
AMD ZEN 5架构,深度解读
回到2024年台北国际电脑展,AMD首席执行官苏姿丰博士在开幕主题演讲中发布了备受期待的Zen5CPU微架构。AMD宣布了两个将采用最新Zen5核心的新客户端平台,而不是一个。其中包括AMD最新的面向笔记本电脑市场的AIPC芯片系列RyzenAI300系列。相比之下,Ryzen9000系列面向使用现有AM5平台的台式机市场。
RyzenAI300系列以全新的Zen5CPU微架构为基础,在图形和AI性能方面都有了一些根本性的改进,代号为StrixPoint,将在多个领域实现改进。RyzenAI300系列似乎将在迈向AIPC的道路上再添一笔,其移动SoC配备了全新的XDNA2NPU,AMD承诺其性能将达到50TOPS。AMD还用RDNA3.5升级了集成显卡,旨在取代上一代RDNA3移动显卡,从而在游戏中实现比我们之前见过的更好的性能。
在上周AMD的技术日上,AMD披露了有关Zen5的一些技术细节,其中还涵盖了RyzenAI300和Ryzen9000系列的一些关键元素。从纸面上看,Zen5架构与Zen4相比有了很大的进步,关键组件通过比其前代产品更高的每周期指令数推动Zen5向前发展,这是AMD从Zen到Zen2、Zen3、Zen4以及现在的Zen5一直努力做到的事情。
AMDZen5微架构:IPC比Zen4提高16%
移动版AMDRyzenAI300系列和台式机版Ryzen9000系列均采用AMD最新的Zen5架构,在性能和效率方面带来诸多改进。其移动产品线中最大的改进或许是集成了XDNA2NPU,旨在利用MicrosoftCopilot+AI软件。这些新的移动处理器通过NPU可提供高达50TOPS的AI性能,使其成为AMD移动芯片产品线的重大升级。

Zen5微架构的主要功能包括双管道提取,它与AMD所谓的高级分支预测相结合。这旨在减少延迟并提高准确性和吞吐量。增强的指令缓存延迟和带宽优化进一步促进了数据流和数据处理速度,而不会牺牲准确性。

Zen5整数执行能力比Zen4有所升级,Zen5具有8宽调度/退出系统。Zen5内部改进的一部分包括六个算术逻辑单元(ALU)和三个乘法器,它们通过ALU调度程序进行控制,AMD声称Zen5使用了更大的执行窗口。理论上,这些改进在更复杂的计算工作负载下应该会更好。

Zen5的其他主要增强功能包括比Zen4更高的数据带宽,配备48KB12路L1数据缓存,可满足4周期负载。AMD将L1缓存的最大可用带宽增加了一倍,浮点单元也比Zen4增加了一倍。AMD还声称改进了数据预取器,确保更快、更可靠的数据访问和处理。

Zen5还引入了完整的512位AI数据路径,它使用具有完整512位数据路径的AVX-512和具有两周期延迟FADD的六个管道。尽管Zen4可以支持AVX-512指令,但它使用两个相互协同工作的256位数据路径,术语“双泵”是其最广泛使用的术语。Zen5现在具有完整的AVX-512数据路径,这是一个受欢迎的改进。
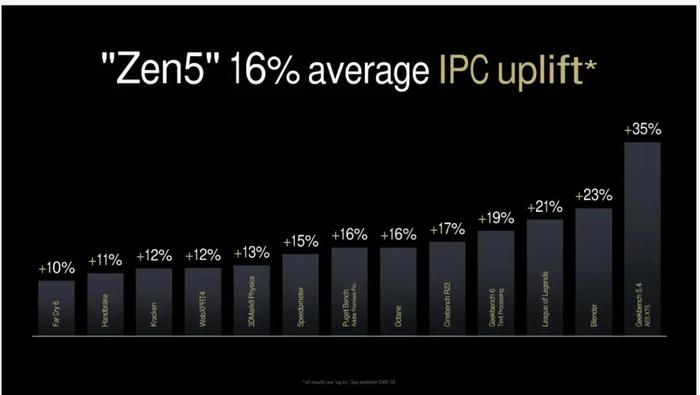
看看AMD宣称的Zen5的IPC提升,AMD声称与Zen4相比平均提升了16%。当然,AMD提供了内部数据,这些数据显示了各种基准测试的全面改进。其中包括《孤岛惊魂6》的10%提升,《速度计》的15%提升,《英雄联盟》的21%提升更大。AMD最大的宣称是Geekbench5.4AES-XTS的大幅提升了35%。这是一个令人印象深刻的性能提升,尽管Geekbench5AESXTS测试使用了VAES+和AVX10/512,这对于像Zen5一样支持这些指令的处理器来说可能是有利的。

