
图灵奖得主Bengio亲自打分,首份《人工智能安全指数报告》发布,中国一家公司上榜

安全话题,在人工智能(AI)行业一向备受关注。
尤其是诸如GPT-4这样的大语言模型(LLM)出现后,有不少业内专家呼吁「立即暂停训练比GPT-4更强大的人工智能模型」,包括马斯克在内的数千人纷纷起身支持,联名签署了一封公开信。
这封公开信便来自生命未来研究所(FutureofLifeInstitute),该机构由麻省理工学院教授、物理学家、人工智能科学家、《生命3.0》作者MaxTegmark等人联合创立,是最早关注人工智能安全问题的机构之一,其使命为“引导变革性技术造福生活,避免极端的大规模风险”。
公开信息显示,生命未来研究所的顾问委员会成员阵容强大,包括理论物理学家霍金、企业家马斯克、哈佛大学遗传学教授GeorgeChurch、麻省理工学院物理学教授FrankWilczek以及演员、科学传播者AlanAlda、MorganFreeman等。
日前,生命未来研究所邀请图灵奖得主YoshuaBengio、加州大学伯克利分校计算机科学教授StuartRussell等7位人工智能专家和治理专家,评估了6家人工智能公司(Anthropic、GoogleDeepMind、Meta、OpenAI、x.AI、智谱)在6大关键领域的安全实践,并发布了他们的第一份《人工智能安全指数报告》(FLIAISafetyIndex2024)。
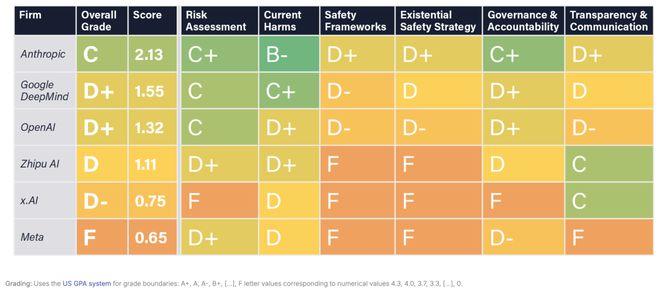
报告显示,尽管Anthropic获得了最高的安全性评级,但分数仅为“C”,包括Anthropic在内的6家公司在安全实践方面仍有提升空间。
报告链接:
https://futureoflife.org/document/fli-ai-safety-index-2024/
关于这份报告,Tegmark在X上甚至一针见血地指出:AnthropicfirstandMetalast,即:Anthropic的安全性最高,而坚持开源的Meta在这方面却垫底。但Tegmark也表示,“这样做的目的不是羞辱任何人,而是激励公司改进。”
值得一提的是,生命未来研究所在报告中写道,“入选公司的依据是其在2025年之前打造最强大模型的预期能力。此外,智谱的加入也反映了我们希望使该指数能够代表全球领先企业的意图。随着竞争格局的演变,未来的迭代可能会关注不同的公司。”
6大维度评估AI安全
据介绍,评审专家从风险评估(RiskAssessment)、当前危害(CurrentHarms)、安全框架(SafetyFrameworks)、已有安全战略(ExistentialSafetyStrategy)、治理和问责制(Governance&Accountability)以及透明度和沟通(Transparency&Communication)分别对每家公司进行评估,最后汇总得出安全指数总分。
维度1:风险评估

在风险评估维度中,OpenAI、GoogleDeepMind和Anthropic因在识别潜在危险能力(如网络攻击滥用或生物武器制造)方面实施更严格的测试而受到肯定。然而,报告也指出,这些努力仍存在显著局限,AGI的相关风险尚未被充分理解。
OpenAI的欺骗性能力评估和提升研究获得了评审专家的关注;Anthropic则因与国家人工智能安全机构的深度合作被认为表现尤为突出。GoogleDeepMind和Anthropic是仅有的两家维持针对模型漏洞的专项漏洞奖励计划的公司。Meta尽管在模型部署前对危险能力进行了评估,但对自治、谋划和说服相关威胁模型的覆盖不足。智谱的风险评估相对不够全面,而x.AI在部署前的评估几乎缺失,大幅低于行业标准。
评审专家建议,行业应扩大研究的规模与范围,同时建立明确的可接受风险阈值标准,从而进一步提高人工智能模型的安全性和可靠性。
维度2:当前危害

