
云顶财说 | 吴育辉、刘忻忻、陈韫妍:债券违约预警模型的优化与提升——基于SMOTETomek-GWO-XGBoost的方法
债券违约预警模型的优化与提升——基于SMOTETomek-GWO-XGBoost的方法
吴育辉1,2 刘忻忻2 陈韫妍3
(1厦门大学人工智能研究院、2厦门大学管理学院、3厦门国家会计学院)
【摘要】自2014年我国债券市场首例违约事件发生以来,债券违约屡见不鲜。本文以2014-2022年发行的公司债、企业债和中期票据为研究对象,选取财务指标与非财务指标,搭建了基于机器学习算法SMOTETomek-GWO-XGBoost的债券违约风险预警模型。结果表明:①与其他模型相比,GWO-XGBoost模型在准确率、召回率、未加权平均召回率以及AUC值这四个指标上具有更加优异的表现;②SMOTETomek采样方法可以有效平衡数据样本,因此SMOTETomek-GWO-XGBoost模型具有更高的精度与稳定性;③SHAP值法可以展示不同特征变量对债券违约风险的贡献度,有利于对重要特征进行针对性分析。
【关键词】债券违约风险;风险预警;机器学习;GWO-XGBOOST;SMOTETomek
【期刊】《会计之友》2024年第6期
【文章内容】(经删减)
一
引言
截至2022年末,我国债券市场总存量已经达到了141.22万亿元,同比增长8.2%,这一庞大规模和快速增长的数据显示出中国债券市场持续蓬勃发展的态势。但值得注意的是,自2014年第一只违约债券出现以来,债券违约事件屡见不鲜。根据Wind数据库的统计显示,2022年我国债券违约总金额为861.95亿元,新增违约主体37家,新增违约债券152只。在实体经济的发展过程中,债券市场扮演着促进企业投资、融资活动的重要角色。然而,近年来屡屡发生的违约事件也暴露出债券市场存在着一定的信用风险。通过分析债券违约的原因,本文希望找到防范化解债券违约风险的有效途径,从而为我国债券市场的高质量发展提供有益参考。
债券违约事件的发生,不仅与宏观经济环境及监管政策的变化密不可分,也与公司层面的经营财务表现密切相关。此外,Bao等[1]研究发现,相比于现有的大多数以解释样本欺诈行为并强调因果推理为主要目的研究,使用集成学习构建的预测模型可以更准确地对会计欺诈行为进行预测。因此,本文将从宏观和微观层面入手,结合财务指标与非财务指标,运用机器学习的方法对债券违约风险进行预测。
本文以我国2014-2022年企业债、公司债和中期票据为研究对象,结合SMOTETomek(SyntheticMinorityOversamplingTechnique–TomekLink)采样算法以及GWO-XGBoost(GreyWolfOptimizer–ExtremeGradientBoosting)算法,构建债券违约风险预警模型。实证结果表明,该机器学习模型有较好的违约预测能力,在准确率、召回率、未加权平均召回率以及AUC值(ROC曲线下的面积)四个指标上均有不错的表现,为后续债券违约分析和预警提供了思路和依据。
二
研究设计
(一)指标选取