正如我们在Zen微架构的先前版本中看到的那样,AMD正在将Zen5应用于整个产品系列。全功能Zen5内核采用台积电的4nm制造,而更紧凑、更节能的Zen5c内核则采用台积电的3nm工艺技术制造。AMD即将推出的第五代EPYCCPU(代号为“Turin”)预计将于2024年下半年推出,它将利用多达192个Zen5内核。AMD此前在2022年6月的财务分析师日上宣布,第五代EPYC将于2024年推出。
XDNA2NPU,最高可达50TOPS
对于用于笔记本电脑的AMDRyzenAI300系列,与上一代Ryzen8040系列(HawkPoint)相比,第二大进步是神经处理单元(NPU)。AMD于2020年收购Xilinx,通过整合Xilinx现有技术启动了NPU开发,从而形成了AMD最初的XDNA架构。凭借其最新版本的架构XDNA2,AMD进一步扩展了其功能和性能。它还引入了对块浮点16位算术方法的支持,而不是传统的半精度(FP16),AMD声称它结合了8位的性能和16位的精度。

看看AMDXDNA架构与多核处理器的典型设计有何不同,XDNA设计必须将灵活的计算与自适应内存层次结构结合起来。与固定计算模型或基于静态内存层次结构的模型相比,XDNA(RyzenAI)引擎使用互连的AI引擎(AIE)网格。每个引擎都经过精心设计,能够动态适应手头的任务,包括计算和内存资源,旨在提高可扩展性和效率。
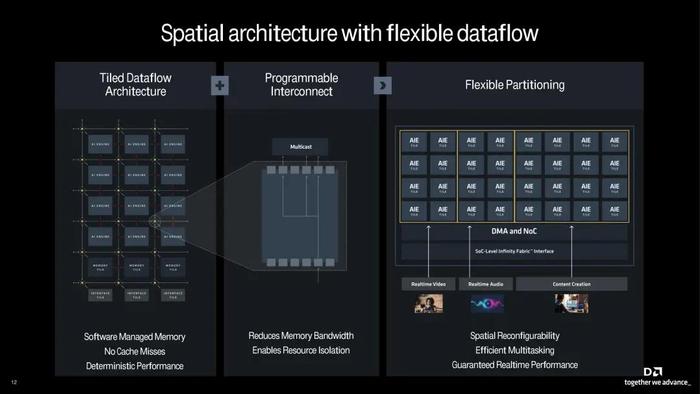
进一步谈及AIE的平铺方法,AMD称之为空间架构。它设计灵活,同时将平铺数据流结构与可编程互连和灵活分区结合在一起。平铺数据流结构可实现确定性性能,不会出现任何缓存未命中,还可增强内存管理。可编程互连大大降低了对内存带宽的需求,从而使其能够高效地分配资源。所采用的灵活分区设计可实现实时性能,同时能够满足不同的要求,从各种AI推理任务(包括实时视频和音频处理)到内容创建工作流程。

