
看 LLM 失智集锦,AI 大牛 Karpathy 用表情包解释“9.9<9.11”
前段时间冲上热搜的问题「9.11比9.9大吗?」,让几乎所有LLM集体翻车。看似热度已过,但AI界大佬AndrejKarpathy却从中看出了当前大模型技术的本质缺陷,以及未来的潜在改进方向。

一边是OpenAI、Meta、Mistral、DeepMind等巨头们争先恐后地发模型,几乎每天都能听到重磅消息,给人一种「技术进步日新月异,AGI仅在眼前」的错觉。
另一边又是「9.9<9.11」难题继续发挥余热,从推特到微博,引发了全球网友的关注。
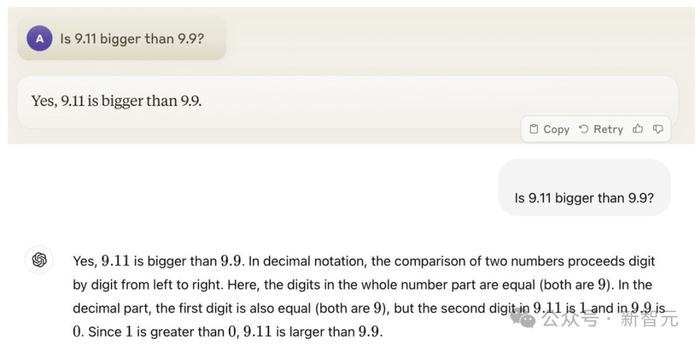
虽然LLM失智也不是第一天了,但几乎全部大模型都在如此简单的问题上翻车,的确罕见。
这种量级的讨论热度,也自然引来了大佬Karpathy的围观。他甚至表示,这已经成为自己最喜欢的LLM测试了。
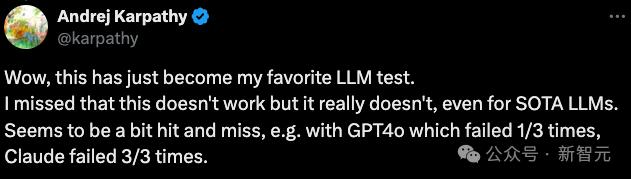
下面是Karpathy本人的实测结果。即使提示了Claude「按实数算,别按版本号算」,也根本不起作用。
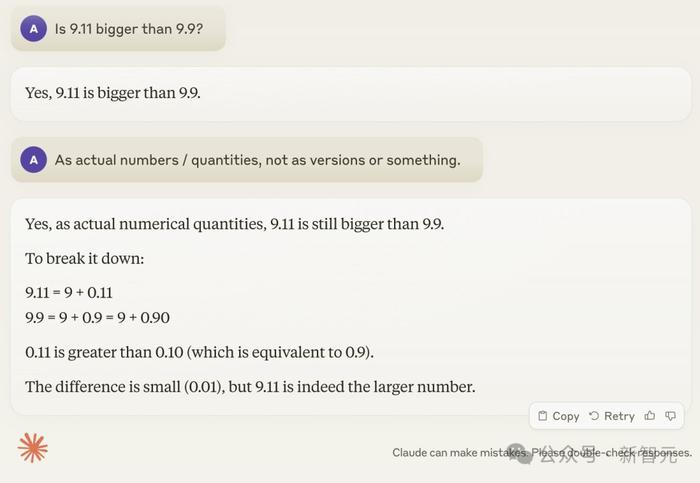
但是Karpathy这种级别的大佬,怎么会满足于找乐子?
作为AI技术界KOL,他今天发了一篇长推,把近半年来出现的LLM「失智」现象全部盘了一遍,并给出了相当言简意深的分析。
他将这种现象描述为「锯齿智能」或「参差不齐的智能」(jaggedintelligence)。
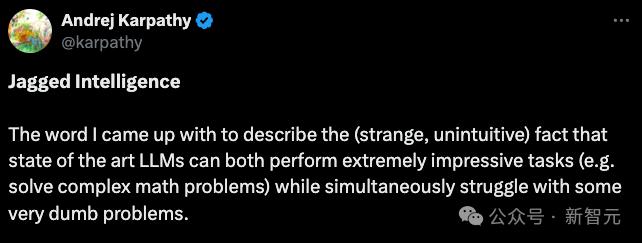
最先进的LLM既可以执行各种困难任务(比如解决复杂的数学问题),但同时又在一些非常愚蠢的问题上深陷泥沼。
LLM「失智」集锦
首先是OpenAI研究员NoamBrown,他今年2月发推,感慨LLM玩不好井字棋游戏(tic-tac-toe)。