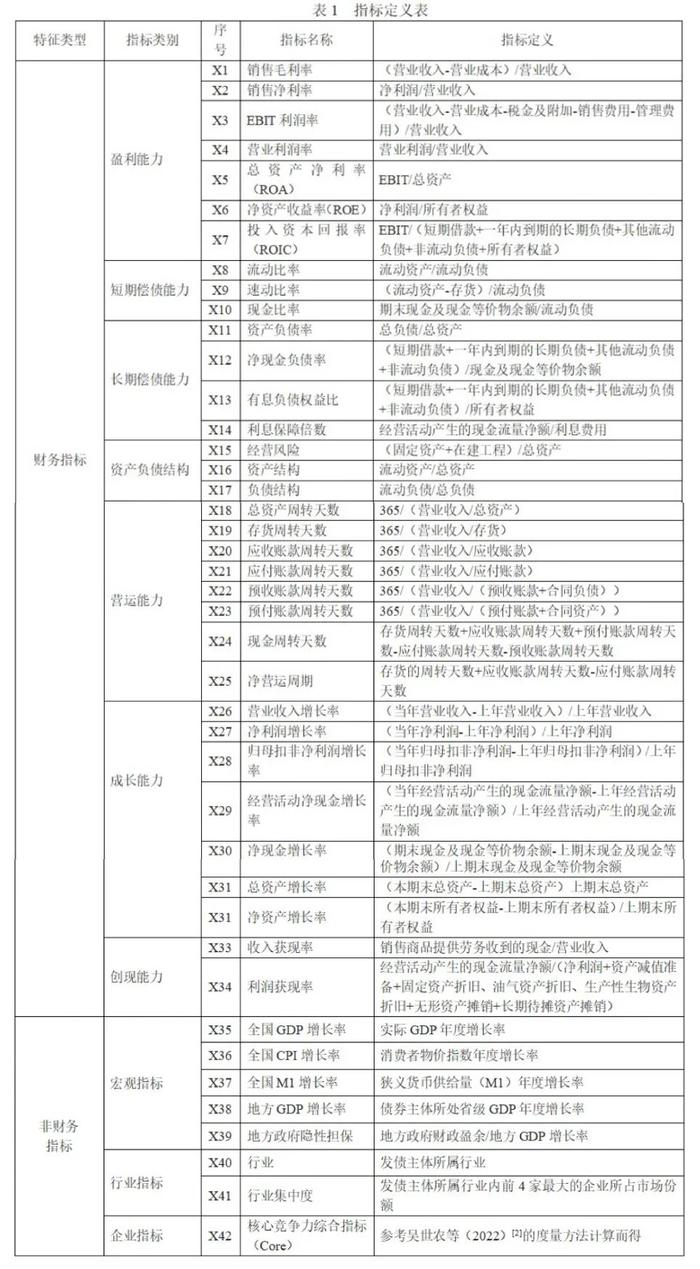
(二)数据选取与处理
本文数据来源于Wind数据库。考虑到首次出现实质违约的样本可能不具代表性,并且删除发行日期早于2014年的样本也有助于调整小类别样本的比例。因此,本文选择了2014年1月至2022年12月之间发行的债券作为研究对象。由于已到期债券未来没有违约的可能,本文选取已到期非违约公司债、企业债和中期票据数据作为模型的正向样本,同时选取了在此期间发生违约的全部公司债、企业债和中期票据数据作为模型的负向样本,即违约样本。样本去重后,得到正向样本8002条,负向样本346条,总体样本8348条。在匹配核心竞争力指标(Core)且剔除样本缺失值后,得到本文最终样本共计1279条,其中债券违约样本106条。此外,本文对财务数据进行了上下1%的winsorize缩尾处理,并对样本缺失值采用各属性的行业中值来填补。由于债券发行前3年披露的数据能够提供较为全面的历史信息,有助于捕捉可能对违约风险产生影响的因素,本文以债券发行前3年的数据作为样本,以考察各项财务指标的表现。
(三)研究模型介绍
机器学习模型众多,在此本文选取文中重点使用的三种模型及算法进行简单介绍。
1. XGBoost模型
XGBoost(EXtremeGradientBoosting)是一种集成学习算法,它结合了梯度提升算法(GradientBoosting)和决策树模型,被广泛应用于回归和分类问题。该算法采用Boosting思想中的加法模型,通过逐步构建一系列弱分类器,并将它们的预测结果进行集成来提升整体性能。
2. GWO算法
XGBoost模型的参数选择对模型的预测结果具有重要影响。本文选择灰狼优化算法(GWO)来优化XGBoost模型的学习率(learning_rate)、弱分类器个数(n_estimators)以及最大深度(max_depth)的参数设置,并应用GWO-XGBoost模型来预警企业债券违约风险。灰狼算法是一种启发式优化算法,它由灰狼的种群机制推演而来,通过对掠夺行为的不断迭代,最终找到最佳解。该算法具有搜索速度快、易得到全局最优解和稳定性较强等优势。
3. SMOTE-Tomek采样模型
SMOTE和TomekLinks是两种常用的处理不平衡数据集的方法。它们可以结合使用,形成一种称为SMOTE-Tomek的组合方法。SMOTE-Tomek算法首先使用SMOTE对少数类别进行过采样,创建合成样本,然后使用TomekLinks方法删除生成的合成样本与原始样本之间的胶着样本对,以改进不同类之间的分离程度。这种组合方法旨在增强不平衡数据集的分类性能,并为少数类预测提供更稳健的模型。
(四)评价指标
选择适当的模型评价指标对于准确评估和比较不同模型的性能至关重要。由于债券违约风险预测问题本质上是二分类问题,本文采用在不平衡二分类问题中常用的准确率(Accuracy,表示模型预测正确的样本占总样本的比例)、召回率(Recall,衡量模型正确预测为正例的样本占实际正例样本的比例)、未加权平均召回率(UAR,表示每类数据样本召回率的平均值)以及AUC值(度量二分类模型预测结果的整体性能),作为模型的评价指标。