XDNA2架构以现有的XDNA架构为基础,并添加了更多AI引擎以提高吞吐量。StrixPoint中的AMDXDNA2实现有32个AI引擎块,比上一代多12个。XDNA2架构不仅提供了更多的AI引擎块,而且每个块的MAC数量是上一代的两倍,片上内存是上一代的1.6倍。
总而言之,AMD声称其NPU性能达到50TOPS,这比英特尔和高通目前的产品要高。关于使用TOPS来衡量AI性能的相关性的争论存在分歧,而微软通过将Copilot+的标准设定为40TOPS而率先提出了这一要求。

XDNA2架构不仅试图在TOPS上超越竞争对手,而且在设计时还考虑到了能效。AMD声称,与Ryzen7040系列中使用的NPU相比,其XDNA2NPU的计算能力提高了5倍,能效提高了一倍。这是通过各种设计选择实现的,包括基于列的电源门控,AMD表示它可以显著延长电池寿命,并且在多任务处理时能够同时处理多达八个并发空间流。

XDNA2架构的主要功能之一是支持块浮点(BlockFP16)。简单来说,它提供了8位运算的性能和速度,但采用了额外的技巧,试图使精度更接近16位运算。值得注意的是,这也是在没有进一步量化或减少正在处理的数据大小的情况下实现的。
与其他神经网络精度优化一样,BlockFP16的目的是减少所需的计算工作量;在这种情况下,使用8位数学,而不会产生从16位数学降级的全部缺点——即降低精度导致结果较差。当前一代NPU已经可以进行原生8位处理(以及16位处理),但这要求开发人员要么优化(和量化)他们的软件以进行8位处理,要么承受停留在16位的速度损失。人工智能仍然是一个相对年轻的领域,因此软件开发人员仍在努力弄清楚多少精度才足够(这条线似乎像边缘栏一样不断下降),但基本思想是,这试图让软件开发人员鱼与熊掌兼得。
尽管如此,从技术角度来看,BlockFP16(又名Microscaling)本身并不是一项新技术。但 AMD将成为第一家支持该技术的PCNPU供应商,英特尔即将推出的LunarLake也将加入他们的行列。因此,虽然这是AMD的一项新功能,但它不会是一项独特的功能。
至于BlockFP16的工作原理,AMD自己关于该主题的材料相对较高,但我们从其他来源得知,它本质上是一种带有附加指数的定点8位计算形式。具体来说,BlockFP16对所有值使用共享指数,而不是每个浮点值都有自己的指数。例如,FP16数字不是具有符号位、5位指数和10位有效位,而是具有与所有数字共享的8位指数,然后是8位有效位。
这实际上允许处理器通过将唯一有效数字处理为INT8(或定点8位)数字来作弊,同时跳过共享指数的所有工作。这就是为什么BlockFP16性能与INT8性能大致相同:它基本上是8位数学。但是通过共享指数,软件作者可以将计算的整个数字范围窗口移动到特定范围,该范围通常超出了真正的FP8数字的微不足道的指数所提供的范围。
大多数AI应用都需要16位精度,而BlockFP16满足了这一要求,至少从AI的角度来看,它同时为移动市场带来了高性能和高精度。这使得BlockFP16成为推动AI技术发展的重要组件,而这也是AMD正在努力推进的事情。
归根结底,RyzenAI300系列移动芯片中基于XDNA2的NPU实际上是用来处理AI工作负载并以比使用图形更节能的方式运行MicrosoftCopilot+等功能。并且,通过能够提供8位性能和16位精度,这为开发人员提供了另一个杠杆,以充分利用硬件。
AMDXDNA2架构将与RyzenAI300系列一起首次亮相,它将提供解锁AIPC的关键,或者至少是微软对Copilot+的40TOPS要求所定义的。通过将BlockFP16引入方程式,AMD以8位速度实现了(接近)16位精度,使其在某些AI应用程序上具有更高的性能。总而言之,集成的NPU预计将提供高达50TOPS的计算性能。
AMD是第一家在芯片中集成NPU的x86SoC供应商,随着对片上AI解决方案的需求不断增长以解锁许多软件功能,他们希望硬件(及其代表的芯片空间)能够得到充分利用。XDNA2架构确保AMD保持领先地位,为移动市场提供稳定的性能和综合的多功能性。
RDNA3.5显卡带来视觉效果
为RyzenAI300移动系列芯片带来的另一项新技术是升级的集成显卡。AMD的RDNA3.5图形架构代表着下一代AMD图形架构的垫脚石(没有.5)。最新版本的设计旨在提高性能和效率,重点是优化每瓦性能的每一滴。值得注意的是,AMD尚未提供有关RDNA3.5的太多细节,因此我们将深入研究其主要功能和进步。