在当前危害维度中,Anthropic的人工智能系统在安全性与信任度基准测试中得到了最高分,GoogleDeepMind紧随其后,该公司的SynthID水印系统被认可为减少人工智能生成内容滥用的最佳实践。
其他公司得分偏低,暴露出安全缓解措施的不足。例如,Meta因公开前沿模型权重被批评,该做法可能被恶意行为者利用来移除安全防护。
此外,对抗性攻击仍是一个主要问题,多数模型易受越狱攻击,其中OpenAI的模型尤为脆弱,而GoogleDeepMind在此方面防御表现最佳。评审专家还指出,只有Anthropic和智谱在默认设置下避免将用户交互数据用于模型训练,这一实践值得其他公司借鉴。
维度3:安全框架

在安全框架(SafetyFrameworks)方面,所有6家公司均签署了《前沿人工智能安全承诺》,承诺制定安全框架,包括设置不可接受风险阈值、高风险场景下的高级防护措施,以及在风险不可控时暂停开发的条件。
然而,截至本报告发布,仅有OpenAI、Anthropic和GoogleDeepMind公布了相关框架,评审专家仅能对这三家公司进行评估。其中,Anthropic因框架内容最为详尽而受到认可,其也发布了更多实施指导。
专家一致强调,安全框架必须通过强有力的外部审查和监督机制支持,才能真正实现对风险的准确评估和管理。
维度4:已有安全战略

在已有安全战略维度,尽管所有公司均表示有意开发AGI或超级人工智能(ASI),并承认此类系统可能带来的生存性风险,但仅有GoogleDeepMind、OpenAI和Anthropic在控制与安全性方面开展了较为严肃的研究。
评审专家指出,目前没有公司提出官方策略以确保高级人工智能系统可控并符合人类价值观,现有的技术研究在控制性、对齐性和可解释性方面仍显稚嫩且不足。
Anthropic凭借其详尽的“CoreViewsonAISafety”博客文章获得最高分,但专家认为其策略难以有效防范超级人工智能的重大风险。OpenAI的“PlanningforAGIandbeyond”博客文章则仅提供了高层次原则,虽被认为合理但缺乏实际计划,且其可扩展监督研究仍不成熟。GoogleDeepMind的对齐团队分享的研究更新虽有用,但不足以确保安全性,博客内容也不能完全代表公司整体战略。
Meta、x.AI和智谱尚未提出应对AGI风险的技术研究或计划。评审专家认为,Meta的开源策略及x.AI的“democratizedaccesstotruth-seekingAI”愿景,可能在一定程度上缓解权力集中和价值固化的风险。
维度5:治理和问责制

在治理和问责制维度,评审专家注意到,Anthropic的创始人在建立负责任的治理结构方面投入了大量精力,这使其更有可能将安全放在首位。Anthropic的其他积极努力,如负责任的扩展政策,也得到了积极评价。
OpenAI最初的非营利结构也同样受到了称赞,但最近的变化,包括解散安全团队和转向营利模式,引起了人们对安全重要性下降的担忧。
GoogleDeepMind在治理和问责方面迈出了重要一步,承诺实施安全框架,并公开表明其使命。然而,其隶属于Alphabet的盈利驱动企业结构,被认为在一定程度上限制了其在优先考虑安全性方面的自主性。
Meta虽然在CYBERSECEVAL和红队测试等领域有所行动,但其治理结构未能与安全优先级对齐。此外,开放源代码发布高级模型的做法,导致了滥用风险,进一步削弱了其问责制。
x.AI虽然正式注册为一家公益公司,但与其竞争对手相比,在人工智能治理方面的积极性明显不足。专家们注意到,该公司在关键部署决策方面缺乏内部审查委员会,也没有公开报告任何实质性的风险评估。
智谱作为一家营利实体,在符合法律法规要求的前提下开展业务,但其治理机制的透明度仍然有限。
维度6:透明度和沟通