三
实证结果
由于非财务指标中的核心竞争力指标是从上市公司年报中提取而来,因此在结合该指标后,样本量会有较大幅度的减少。为了系统地探究不同模型在债券违约风险预测方面的性能,以及不同特征与违约行为之间的联系,本文将实验划分为三个部分:第一部分,分别验证不同模型基于财务指标以及全部指标的债券违约预测能力;第二部分,利用SMOTE-Tomek采样算法对模型进行优化;第三部分,使用SHAP值法分析各指标对债券违约预测的影响力。
1.不同模型的债券违约预测能力对比
本文对七个常用的机器学习模型进行了比较和分析,这些模型包括GWO-XGBoost、XGBoost、ANN、RF、KNN、SVM以及LR。
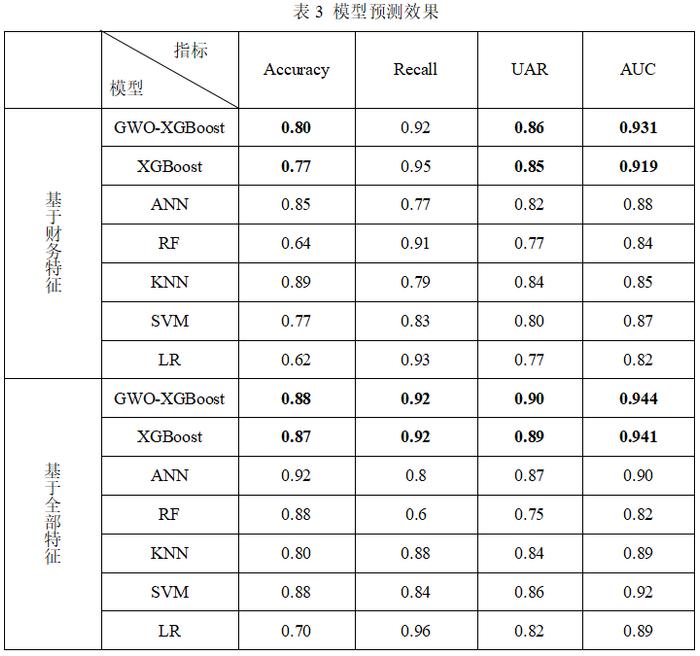
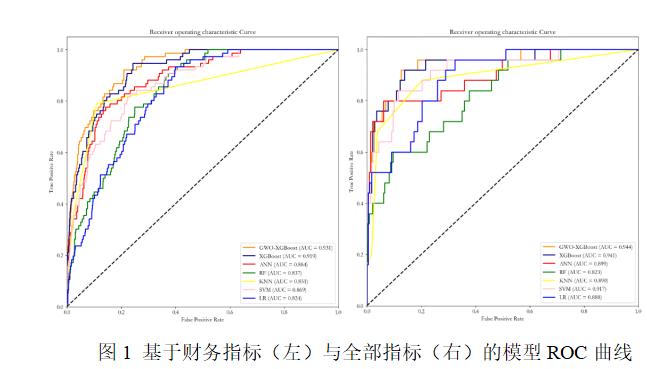
根据表3以及图1可知,无论是基于财务特征还是全部特征,XGBoost模型的综合性能都优于其他5个模型。而经过GWO算法优化后,基于财务特征的XGBoost模型在Accuracy、UAR和AUC值这三个指标上都有明显的提高;经过GWO算法优化后,基于全部特征的XGBoost模型在四个指标上的表现较默认模型均有所提升。
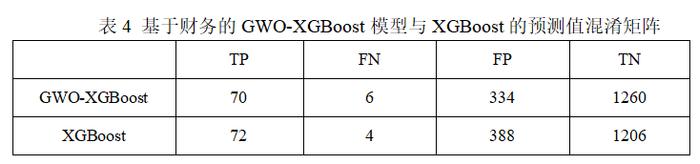
通过观察基于财务特征的GWO-XGBoost模型与XGBoost模型的预测值混淆矩阵(表4)可以发现,由于GWO算法以准确率为优化目标,且数据的不平衡性较强(即债券违约样本数量较少),因此,在提高准确率时,可能会导致少量违约样本被错误分类,进而造成召回率的小幅下降。但值得注意的是,优化后的模型的UAR值与AUC值更高。其中,UAR指标只关注自类数据,即分别在正样本和负样本中观察相关概率问题,因此,该指标可以无视样本不均衡的情况,对模型进行客观评估。而AUC指标的计算方法同时考虑了学习器对于正例和负例的分类能力,因此,该指标在样本不平衡的情况下,同样可以对分类器做出合理的评价。由此可知,当模型具有更高的UAR值与AUC值,可以说明该模型对于不同样本的识别能力更强且综合表现更好。上述结论可以表明,基于本文中的数据样本,使用GWO算法对XGBoost模型进行优化可以提升模型的性能。
在引入非财务指标后,由于上市公司数量较少,样本的数据量也有了较大幅度的缩减,这导致模型可以学习到的信息减少了。然而,与仅使用财务指标的模型相比,使用全部指标的模型的准确率以及UAR值都有所提高,同时,AUC值也有显著提高。这表明虽然样本数据的减少会对模型的训练造成一定的影响,但使用更全面的指标能够弥补这一缺点,并提高模型的性能。使用全部指标的模型能够更好地识别出正例并且减少误报率,具备更高的实用性和可靠性。
2.引入SMOTETomek采样算法
使用SMOTETomek采样算法后,原始数据经过重新平衡,得到了以下分类情况:非违约样本数量与违约样本数量的比例为1:1。具体而言,仅包含财务特征的样本中,非违约样本和违约样本的数量均为6408条;而包含全部特征的样本中,非违约样本和违约样本的数量均为942条。
