
历史与AI的距离|AI在古典学中的应用
2023年,高等教育(HE)领域的许多大学和政策组织都在努力制定在高等教育教学(T&L)中使用生成式人工智能的指导原则和指南。美国、英国和欧洲多所高校纷纷在课堂规定中加入了关于AI使用的规范和要求。教师们对AI的态度相差甚远。有些老师完全不介意学生使用AI来辅助论文写作,甚至对这种做法持开放态度,支持AI把学生从现代语言的束缚中解放出来,让他们更多投入到问题讨论中。同时也有学者嘲讽人工智能就是“人工弱智”,认为它无法替代历史学者的工作,但没想到的是,AI已经悄无声息地迅速更新换代,超越了一部分学者翻译和整理古典语言资料的速度。几个月前,DeepL还无法处理中文术语表,而现在这已经迅速改善。“senate”可以同时对应古老的元老院和现代的参议院,人工智能对语境的把握也使得术语翻译更加精准。人工智能在古代语言材料的复原、翻译、教学和研究中扮演的角色越来越重要,其效果也备受关注,国际会议和工作坊对此展开了热烈的讨论。
如今,人工智能用于研究的可能性已超乎人们的想象。过去令人一筹莫展的焦炭纸草,如今已经无需手动展开就可探索其中奥妙。对于因公元79年维苏威火山爆发而被掩埋、因高温碳化而变得异常脆弱的纸莎草文献,研究人员利用X射线断层扫描技术对这些脆弱的卷轴进行3D扫描,随后在3D图像中精确追踪并铺平卷曲的纸莎草层。借助先进的机器学习模型,这些复杂的文字得以被准确识别。“维苏威挑战”(VesuviusChallenge)活动更是激励参赛者结合三维绘图与人工智能技术,检测并破译数字扫描后的赫库兰尼姆纸莎草纸卷轴片段中的墨迹与字母形状。纸草学之外,学界对于将人工智能应用到史料检索、古典语言训练、古典文本破译、翻译与研究都有不同程度的探索。