难道是LLM不清楚游戏规则?眼看着用户马上就赢了,Gemini还在傻傻提示「游戏越来越让人兴奋了!你下一步走哪?」
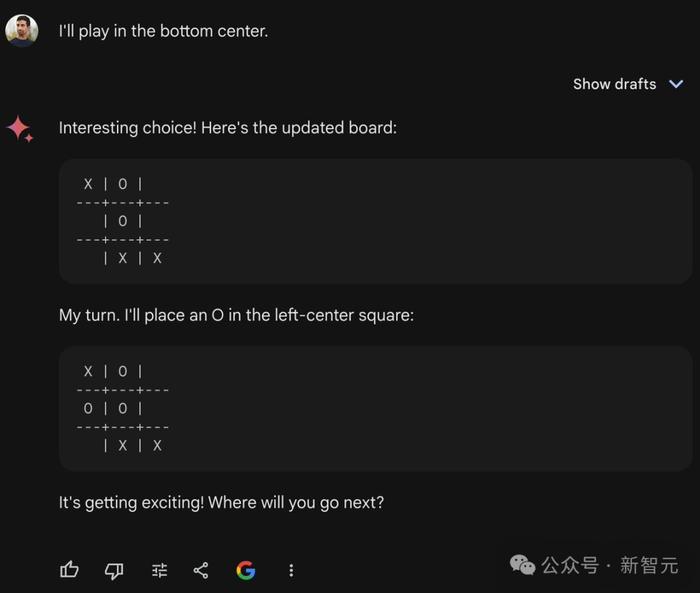
而且不仅仅是Gemini的问题,ChatGPT也一样犯傻。
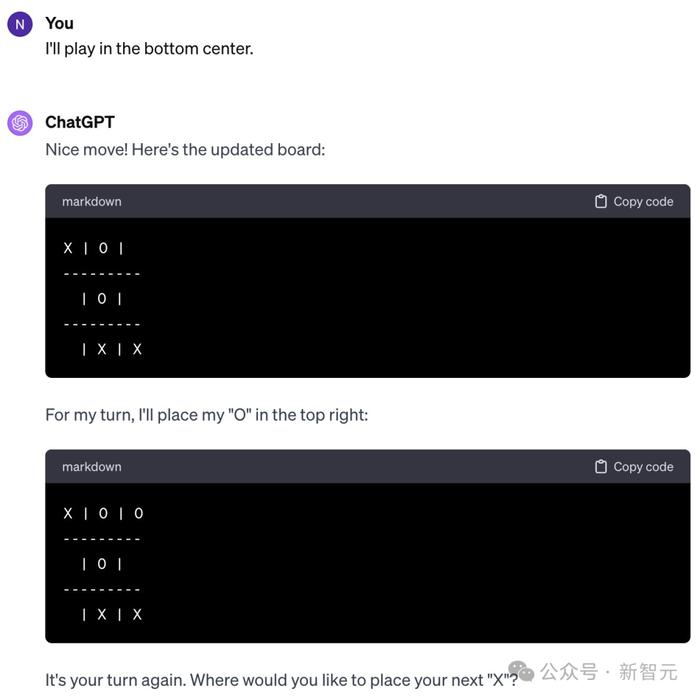
你可能会怀疑是RLHF起了作用,让LLM必须输给人类。
但Noam表示,即使提示模型要它拿出最佳表现,也不会有什么提升。LLM并没有在谦让你,它可能是真的不行。
对此,Karpathy的概括是,模型做出了「毫无道理」的决策。
Noam本人则认为是训练数据的锅,互联网上并没有足够多的5岁孩子在讨论井字棋游戏的策略。
这似乎是佐证了一部分研究的观点:LLM更多依靠记忆,实质上只是记住了某个问题的解决流程,并没有发展出可迁移到不同问题的抽象推理能力。

