
行业大模型、数据隐私、算力瓶颈:技术应用的挑战与机遇

近年来,随着AI浪潮的兴起,大模型技术在全球范围内迅速崛起。这类模型通常指参数规模在亿级以上的深度学习模型,能够通过海量数据进行训练,在复杂任务中展现出远超传统模型的性能。以OpenAI的GPT-3、Google的BERT和Meta的LLaMA为代表,这些通用大模型在自然语言处理、计算机视觉等领域取得了突破性进展,推动了人工智能技术的快速普及。
然而,通用大模型在广泛应用的同时也暴露出一些局限性。由于其训练数据和设计目标更倾向于通用性,在解决特定行业场景中的问题时,可能存在效果不足或成本过高的情况。基于此,各行业开始探索定制化的大模型——即“行业大模型”,通过优化模型架构和训练数据,使其在特定应用场景中实现更高效、更精准的表现。例如,金融领域的大模型专注于风控与智能投顾,而医疗领域则致力于疾病诊断与药物研发。
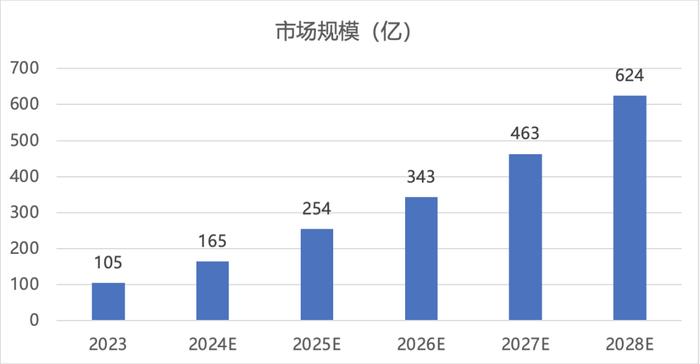
随着行业大模型的崛起,其市场规模也在迅速扩大。根据沙利文《2024年中国行业大模型市场报告》的测算,2023年中国行业大模型市场规模达105亿人民币,受行业智能化转型需求带动,预计2024年市场规模将达到165亿元,同比增长57%,2028年市场规模有望达到624亿元人民币。这种增长不仅得益于技术突破,也离不开阿里巴巴、腾讯、百度和字节跳动等科技巨头的推动。这些企业以通用大模型为基础,结合特定领域需求,推出了一系列适配场景的大模型,例如智能客服系统、精准营销平台和医疗影像诊断工具。这些行业模型的落地,展现了从“通用”到“定制”的技术迁移过程,为企业创造了巨大价值。
从技术层面来看,行业大模型的快速发展得益于多种创新方法的应用。从Transformer架构、预训练和微调策略的普及,到多模态学习、自动化训练和模型压缩等新技术的引入,这些技术不仅提高了模型性能,还显著降低了开发与运行成本。例如,基于Transformer的BERT模型虽然是通用大模型的代表,但其训练方法和架构设计为行业模型的发展提供了技术蓝图。如今,许多企业在开发行业大模型时,逐步采用轻量化设计和特定领域知识蒸馏,以适配复杂的应用场景和实际需求。
同时,中国政府在推动大模型技术的发展中扮演了重要角色。通过出台《新一代人工智能发展规划》等政策,明确提出到2030年实现人工智能理论和应用的重大突破目标。地方政府也积极配合,设立专项资金、搭建产业园区、鼓励产学研合作,为行业大模型的研发与落地提供了全方位支持。这种政策导向不仅让通用大模型的技术成果更快惠及产业,也推动了中国行业大模型生态的逐步成熟。
大模型技术从以通用性为主的发展阶段,逐步演进到行业定制化阶段,为各行业提供了更契合实际需求的智能化解决方案。从技术创新到市场规模扩张,再到政策支持,各方力量的协同作用正加速行业大模型的发展。
AI浪潮下的行业变革
在AI浪潮的推动下,大模型技术正成为企业数字化转型的重要驱动力。越来越多的行业和公司围绕大模型开展研究和探索,通过技术革新促进降本增效,同时提升业务能力。大模型的应用不仅推动了生产效率的提升,也为不同领域的创新提供了新路径。
在金融行业,招商银行推出了基于大模型的风险管理系统,该系统能够实时监测潜在风险,从而降低贷款违约率。通过分析海量的交易数据,该系统帮助金融机构更有效地评估和管理市场风险、信用风险和操作风险,提供精确的风险预测和决策支持。此外,金融机构还利用大模型技术构建智能客服系统,以提升客户满意度和忠诚度。例如,中国工商银行为20万网点员工打造了智能助手,显著提高了网点的运营效率。据统计,2023年其智能处理的业务量达到了3.2亿笔,比2022年增长了14%。大模型技术还被应用于量化交易策略的开发和执行,通过分析大量金融数据和市场信息,识别潜在的交易机会和趋势,自动执行交易策略并进行实时调整,从而提高交易效率、降低成本、增强交易稳定性并增加收益。
在医疗行业,大模型的应用正带来前所未有的变革。在患者筛选方面,医渡科技与北京大学肿瘤医院合作开发了一种智能筛选系统,通过大数据和大模型技术,肿瘤类项目的人工筛查成本减少了88.5%,非肿瘤类项目减少了69.8%。这一系统的落地显著提高了医院在患者招募场景中的效率。
