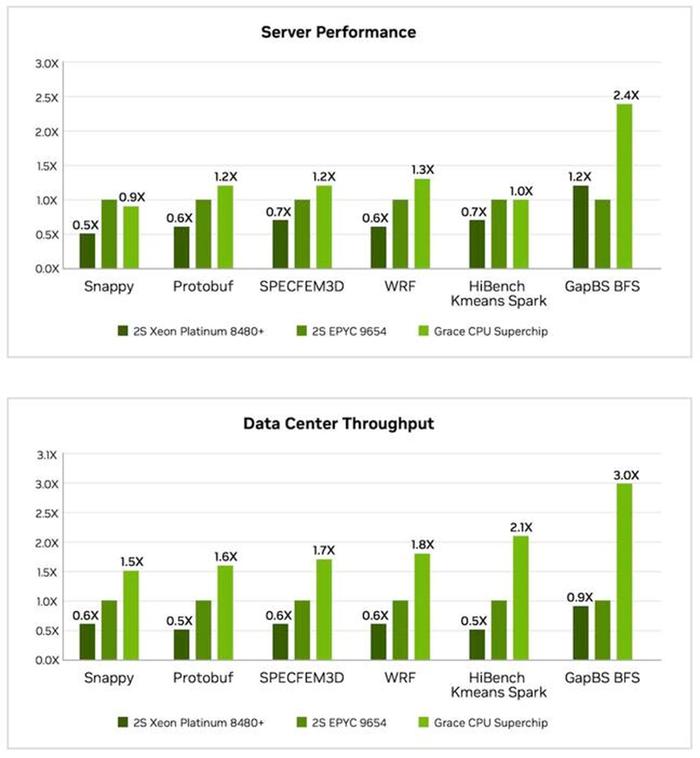
与此同时,Nvidia发布了类似的基准测试来反驳AMD的说法,正如您所想象的那样,它们看起来与TeamRed提供的结果大不相同。根据Nvidia的说法,GraceCPUSuperchip在服务器端性能上比双插槽EPYC9654快2.4倍,在数据中心吞吐量上快3倍。平均而言,GraceCPU在多次测试中快1.5-2.0倍。
AMDEPYC处理器在性能和效率方面领先于ARM处理器,且毫不妥协
数据中心是现代数字经济的支柱,为需要高性能、高能效和易用性的各种应用和服务提供支持。无论您运行的是在线购物、网站托管、数据分析、视频流还是人工智能(AI)工作负载,您都需要一款能够提供最佳结果且不影响任何方面的处理器,并且所有处理器都具有无缝可移植性,以便您可以专注于主要业务。
数据中心业务的重要性日益增加,如今大量电力被专用于数据中心和云基础设施,这促使许多供应商提出替代处理器选择,这些选择通常声称比常见的x86解决方案更具优势。这些新替代方案之一来自Nvidia,其基于ARM处理器IP的“GraceSuperchip”。通常,这些方案会大张旗鼓地推出,并声称与x86相比具有显著的性能和能效优势。但很多时候,这些说法很难转化为现实世界的竞争性工作负载场景——因为替代方案过时、不够优化或假设记录不充分。
AMDEPYC处理器继续在数据中心性能、能效、安全性和总拥有成本方面树立新标准,这得益于对成熟的x86架构的持续创新。无论是在本地部署、在云环境中部署还是在不同行业部署,第四代AMDEPYC处理器产品组合都能提供尖端解决方案来满足各种工作负载要求。广泛的AMDEPYC生态系统包含250多种不同的服务器设计,支持近900个独特的云实例,并受到全球一些最大公司的信任,用于运行其服务。AMDEPYC处理器在广泛的基准测试中保持着300多项性能和效率世界纪录,包括商业应用程序、技术计算、数据管理、数据分析、数字服务、媒体和娱乐以及基础设施解决方案。
正如我们在本文中所展示的,EPYC在众多行业标准基准测试中领先于基于ARM的解决方案。此外,借助AMD首创的久经考验的x86-64架构,您无需昂贵的移植或架构转换即可获得这一优势。
我们在十个关键工作负载上比较了AMDEPYC处理器和NVIDIAGraceCPUSuperchip的性能,涵盖通用计算、服务器端Java、电源效率、事务数据库、决策支持系统、Web服务器、内存分析、视频编码和HPC工作负载。我们使用行业标准基准和测试方法来确保公平透明的比较。RaghuNambiar在博客中发布了一套完整的测试结果,其中包括测试讨论以及系统和测试配置的文档,链接如下。图1显示了结果摘要,即AMDEPYC处理器性能与NVIDIAGraceCPUSuperchip系统性能的比率。
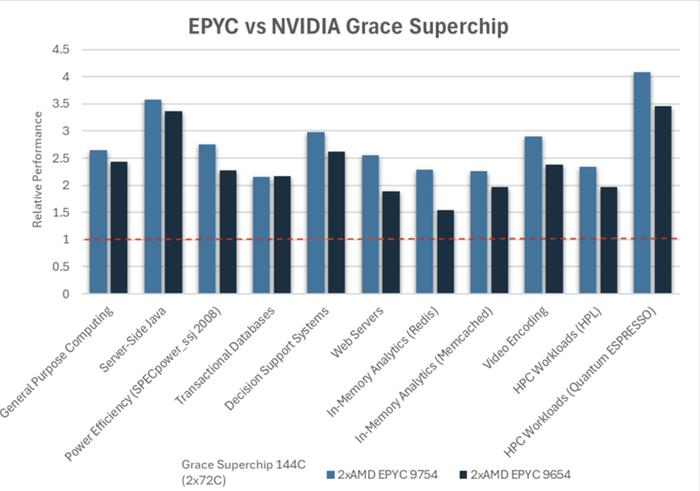
可以看出,AMDEPYC处理器在代表多个垂直行业的工作负载中提供的性能是NVIDIAGraceCPU超级芯片的两倍以上,展示了AMDEPYC处理器在数据中心性能方面的卓越能力,毫不妥协。
