
【量化专题】机器学习模型理论—决策树的剪枝
来源:中信建投期货微资讯
本报告观点和信息仅供符合证监会适当性管理规定的期货交易者参考。因本平台暂时无法设置访问限制,若您并非符合规定的交易者,为控制交易风险,请勿点击查看或使用本报告任何信息。对由此给您造成的不便表示诚挚歉意,感谢您的理解与配合!
本文作者|姜慧丽中信建投期货金融工程量化分析师
本报告完成时间|2024年3月26日
摘要
决策树生成算法递归地生成决策树。这样生成的决策树对训练数据的分类很准确,但对未知的测试数据的分类不那么准确,容易发生“过拟合现象”。所以需要用决策树的剪枝策略优化过拟合问题。
本文将针对决策树的预剪枝和后剪枝对决策树的原理进行介绍。
风险提示:本报告仅对模型作客观呈现,不具备任何投资建议。历史业绩不代表未来业绩,回测业绩不代表实盘业绩,期市有风险,入市需谨慎。
一
决策树剪枝的思想
在决策树学习的过程中,为了尽可能将训练样本正确分类,结点划分过程会不断重复,训练集自身的某些特点可能被当做所有数据具备的一般性质从而导致“过拟合”。决策树的分支越多多、层数越多、叶结点越多,越容易“过拟合”,从而导致模型泛化能力差。
为了增强模型的泛化能力,应减少决策树的复杂度、对已生成的决策树进行简化,也就是剪枝。剪枝(pruning)算法的基本思路为剪去决策树模型中的一些子树或者叶结点,并将其上层的根结点作为新的叶结点,从而减少了叶结点甚至减少了层数,降低了决策树复杂度。从基本策略上讲,决策树的剪枝分为预剪枝和后剪枝,下边将分别介绍这两种剪枝策略。
二
决策树损失函数
决策树的剪枝往往通过最小化决策树整体的损失函数实现,本文首先介绍损失函数。设树T的叶结点个数为|T|,t是树T的一个叶结点,该叶结点有Nt个样本点,其中类别k的样本点有Ntk个,k=1,2,...K,Ht(T)为叶结点t上的经验熵,α≥0为参数,所以决策树的损失函数可以定义为:
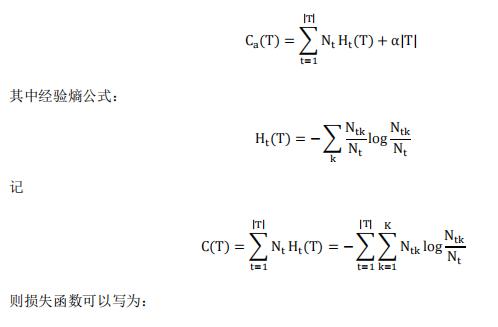

C(T)是模型对训练数据的预测误差,表示模型和训练集之间的拟合程度。α|T|为惩罚项,相当于对
损失函数做了约束,|T|表示树的叶节点的个数,即表示树的复杂度,参数α≥0控制二者之间的影响,相当于α越大,叶节点的个数对损失函数的影响越大,剪枝之后的决策树更易选择复杂度较小的树,α越小,表示叶节点的个数对损失函数影响越小,α=0意味着只考虑模型与训练集的拟合程度,不考虑模型的复杂度。所以α的大小控制了预测误差与树的复杂度对剪枝的影响。
剪枝,就是当α确定时,选择损失函数最小的模型,即损失函数最小的子树。
三
决策树的预剪枝
预剪枝是在构建决策树的时候同时进行剪枝工作,当发现分类有偏差时就及早停止。比如决定在某个节点不再分裂,则一旦停止,该节点就成为叶子节点。
预剪枝的方法有很多,如:
1、提前设定决策树的高度,当达到这个高度时,就停止构建决策树;
2、当达到某节点的实例具有相同的特征向量,也可以停止树的生长;
3、设定某个阈值,当达到某个节点的样例个数小于该阈值的时候便可以停止树的生长,但这种方法的缺点是对数据量的要求较大,无法处理数据量较小的训练样例;
4、设定某个阈值,每次扩展决策树后都计算其对系统性能的增益,若小于该阈值,则让它停止生长。
预剪枝的显著缺点是无法预知下一步可能会发生的情况。假设当前决策树不满足最开始的构建要求,进行了剪枝,但实际上若进行进一步构建后、决策树又满足了要求,这种情况下,预剪枝会过早停止决策树的生长。
四
决策树的后剪枝