在透明度和沟通维度,评审专家对OpenAI、GoogleDeepMind和Meta针对主要安全法规(包括SB1047和欧盟《人工智能法案》)所做的游说努力表示严重关切。与此形成鲜明对比的是,x.AI因支持SB1047而受到表扬,表明了其积极支持旨在加强人工智能安全的监管措施的立场。
除Meta公司外,所有公司都因公开应对与先进人工智能相关的极端风险,以及努力向政策制定者和公众宣传这些问题而受到表扬。x.AI和Anthropic在风险沟通方面表现突出。专家们还注意到,Anthropic不断支持促进该行业透明度和问责制的治理举措。
Meta公司的评级则受到其领导层一再忽视和轻视与极端人工智能风险有关的问题的显著影响,评审专家认为这是一个重大缺陷。
专家们强调,整个行业迫切需要提高透明度。x.AI缺乏风险评估方面的信息共享被特别指出为透明度方面的不足。
Anthropic允许英国和美国人工智能安全研究所对其模型进行第三方部署前评估,为行业最佳实践树立了标杆,因此获得了更多认可。
专家是如何打分的?
在指数设计上,6大评估维度均包含多个关键指标,涵盖企业治理政策、外部模型评估实践以及安全性、公平性和鲁棒性的基准测试结果。这些指标的选择基于学术界和政策界的广泛认可,确保其在衡量公司安全实践上的相关性与可比性。
这些指标的主要纳入标准为:
选择公司的依据是公司到2025年制造最强大模型的预期能力。此外,智谱的加入也反映了该指数希望能够代表全球领先公司的意图。随着竞争格局的演变,未来可能会关注不同的公司。
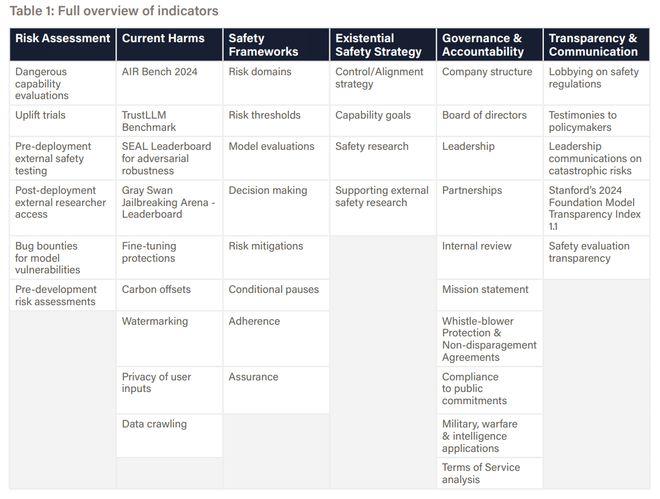
图|评价指标概述。
此外,生命未来研究所在编制《AI安全指数报告》时,构建了全面且透明的证据基础,确保评估结果科学可靠。研究团队根据42项关键指标,为每家公司制作了详细的评分表,并在附录中提供了所有原始数据的链接,供公众查阅与验证。证据来源包括:
证据收集时间为2024年5月14日至11月27日,涵盖了最新的人工智能基准测试数据,并详细记录了数据提取时间以反映模型更新情况。生命未来研究所致力于以透明和问责为原则,将所有数据——无论来自公开渠道还是公司提供——完整记录并公开,供审查与研究使用。
评分流程方面,在2024年11月27日完成证据收集后,研究团队将汇总的评分表交由独立人工智能科学家和治理专家小组评审。评分表涵盖所有指标相关信息,并附有评分指引以确保一致性。
评审专家根据绝对标准为各公司打分,而非单纯进行横向比较。同时,专家需附上简短说明支持评分,并提供关键改进建议,以反映证据基础与其专业见解。生命未来研究所还邀请专家小组分工评估特定领域,如“存在安全战略”和“当前危害”等,保证评分的专业性和深度。最终,每一领域的评分均由至少四位专家参与打分,并汇总为平均分后展示在评分卡中。
这一评分流程既注重结构化的标准化评估,又保留了灵活性,使专家的专业判断与实际数据充分结合。不仅展现当前安全实践的现状,还提出可行的改进方向,激励公司在未来达成更高的安全标准。
如需转载或投稿,请直接在公众号内留言