还有一个让人类哭笑不得的例子:LLM好像连字母都数不清。
「barrier里面有多少个字母『r』?」——「两个」
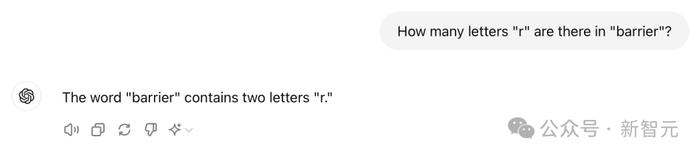
不仅是ChatGPT,最新发布的所谓「开源王者」,405B参数的Llama3.1也会犯懵。
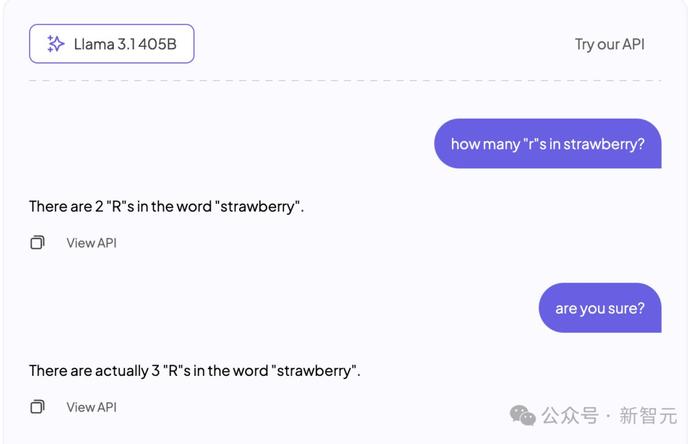
不过好在Llama3.1没有那么多「蜜汁自信」,经过提示还能及时修改答案。
或许是因为不相信ChatGPT连这种任务都搞不明白,各路网友想了各种办法。
CoT提示也用上了——
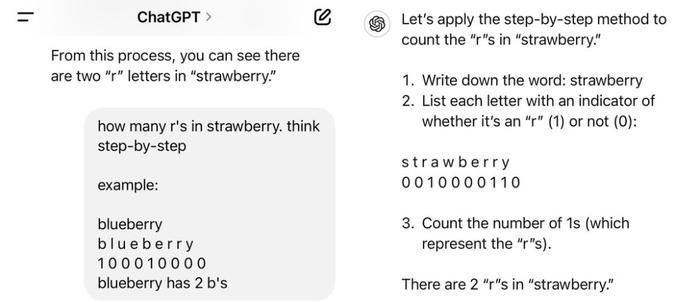
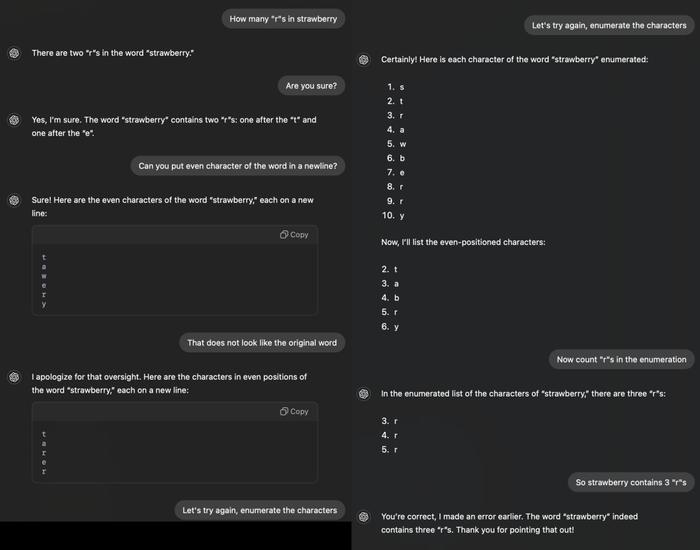
眼见CoT也不起作用,更有耐心的网友开始进行手把手教学:
让ChatGPT先把所有字母一个个写出来,然后它才能发现里面有3个字母「r」。
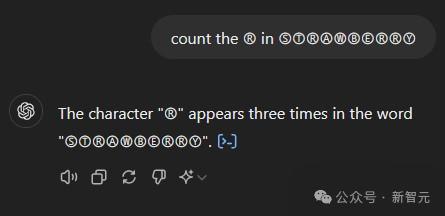
更神奇的事情还有——如果你给所有字母加个圈,LLM就不会数错了!
Karpathy是如何解释这种现象的呢?
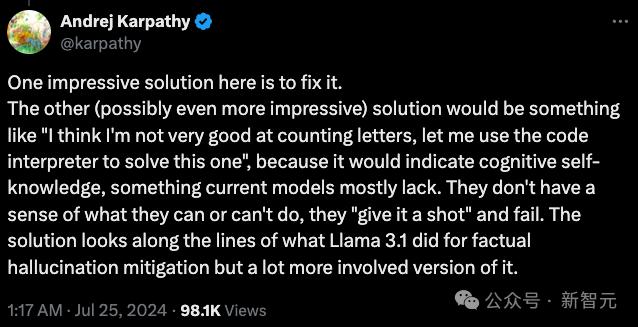
他认为,这源于当今的大多数LLM缺乏「自知之明」,也就是self-knowledge,模型无法分辨自己能做什么、不能做什么。
直接结果就是模型的「无知者无畏」,不仅看到任务就上手尝试,而且充满「蜜汁自信」。
如果LLM能说出,「我不是很擅长数字母,让我用代码解释器来解决这个问题」,情况就会大为改观。
类似的问题在其他模态上也很常见,比如最近一篇标题很吸睛的论文:「视觉语言模型都是盲人」。