AMDRDNA3.5图形架构代表了其RyzenAI300移动SoC集成显卡的下一步,与RDNA3相比有一些显著的升级。AMD一直与ISV和开发商密切合作,以确保RDNA3.5提供AMD表示将与移动合作伙伴携手合作以提高游戏每瓦性能的所有内容。一些改进包括常规图形着色器操作,这些操作经过优化以确保一切正常运行。AMD非常注重每位性能,这不仅减少了内存访问时间,还使操作更流畅。改进的总体重点是功率与性能,AMD的目标是中间地带以确保更长的电池寿命,这对于移动和便携式设备至关重要。
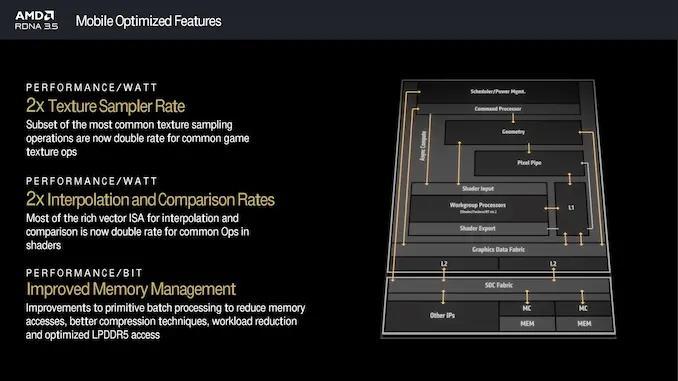
与RDNA3相比,许多改进都来自针对移动平台特别优化的多项功能。这确保了Radeon890M(RyzenAI300系列的型号)在效率和视觉性能方面兼具两者的优势。纹理采样率翻倍,确保GPU具有双倍速率性能。从表面上看,这意味着在游戏过程中纹理和图形的细节和清晰度得到增强。从理论上讲,这应该有助于改善细节纹理,使其在玩高分辨率游戏时看起来很棒。此外,RDNA3.5的插值和比较率是2倍,因为矢量ISA操作可以更好地呈现高质量图形的细节。
另一个关键改进是更好的内存管理技术。这些技术降低了内存访问频率,这意味着数据处理在理论上应该更快,总体上更节能。优化的LPDDR5访问还应保证快速高效的内存使用,从而有助于延长电池寿命。

AMD提供了一些RDNA3.5与RDNA3的性能数据,如果将其转化为实际性能,这些数据将非常令人印象深刻。从纸面上看,RDNA3.5架构与上一代Ryzen8040系列相比,性能显著提升,每瓦性能提升高达32%。在3DMarkTimespy和3DMarkNightRaid等图形工作负载中,AMD声称RDNA3.5在15W下的性能提升了19%至32%。
由于这些改进,RDNA3.5与其前身RDNA3相比在各个方面都有所改进。例如,RDNA3.5通过优化纹理采样和插值等关键内容,大大提高了GPU更有效地执行复杂图形操作的能力。改进RDNA3.5中的内存管理还可以实现更好的功率优化和数据处理,以解决主要的GPU性能问题。所有这些都应该带来实际的性能优势。然而,与任何移动SoC一样,这些仍然没有达到独立显卡的水平,独立显卡通常具有更大的芯片面积、更高的制造级晶体管预算,当然还有更高的功率。
【来源:半导体行业观察】