史料检索
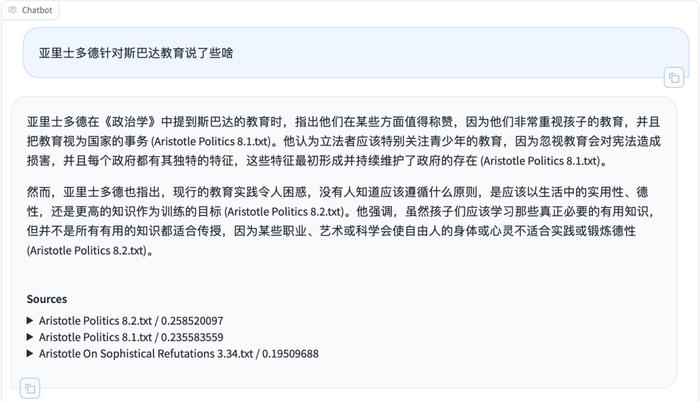
日本学者近期推出了名为HumanitextAntiqua的新型人工智能对话系统。该系统目前正处于试用期阶段,可免费供用户体验。HumanitextAntiqua旨在为古典研究领域的学者及研究人员提供一个不可或缺的辅助工具。截至目前,HumanitextAntiqua已涵盖22位西方古典作家的全集,总计约400篇文本。平台覆盖的作者与作品数量仍在持续扩展。这一系统的趣味性在于,让学者与古典文本进行对话。借助强大的上下文搜索功能和基于对话的交互模式,用户能够直观地深入探索并分析古典文学作品。目前研发团队仍在努力,致力于进一步提升检索增强生成(RAG)技术和上下文搜索功能的精确度。不过,在实际试用过程中,用中文提问给出的检索文献不尽如人意,使用英文对话的结果则更为可观。尽管数据库给出检索史料的英译文,却没有提供古希腊语原文、版本和译者信息,因此只能在整理材料时供参考,无法直接引用。
文本研究
AI在古典文本研究中的应用方式十分多样,覆盖了文本数字化、文字识别、残缺文本复原、文献定位(年代、空间、作者)、文献语言分析、文本校勘、文献翻译等诸多方面。在语言分析过程中,在文本中定位单词或字符边界的过程(Tokenization)和识别句子边界(sentencesegmentation)有助于实现古代语言分析的自动化。然而,语言和书写系统的模糊性和多样性为这两项工作带来不少挑战。将AI用于作者风格分析、文本谱系分析和互文分析则进一步为文本校勘提供参考。除此之外,AI对于文本阐释也并非毫无价值。情感分析(Sentimentanalysis)致力于从文本中提取主观信息和情感状态,而BERT技术(BidirectionalEncoderRepresentationsfromTransformers)的引进对此大有助益。
目前已经有学者尝试以计算语言学来进行荷马史诗的语言研究。JohnPavlopoulos等学者使用基于字符的统计语言模型来分析《伊利亚特》、《奥德赛》与荷马颂诗之间的语言相似性和差异,通过语言模型提取了文本中的各种特征,如词频、词序、语法结构等,由此认为荷马史诗很可能是由多个作者共同创作的,而非单一作者。计算机分析得出某些书卷之间的语言相似性很高,而另一些则相差甚远。献给阿佛洛狄忒颂诗的语言与《伊利亚特》和《奥德赛》较为接近,而献给赫尔墨斯的颂诗则相差较远。统计语言模型能够高效地将《伊利亚特》和《奥德赛》中的段落进行分类,且与学者分类结果相似。与传统的基于词汇的语言模型相比,字符级语言模型能够更好地捕捉语言的细微差异。
古典语言教学
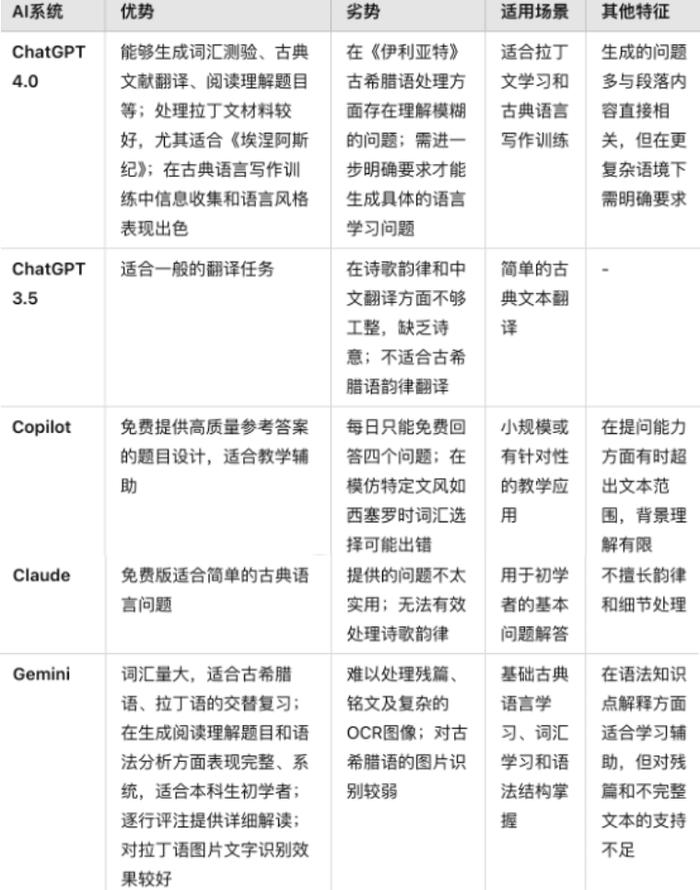
EdwardRoss在国际工作坊中介绍了在古代语言课程中使用生成型人工智能的教学经验。他和他的实验团队展示了如何运用ChatGPT4o、Copilot、Gemini和Claude等AI模型来设计古希腊语、拉丁语和梵语等古代语言的教学练习。例如,要求AI快速生成词汇测验、古典文献翻译、阅读理解题目、图像和声音。以《伊利亚特》与维吉尔的《埃涅阿斯纪》作为教学示例,Ross要求不同的AI系统分别为经典文段设计阅读理解题和古希腊语法题。
对于维吉尔《埃涅阿斯纪》的拉丁文,GPT能够提出相应的问题。然而,在处理《伊利亚特》的希腊语时,GPT提出的阅读理解问题较为模糊。于是,Ross进一步要求GPT提供语言学习方面的具体问题。Copilot每天虽然仅免费回答四个问题,但其设计的题目质量较高,并且能够给出参考答案,这在教学辅助中极具价值。不过,如果尝试让它模仿西塞罗撰写拉丁语散文,可能会遇到严重的词汇选择问题。值得注意的是,Copilot的提问能力可能超越给定的文本范围,有时会基于对整个《伊利亚特》的理解来提出问题。这在一定程度上展示了其对于历史语境把握不足,而只能给出背景性的问题。Claude免费版本提供的问题则显得不太实用。Gemini则能够阅读希腊语,并能提出一些基础性的问题,但这些问题往往不够具体细致。若要求它针对特定细节提问,Gemini会转向希腊语语法层面的问题,而较少涉及段落内容的文本阐释。