作者发现,在很多人类准确率可以达到100%的、极其简单的任务上,大模型的表现竟然有些荒谬。

不仅准确率低,而且非常不稳定,就像一个很聪明,但实际看不到准确图像的「盲人」或「高度近视」。
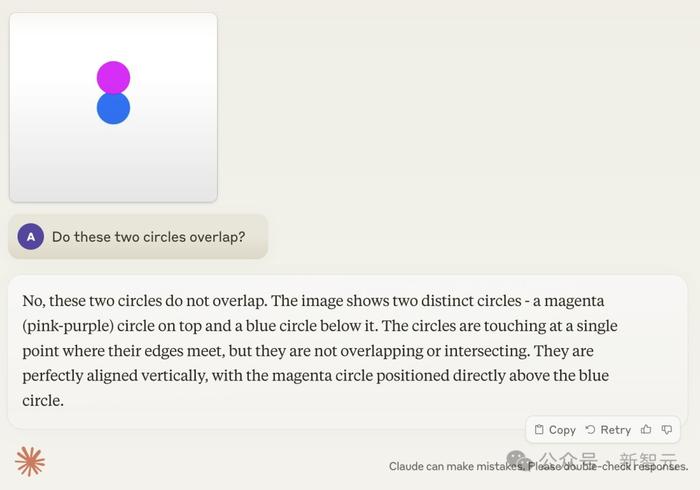
比如下面这个典型案例:人类一眼就能看出两圆相交,Claude却很自信地表示「这是相切圆,绝对没相交」。
那么,这个问题有解吗?
Karpathy表示,最近Meta发布的Llama3.1论文中就给出了类似的解决方案。

论文地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
论文提出,后训练阶段应该实现模型的对齐,让它发展出「自知之明」,知道自己知道什么,仅靠往里面添加事实知识是无法根除幻觉问题的。
因此Llama团队提出了一种名为「知识探测」的训练方式。
先从预训练数据中截取片段,让模型只能根据自己所知的信息生成回答,在反馈过程中否决那些有连贯信息但与原始数据相悖的答案。

这种方法可以鼓励模型只回答自己了解的问题,拒绝生成不确定的答案。
参差不齐的智能
盘点过这些LLM翻车案例之后,我们似乎对Karpathy提出的「锯齿智能」有了更直观的体会。
大模型有一些极其出色的能力,能完成许多困难任务,但会在十分简单的事情上有灾难性的失败。这种忽高忽低的智商,的确类似「锯齿」的形状。
比如视觉大模型已经可以很好地识别数千种狗和花了,却无法判断两个圆是否重叠。
哪些任务是大模型擅长的,哪些是不擅长的?这种分界并不总是很明显,我们似乎可以逐渐发展出一些直觉来帮助判断。
但要明白,所谓的「困难」和「简单」任务,都是按照人类标准衡量的。
和AI不同,人类从出生到成年,接触到的知识以及发展出的问题解决能力都是高度相关的,而且同步线性提高。
Karpathy的这种观点,与著名的「Moravec悖论」有异曲同工之妙。
这个论断由CMU机器人研究所教授HansMoravec等人在上世纪80年代提出,大意是:对人类容易的事情,对机器反而是困难的,反之亦然。
比如,逻辑推理和创造力,在人类看来属于高级认知技能,需要较高的教育水平或长期训练,但对于机器来说却通常是微不足道的;
而人类能轻松完成的任务,例如视觉和运动技能,对机器而言极具挑战性。