此外,大模型在药物研发中同样表现突出。例如,晶泰科技的XpeedPlay平台利用大模型技术,实现了超高速生成苗头抗体,加速了药物研发流程。而智源研究院研发的全原子生物分子模型OpenComplex2,则能精准预测蛋白质、RNA等复合物,进一步提升药物开发效率。放射诊断领域也不乏亮点,北京天坛医院与北京理工大学联合推出的“龙影”大模型(RadGPT)支持中文数字放射科医生“小君”,能够快速分析MRI图像并生成诊断意见,一个病例的处理时间仅需0.8秒,极大提高了医疗服务效率。
在零售和电商领域,大模型技术正在从内容生成到用户体验优化等方面展现其潜力。例如,家乐福借助生成式AI技术,已为2,000种产品生成丰富的产品介绍,并计划将这一技术推广至所有商品。可口可乐公司推出的“CreateRealMagic”平台结合了GPT-4和DALL·E,通过文本生成图像,帮助创意人员快速创作原创艺术作品,为品牌营销注入新的活力。这些应用不仅改善了用户体验,还显著提升了品牌的创新能力与市场竞争力。无论是内容生成的精准度还是交互设计的优化,大模型为零售与电商行业的数字化转型提供了重要支持。
从金融风控到医疗诊断,再到零售电商的精准营销,大模型的底层技术因场景需求的不同而呈现差异化。金融行业多采用时间序列分析与实时数据处理技术,以提升风险管理的效率;医疗行业则注重多模态学习,结合影像数据与临床信息推动诊断精度;零售电商则依赖生成式AI,丰富产品内容和交互方式。这种技术的灵活性,凸显了大模型在不同行业中的适配能力与核心价值。
技术与应用的深度融合
随着大模型技术的飞速发展,行业大模型正逐渐展现出其独特的技术优势和应用价值。相比通用大模型,行业大模型更加注重针对性和专用性,尤其在特定领域的数据优化、技术创新以及计算资源的高效利用上,展现出卓越的竞争力。
行业大模型与通用大模型的关键区别在于其目标和应用场景的专注程度。通用大模型如GPT-3,凭借高达1750亿个参数,能够在多种任务中展现出强大的泛化能力。然而,这种广泛性也意味着计算成本的增加以及对特定场景的适配能力不足。相比之下,行业大模型的参数规模通常更小,但针对性更强。例如,在金融行业中,行业大模型以时间序列数据为核心,优化市场波动分析和风险管理;而在医疗行业中,大模型则结合临床数据与医学影像资料,更精准地辅助诊断与治疗。这种定制化设计使行业大模型在特定任务中的表现更加精准高效。
行业大模型的优势不仅体现在其专注的领域应用上,还在技术创新中得到了进一步强化。通过模型压缩技术,企业能够在保证性能的同时显著降低计算成本,使得行业大模型在资源受限的环境中依然能够高效运行。例如,某些医疗机构通过优化模型架构,使得模型可以在边缘设备上直接运行,降低了对云计算资源的依赖。
此外,知识蒸馏技术的应用也成为提升行业大模型效率的关键方法。通过这一技术,复杂模型的知识能够被提炼并迁移到更轻量的模型中,从而在不牺牲性能的情况下减少计算资源的需求。例如,平安好医生在其“平安智医”模型中,通过多模态数据融合(如文本、影像和病历数据),不仅提高了诊断的准确率,还显著加快了诊断的响应速度。
随着行业大模型的规模不断扩大,计算资源的需求成为不可忽视的挑战。企业通过分布式训练技术,有效解决了这一问题。分布式训练允许模型的训练过程在多个服务器上并行进行,大幅提升了训练速度。例如,京东在其智能推荐系统中引入了分布式训练技术,使模型的计算效率显著提高,同时加快了训练迭代周期。
边缘计算的兴起也为行业大模型的部署提供了全新的可能性。通过在靠近数据源的设备上运行模型,企业能够更高效地处理数据,同时显著降低网络延迟。这一技术特别适用于医疗和工业等对实时性要求较高的场景,例如医疗诊断中的边缘设备分析或工业设备的实时监控。
通过针对性的数据优化、高效的技术创新以及计算资源的合理分配,行业大模型在特定领域中展现出了超越通用大模型的优势。这不仅降低了企业在应用人工智能技术时的成本,还为其开拓了更广泛的商业应用场景。未来,随着更多技术的不断迭代,行业大模型将在更广泛的领域中推动数字化转型和业务模式的创新。