目前国内古希腊、拉丁语教学课程对于古典语言的写作训练(Composition)的要求或许还不算高,大部分高校的语言课程以阅读为主。如果需要进一步提高语言水平,古典语言写作的练习也十分重要。当我们给出一个古典学家相关的话题,要求AI进行写作训练,GPT在收集信息的准确性和语言风格变化等方面的表现远远超过Gemini。


诗歌文本翻译
古典文本中,散文的翻译难度小于诗歌。尽管AI可以自动识别较为清晰的古希腊语截图,但对诗歌的翻译仍不尽如人意。在这方面,Claude3.5无法翻译出诗歌的韵律。免费版GPT中文译文表现则不如Gemini,缺乏还原诗歌韵律的意识,即使给出体现诗歌文风的指令,中译文也不工整。





在古典语言教学中,Gemini的优势在于:首先,相较于GPT3.5,Gemini的词汇量更大。这使得它能够为学习者提供更丰富和准确的词汇学习资源。在生成阅读理解题目和进行语法分析时,Gemini展现出较为完整和系统的能力,其题目设计既基础又具有一定的挑战性,非常适合本科生等初学者群体,有助于他们逐步掌握古希腊语语法结构和阅读能力。
目前,部分国内高校无法同时开设古希腊语和拉丁语的课程,学生也可能没有充分的时间和精力同时兼顾两门语言课。面对学过其中一门语言,但又需要保持熟练度的同学,Gemini等AI可以辅助古希腊语和拉丁语的交替复习。

语法知识点解释:

Gemini一个显著的劣势在于它暂时无法有效处理残篇、铭文以及通过OCR(光学字符识别)技术从图像中提取的古希腊语文本。残篇往往因为保存状况不佳、书写风格各异或存在模糊、断裂等问题,难以自动识别和分析。Gemini在这方面的不足,限制了其在某些特定研究领域的应用范围。

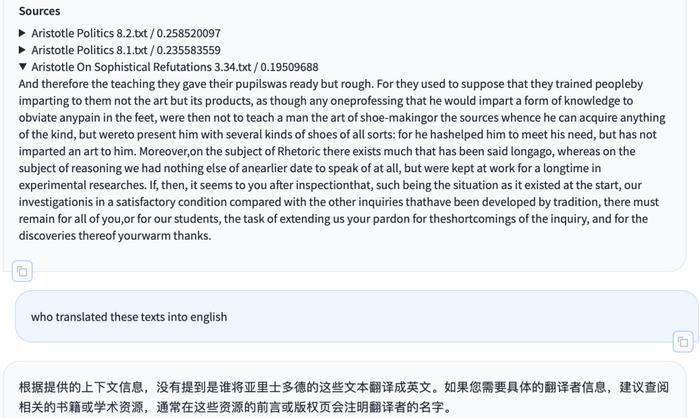
文字识别方面,Gemini对于图片中的拉丁语文字识别较为有效,但对于照片中的古希腊语则相对较弱。但Gemini就像善良的路人一样,在无法回答问路人寻求的具体方向时,依然尝试向路人提供一些别的帮助,例如给出相关的语言学习资源和软件。但AI的识别能力提升速度十分迅速,仅仅在初次提问的2个月后,Gemini已经能给出较为粗糙且存在错误的答案了。(Μήγὰρτοῦτοτὸνγ᾽ὡςἀληθῶςἄνδραἐάτεονἐστί.)GPT给出的识别结果也同样不完全准确。(Μὴγὰρτοῦτοτόνγεὡςἀληθῶςἄνδραἐάτεονἐστίν.)
对于教师而言,AI目前对于古代语言的教学还算不上具有颠覆性,不过是锦上添花,能丰富课堂的趣味性,协助设计和批改课程作业。在少许欧洲高校将教室现代化的过程中,教室的黑板占据的空间越来越小,甚至消失了。这在一定程度上也影响了传统的课堂板书。甚至有语言专业的课堂由于黑板太小,教师改为用投屏的方式以电子笔进行批注和输入来呈现板书。如此一来,AI的自动联想输入有助于提升电子化课堂学习的效率。
对学生而言,AI目前的弊端也不可忽略。不少学生向AI提问单词含义之后不再翻查字典。在文本语境缺失的情况下,用AI来查单词暂时是不可取的。不过,近期嵌入浏览器的的AI能够更好地解决这一问题,通过阅读网页内容更准确地提供词汇的含义。首先,不少AI由于缺乏词典数据的支持,目前仍然不足以支持阅读多种诗歌文本。对于复杂的多方言文本,AI无法准确识别难度较大的词形变化,时常给出错误的词汇含义。其次,AI给出的单词义项较为单一,且缺乏常见用法与文本的展示,这对于学生的词汇积累十分不利。与此同时,询问AI单词含义使得学生不再思考古希腊语词形变化的规则。如果不要求AI提供古希腊语的词汇原形,学生也丧失了记住单词的机会。