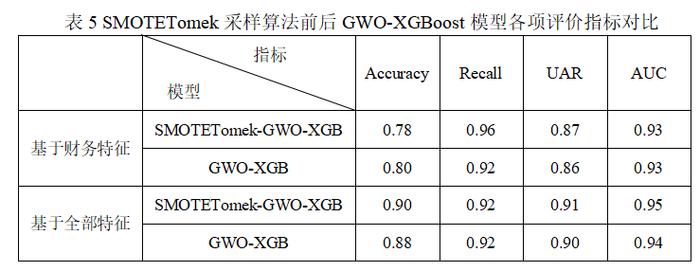
由表5可以观察到,在对数据进行SMOTETomek采样后,模型的召回率以及未加权平均召回率的值都有所提升,而AUC值和准确率变化不大。综合来看,通过采用SMOTETomek算法重新平衡数据,可以在不降低模型性能的情况下,有效提高模型对少数样本(即违约样本)的识别能力并降低模型的偏差,使模型能够更准确地判断正例和负例,并具有更高的实用价值。
3.特征重要性分析
ShapleyValue是一种为合作博弈中的参与者分配收益的方法。它衡量每个参与者对于整个合作所产生的贡献程度。在机器学习中,可以将特征看作是参与者,将预测结果看作合作博弈的收益。SHAP值基于ShapleyValue的思想,可以用来衡量每个特征对于单个预测结果的贡献。
从图2可以看出,SHAP值排名中最重要的十个特征为:地方政府隐性担保能力,预付账款周转天数(t-3),有息负债权益比(t-1),总资产同比增长率(t-2),存货周转天数(t-1),EBIT利润率(t-1),预付账款周转天数(t-2),现金周转天数(t-1),EBIT利润率(t-3)以及ROE(t-1)。而在129个特征中,核心竞争力指标的排名较为靠前,其中,C_Society排名14,C_Operation排名28,说明在进行债券违约预测时,核心竞争力指标具有较高的影响力。
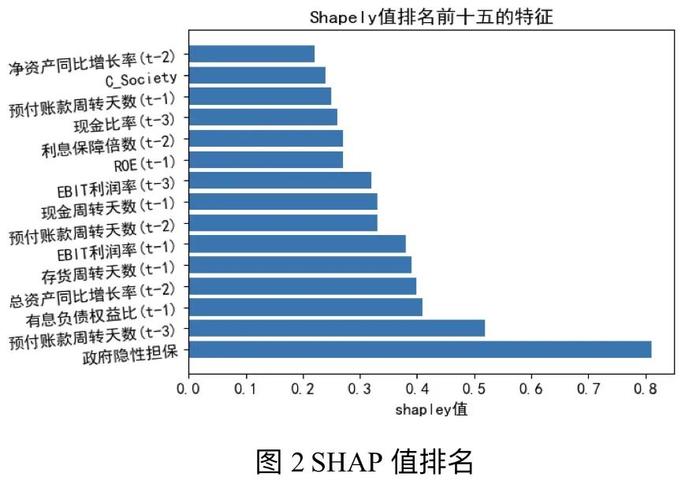
在上述指标中,最重要的两个指标为地方政府隐性担保能力以及预付账款周转天数。本文以地方政府财政盈余与地方GDP增长率的比值度量地方政府隐性担保能力。地方政府隐性担保反应了地方政府的财政实力,以及政府预算对当地国企与民企的软约束能力。由于预算软约束的存在,当企业存在资金问题时,政府可能会直接或者间接地向企业提供资金或其它方面的隐性支持,以缓解企业的经营压力、降低其破产风险。因此,债券发行人所属地区的财政实力越强,该债券对应的违约概率相对越小。
预付账款周转天数是衡量企业经营效率的一个指标,它反映了企业通过销售所获得的预付款项从销售到收回所需的平均时间。高预付账款周转天数表明企业预付款项和合同资产的资金占用情况较为严重,资金使用效率和运营效率较低。同时该指标越高,表明企业对于供应商或客户的议价能力较弱,处于供应链中弱势地位,竞争力较弱。综上,普遍来说,高预付账款周转天数越高,企业的经营风险越大。
总体来说,地方政府隐性担保能力以及企业的预付账款周转天数都与债券违约概率之间存在关联,但并不能单独决定债券违约的发生。不能简单地理解为高预付账款周转天数等价于高违约概率,或者高隐性担保能力等价于低违约概率。违约概率受到众多因素的综合影响,包括行业情况、市场环境、经营策略等。对于违约成因的分析也应该综合考虑多个指标,并结合具体情况进行评估。
四
研究结论