行业大模型的未来趋势与挑战
尽管行业大模型在多个领域中展现了强大的应用潜力,但其广泛应用仍面临一系列亟待解决的挑战。从数据隐私到算力资源,再到实际效果的可控性,这些问题都直接影响着行业大模型的可持续发展。
首先,数据隐私问题日益成为行业关注的焦点。在数据驱动的模型训练过程中,如何保护用户隐私并避免数据泄露,是企业必须直面的关键挑战。医疗和金融领域尤为突出,其数据高度敏感且与公众信任息息相关。如果未能妥善管理这些信息,不仅可能引发数据泄露事件,还会造成广泛的社会信任危机。因此,企业在采用大模型时,不仅需要加强数据管理,还必须严格遵守合规性要求,确保用户数据的安全与透明。
其次,算力资源的高昂成本是大规模模型应用的主要制约因素。虽然云计算和分布式计算的普及在一定程度上缓解了这一问题,但基础设施的高投入依然令许多中小型企业望而却步。对于这些资源受限的企业,算力瓶颈不仅增加了开发成本,也削弱了其在行业中的竞争力。因此,如何实现更高效的算力利用,降低计算资源的门槛,成为推动行业大模型普及的重要课题。
第三,行业数据集的匮乏是阻碍行业大模型研发的主要原因之一。与通用数据集相比,行业数据集普遍存在数据量不足、覆盖面有限的问题,同时面临数据源分散、标准化欠缺以及隐私和合规限制等多重挑战,导致其建设难度较大。要构建高质量的行业数据集,需要在顶层设计、标注规范和质量把控等方面严格执行,这不仅是一个需要长期积累的过程,还需要持续投入大量资金,对许多企业来说是一项艰巨的任务。尽管如此,市场上仍然涌现了一些优质的行业数据集,例如阿里云的天池数据集、智源研究院发布的IndustryCorpus1.0,以及IMSHealthPharmaceuticalData等,这些数据集为行业大模型的研发提供了重要支持,为解决行业特定场景的需求奠定了坚实基础。
此外,大模型在实际应用中的效果可控性也是一个备受关注的问题。尽管其在训练数据中表现优异,但在真实环境中可能因过拟合或数据偏差导致性能下降。例如,金融机构若依赖大模型进行市场预测,可能因模型误差而造成经济损失。因此,企业需要建立可靠的监控和反馈机制,利用在线学习和增量训练等技术,持续优化模型性能,以确保其在动态环境中的稳定性和可靠性。
面对上述挑战,行业大模型正在技术创新的驱动下探索多种可行的解决方案。未来的行业大模型将呈现出“小型化”“轻量化”和“多模态化”等几大趋势,为模型的发展和应用打开新的局面。
随着技术的不断进步,小型化和轻量化将成为行业大模型发展的核心方向。小型化意味着模型的参数规模适度减少,但依然保留强大的学习和推理能力,从而降低计算资源的需求;轻量化则通过模型压缩与优化算法,使得模型能够在移动设备和边缘计算环境中高效运行。这不仅降低了模型部署的成本,也为中小型企业提供了采用大模型的机会,从而扩大技术的普及范围。
多模态学习正成为行业大模型发展的重要突破方向。通过整合文本、图像和音频等多种数据形式,模型能够更全面地理解复杂场景。例如,在医疗领域,结合患者历史记录与医学影像的多模态模型,不仅能提升临床诊断的准确性,还能更有效地支持医生决策,改善整体医疗服务质量。这种跨模态能力将使行业大模型在更广泛的应用场景中大展身手。
自动化训练技术的快速发展也为行业大模型的迭代与普及提供了新的可能性。通过自动化机器学习技术,模型的选择、超参数优化和特征选择等复杂流程得以实现自动化,从而显著降低开发门槛。甚至非技术专业人员也可以通过低门槛的工具参与大模型开发,加速模型的创新与落地。
行业大模型的崛起不仅是技术发展的必然结果,也是行业数字化转型的核心驱动力。面对数据隐私、算力瓶颈和效果可控性等挑战,政策支持、技术创新和行业合作将成为未来发展的重要支柱。通过持续的技术迭代与应用探索,行业大模型有望在未来实现更广泛、更深层次的落地应用,为社会各领域带来全新的机遇与价值。
可以预见,未来行业大模型将成为人工智能与行业深度融合的关键引擎,推动技术与产业的共同繁荣。
文:赢家 / 数据猿责编:凝视深空 / 数据猿