铭文识读与翻译
如果说古典语言散文的翻译相对较为容易,具有格律的诗歌较为困难,AI对于碑铭、纸草等残篇的解析能力又如何呢?AI似乎能较为轻松地处理简单且已经具有现代语言译文的希腊拉丁铭文残篇。我们可以在Chrome等浏览器中嵌入Sider,这样一来,打开碑铭文本https://epigraphy.packhum.org/等网站之后,用鼠标勾选文本,Sider能够即时开启对铭文的翻译工作。


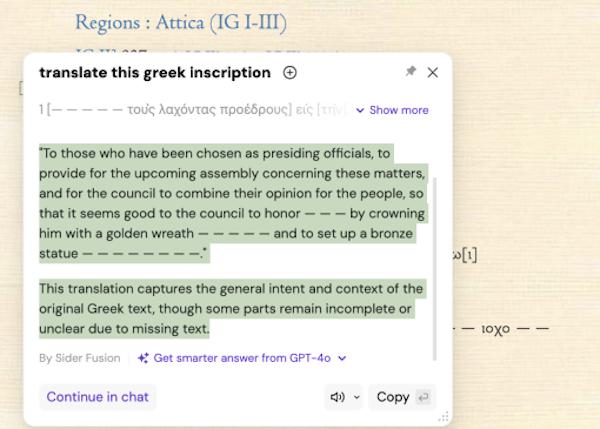
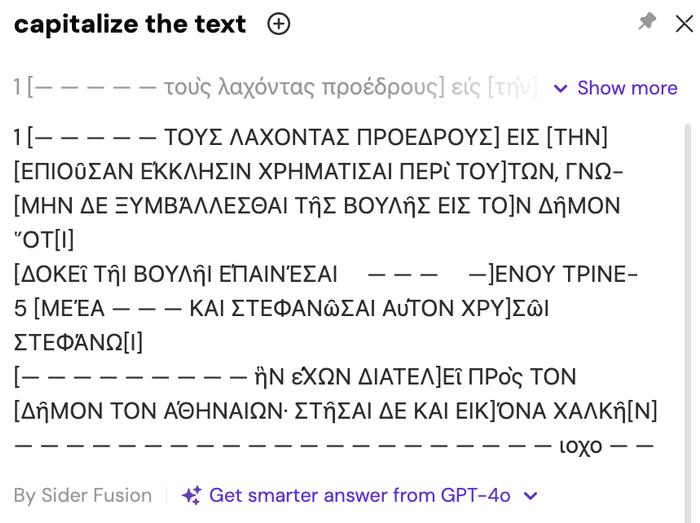
遗憾的是,将免费AI用于在碑铭训练时,大小写的转换则不尽人意。当我们要求Sider把希腊语小写文本转化为大写希腊字母时,结果出现了ΗΩ等字母的转化错误和局部失败。而且,承载着铭文的石碑本身所具有的物质属性和字母形态是AI转换的文本无法呈现的。因此,在碑铭学课程中,使用传统的图片来进行转写练习更为可靠。
当没有古代语言基础的学生练习史料检索、筛选一篇碑铭是否为所需史料时,AI的译文或许可以派上用场。不过,在研究中进行铭文翻译仍然无法脱离人工校对。在涉及跨行和破损严重的残篇时,AI的翻译不尽如人意。即使面对较为完整简单的荣誉铭文,AI的翻译也时常存在一些问题。