本文以中国2014-2022年发行的公司债、企业债和中期票据为研究对象,为了提高模型结果的准确性和可靠性,本文采用了多种性能评估指标,如准确率、召回率、未加权平均召回率和AUC值。对比分析了基于财务特征和全部特征的情况下,GWO-XGBoost模型与其他5个基准模型以及未优化的XGBoost模型间的性能差异,以及在使用SMOTETomek采样算法前后的GWO-XGBoost模型的性能差异。最后,本文采用SHAP值法对指标重要性进行了分析,以解释模型结果。
实证结果表明:第一,本文所用的GWO-XGBoost债券违约风险预警模型具有较好的泛化能力、更高的预测精度以及更强的稳定性,能够对债券的违约行为进行有效预测。第二,在结合SMOTETomek采样算法后,模型的召回率以及UAR值都得到了提高,可以说明SMOTETomek具有平衡样本和改善模型分类性能的作用。第三,应用SHAP值法可以定量展示不同特征对债券违约风险的影响力,增加机器学习模型的可解释性,避免了违约风险预测过程中的“黑箱”问题。此外,本文根据SHAP值排名的结果,重点讨论了SHAP值排名前两位的指标,即地方政府隐性担保能力和预付账款周转天数与债券违约风险之间的关系。第四,值得注意的是,当数据量过少时,可能会导致过拟合的现象发生。因此,在应用机器学习模型解决实际应用问题时,应该关注数据量变化带来的影响。
本文研究将基于SMOTETomek-GWO-XGBoost机器学习方法引入财务学领域研究,并通过与其他机器学习方法的比较,证明了其对债券违约预警具有重要的帮助和作用。更具体地说,本文的主要贡献体现为两个方面:一、在研究方法上进行改进。通过总结已有的文献可以发现,单一预测模型的效果往往有限。为了更好地提高预测的精度,可通过引入智能优化算法的方式来解决。相比传统的XGBoost机器学习模型,本文先以GWO智能优化算法对其进行优化。通过利用GWO算法计算出最优的弱分类器数量(n_estimators)、学习率(learning_rate)以及最大深度(max_depth)的方式,对XGBoost模型的参数进行调优。在此基础上,鉴于债券样本非平衡的特点,本文使用SMOTETomek采样算法,有效提升了小类别样本(即违约样本)的识别率。二、在选取非财务指标上进行改进。本文创新性地引入了从上市公司年报中提取出的核心竞争力指标,并且发现该指标的加入对提升债券违约预警模型的性能有较大的帮助。
在后续的研究中,可以进一步挖掘更多与公司经营管理、发展战略、行业特征、宏观环境方面相关的信息,提高财务风险预警的准确性、有效性和及时性,为防范化解重大金融风险提供支持。
【参考文献】
[1]BaoY,KeB,LiB,etal.DetectingaccountingfraudinpubliclytradedUSfirmsusingamachinelearningapproach[J].JournalofAccountingResearch,2020,58(1):199-235.
[2]吴世农,唐浩博,张腾.中国国有上市公司的核心竞争力研究[C].2022年度“中国资本市场与国资国企改革”国际学术研讨会,2022.