后剪枝是人们普遍关注的决策树剪枝策略,与预剪枝恰好相反,后剪枝的执行步骤是先构造完成完整的决策树,再通过某些条件遍历树进行剪枝,其主要思路是通过删除节点的分支并用叶节点替换,剪去完全成长的树的子树。
目前主要应用的后剪枝方法有四种:悲观错误剪枝(PessimisticErrorPruning,PEP),最小错误剪枝(MinimumErrorPruning,MEP),代价复杂度剪枝(Cost-ComplexityPruning,CCP),错误率降低剪枝(ReduceErrorPruning,REP)。
4.1 错误率降低剪枝法
该方法将数据集分为训练数据集和测试数据集,训练数据集用来训练生成决策树模型,测试数据集用来预测决策树模型精度。通过对比剪枝前后决策树模型对测试数据集的预测精度,决定是否进行剪枝处理。如果修剪后的决策树预测精度没有降低,则进行剪枝处理,否则不进行剪枝处理。
错误率降低剪枝法(REP)是一个比较简单的决策树剪枝方法,但是,由于使用独立测试集,与原始决策树相比,修改后的决策树可能偏向于过度修剪,这是因为一些在测试数据集中没有出现过的训练数据集所对应的分支很容易被修剪掉。
4.2 悲观错误剪枝法
与REP方法相似,悲观错误剪枝法采用对比剪枝前后决策树模型的精度决定是否进行剪枝处理,不过该方法引入了统计学上连续修正的概念弥补REP缺陷。
使用PER方法进行决策树剪枝,必须满足的条件为:
Esubtree=<Eleaf+S(Esubtree)
其中,Esubtree表示剪枝前子树各叶子节点误判次数,Eleaf表示剪枝后叶子节点误判次数,S(Esubtree)表示剪枝前子树误判次数的标准差。
假设子树误差的精度满足二项分布,根据二项式性质,Esubtree、Eleaf和S(Esubtree)三者的计算公式为:
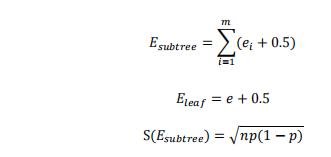
其中,ei为剪枝前决策树第i个叶子节点误判次数,e为剪枝后叶子节点误判次数,p为剪枝前子树误判率(p=Esubtree/N,其中N为子树样本量)。
另外,上述公式中0.5为修正因子,由于子节点是父节点进行分裂的结果,从理论上讲,子节点的分类效果总比父节点好,分类的误差更小,如果单纯通过比较子节点和父节点的误差进行剪枝就完全没有意义。因此对节点的误差计算方法进行修正,修正的方法是给每一个节点都加上误差修正因子0.5,在计算误差的时候,子节点由于加上了误差修正因子,就无法保证总误差低于父节点。
4.3 代价复杂度剪枝法
一棵完整决策树的非叶子节点为{T1,T2,T3,……,Tn},计算所有非叶子节点表面误差率增益值(α值),该方法通过修剪表面误差增益最小的非叶子节点,完成对决策树的剪枝处理,表面误差增益值的计算公式为:
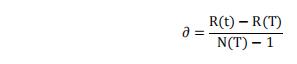
其中,R(t)为叶子结点误差代价,R(T)为子树误差代价,N(T)为子树节点个数,R(t)和R(T)计算公式如下:
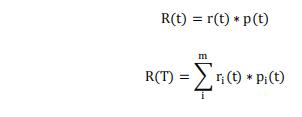
其中,r(t)为节点的错误率,p(t)为节点数据量的占比;ri(t)为节点i的错误率,pi(t)为节点i的数据量的占比。
五
总结
本文介绍了决策树剪枝的原理。
预剪枝和后剪枝方法比较上:一是后剪枝决策树一般比预剪枝决策树保留更多的分支;二是一般情况下,后剪枝决策树欠拟合风险较小,泛化性能往往优于预剪枝决策树;三是后剪枝决策树训练时间比预剪枝决策树和未剪枝决策树要大很多。