碑铭文本具有高度程式化的表述,AI处理较为简单的丧葬铭文和荣誉铭文基本不在话下,但面对较为复杂的法令铭文,尤其是残篇,其翻译表现则有待提升。目前国内的古代史教学中,有条件开设碑铭学课程与训练的高校仍属少数。对于没有现代语言译文的碑铭史料,许多学生几乎不会尝试去探索和使用。但若没有古代语言的基础,学生也不具备校对AI译文的能力,在这种情况下借助AI的铭文译文也是十分危险的。或许,目前AI翻译碑铭与纸草的能力能为学生的论文写作增添一个史料的脚注吧。
如果说AI在碑铭翻译方面为研究带来便捷,能够提升初学者浏览和整理史料的速度。那么DeepMind开发的Ithaca项目对古希腊铭文的破译与研究的推动则更具革命性。早在2019年就出现了Pythia这一利用深度神经网络从受损文本输入中恢复缺失字符的古文字修复模型,将最大的古希腊铭文库PHI转换为机器可操作文本(PHI-ML)。而Ithaca项目不仅能够修复残缺的铭文,还能为碑铭的铭刻时间与地理位置提供参考。值得注意的是,Ithaca的输出结果并非单一答案,而是提供多种可能性,这为研究者提供了丰富的参考与借鉴方向。

然而,数据库的封闭性减缓了AI学习能力的提升速度。目前Ithaca项目的数据库主要依赖于希腊铭文公共数据集(例如ThePackardHumanitiesInstitute’sSearchableGreekInscriptions),对博睿出版社最新的《希腊铭文补编》(SEG)和碑铭学年鉴(AE)等最新数据未能全面纳入。开源问题一旦不复存在,Ithaca应用很可能成为未来碑铭学教学中不得不加入的实践环节。
碑铭学的数字化也成为近年来学界讨论的一大议题。第九届Epigraphy.info研讨会将于2025年4月2日至4日在丹麦举行。该会议由过去的社交网络项目和奥胡斯大学历史和古典研究系的实验室主办,将数字铭文的研究人员和爱好者聚集在一起,讨论当前趋势和问题(参阅https://epigraphy.info/)。

用AI可能会错过什么?
在依赖AI的过程中,阅读古典语言本身的快乐和痛苦则可能被校对译文准确性的烦劳取代。对于还未掌握古典语言和现代语言的学生而言,偷懒取代了熟悉词形变化和方言变化的学习机会。高效率和机械化的工作方式可能会打破漫游古代世界的闲暇感,这或许是这个时代选择古典学的人们一直试图抵抗的洪流。
在阅读碑铭的过程中,观察字母形态的变化、刻写方式的变化、铭文的物质特征都是让读者津津乐道的事情。相比一键生成的AI译文,在“放慢速度”翻译铭文的过程中,审视既往校勘文本的读者也可能突然眼前一亮,意识到旧版本的错误,并为这一微小而无用的发现而欣喜若狂。漫游在碑铭博物馆中欣赏形形色色的石碑,一位学者可能突然意识到眼前的残碑是另一组残片的一块。遗失已久的拼图终于再现完整面貌。这种在场感和成就感也是用AI拼合铭文图片无法感受的快乐。
现代AI工具如此便捷,不少碑铭学家对此或许也只是一笑置之。因为在希腊罗马的碑铭中自如穿梭,在办公室里一边翻转角度审视碑铭照片,一边挠头破解藏匿在腐朽碑面隐隐约约的一个个字母痕迹,拼凑出完成的碑铭全貌,亦是谁也无法剥夺的研究乐趣。