值得注意的是,AMDEPYC架构为您提供了开箱即用的性能和能效。您可以获得关键应用程序所需的所有性能,同时还有助于实现能源目标,而无需更改架构甚至系统供应商。领先的能效以基于AMDEPYC的服务器的形式提供,这些服务器来自您熟悉和信任的服务器供应商,可用于运营您当前的业务。下面的图2提供了上图中数据的细分,以更直接地关注使用备受推崇的SPECpower_ssj2008基准测试的系统结果,该基准旨在展示工作负载处理中的能效。
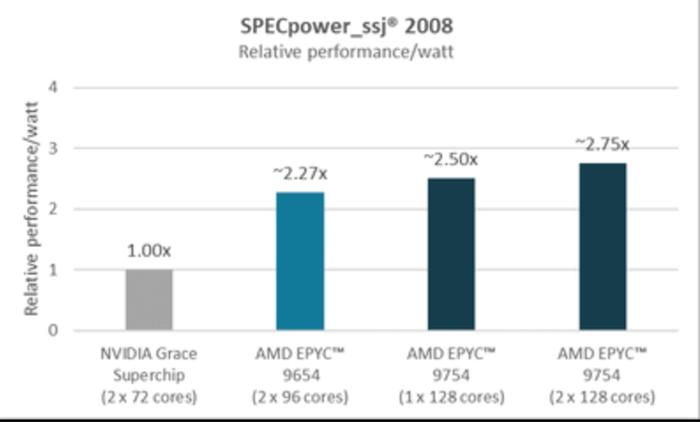
如图所示,基于单插槽和双插槽AMDEPYC9754的系统分别比NVIDIAGrace系统高出约2.50倍和约2.75倍。此外,在相同测试中,双插槽AMDEPYC9654系统比同一NVIDIA系统高出约2.27倍。
除了性能和效率之外,兼容性是数据中心运营商需要考虑的另一个重要因素。据估计,全球有数万亿行软件代码,其中大部分是为x86架构编写的。AMDEPYC处理器基于AMD首创的x86-64架构,该架构是数据中心行业使用最广泛、支持最广泛的架构。这意味着您可以在AMDEPYC处理器上运行各种工作负载,而不会出现任何兼容性问题,也不需要昂贵的架构转换到不同的ISA。人们很容易忘记软件端口是一回事,真正的负担在于必须管理和维护多个代码库。此外,每个ARM实现因芯片供应商而异,因此使用一个ARM芯片并不意味着您可以期望与另一个供应商的ARM芯片无缝兼容。
AMD认为架构变更既困难又昂贵,而且充满风险。基于开放标准的方法与不懈创新相平衡,为客户提供了更好的途径。AMDEPYC处理器帮助服务器供应商和生态系统IHV支持向最新功能和标准(如PCIe®5.0、DDR5和CXL)的过渡,以确保面向未来和互操作性,并为客户提供平稳的采用路径。很少有ARM产品在将扩展的IHV服务器生态系统带入共同创新方面拥有良好的记录。AMD继续执行稳定的处理器创新路线图,并为客户提供值得信赖的选择来推进其数据中心。
AMDEPYC处理器是数据中心性能和效率的最佳选择,因为它们在十种关键工作负载中的表现优于NVIDIAGraceCPUSuperchip,这是基于大量行业标准基准测试出版物和测试的结果。AMDEPYC处理器还具有x86处理器架构兼容性的优势,使您能够部署广泛的工作负载,而不会做出任何妥协,也无需昂贵的架构转换到不同的ISA。对于希望通过简单的按钮最大限度地提高性能,同时最大限度地降低数据中心的功耗和空间占用的数据中心运营商来说,AMD处理器是最佳选择。在人工智能时代,您需要为新兴的人工智能工作负载提供容量,AMD提供了最佳选择,它基于行业标准,数据和基准的透明度,以及整个生态系统中平台和解决方案的广泛可用性,无需昂贵的架构转换。
参考链接
https://www.theregister.com/2024/07/23/amd_nvidia_arm_benchmarks/?td=rt-4a点这里加关注,锁定更多原创内容