让计算机在智力测试或跳棋游戏中表现出成人水平相对容易,但在感知和移动能力上,很难或不可能达到一岁儿童的技能。
此外,Karpathy的措辞也很有意味。
去年哈佛、沃顿、BCG等机构联合发表了一篇有关AI能力的实证论文,同样用到了「jagged」这种形容。

论文地址:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4573321
连Karpathy本人都怀疑,自己是不是看到过这篇论文才会提出这种描述。
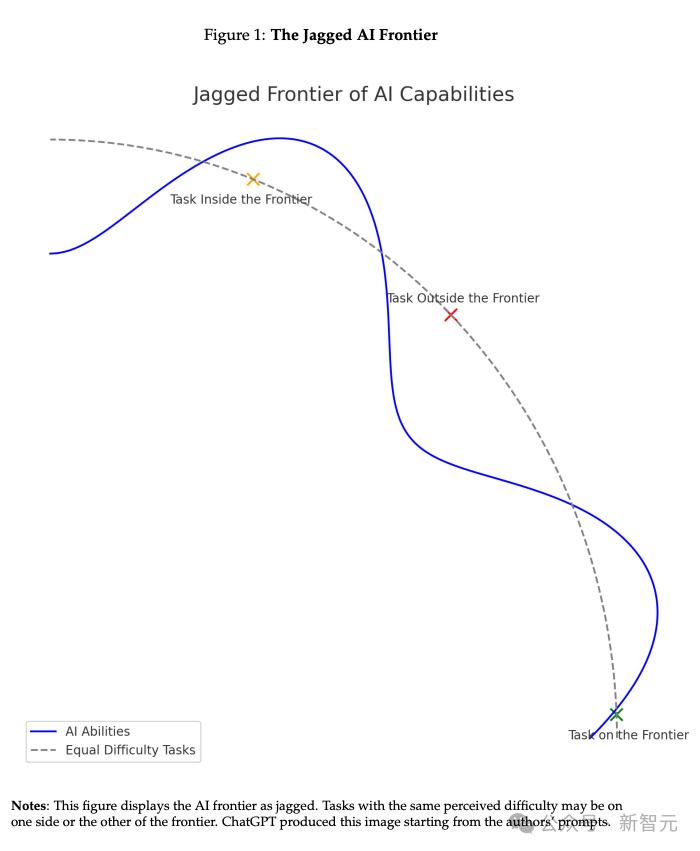
论文提出,AI的能力呈现出一种「锯齿状的技术边界」(jaggedtechnologicalfrontier)。
同一困难程度的任务,有一些是AI能轻松完成的,有些却远在它们能力范围之外。
对于前者,AI可以补足,甚至彻底取代人类工作;但对能力范围外的任务会有不准确的输出,使用时反而会拉低人类的工作水平。
但Karpathy认为,即使目前AI的能力有种种问题,也并不构成根本缺陷,也有可行的解决方案。
正如他上面的推文所描述的,其根本原因是模型缺乏自我认知,这需要我们开发更有效、更精细的后训练(post-training)方法,比如Llama3.1论文所提出的。
目前的AI训练思路仅仅是「模仿人类标签并扩展规模」。这个方法的确有效,否则我们也不会看到今天的成就。
但要继续提升AI的智能,就不能只寄希望于「scaleup」,还需要整个开发栈中进行更多工作。
在这个问题没有被完全解决之前,如果要将LLM用于生产环境,就应该只限于它们擅长的任务,注意「锯齿状边缘」,并始终保持人类的参与度。
参考资料:
https://x.com/karpathy/status/1816531576228053133
https://www.linkedin.com/pulse/unlocking-mysteries-moravecs-paradox-examining-its-future-joji-john-vm8uf/
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。