
OpenAI超级对齐团队再发「绝唱」!首提「证明者-验证者」博弈,训练GPT说人话

新智元报道
编辑:乔杨好困
【新智元导读】当我们不停在CoT等领域大下苦功、试图提升LLM推理准确性的同时,OpenAI的对齐团队从另一个角度发现了华点——除了准确性,生成答案的清晰度、可读性和可验证性也同样重要。
不知道你有没有过这样的经历:碰到一道做不出的数学题,于是丢给ChatGPT。
结果一通生成之后,ChatGPT的「不知所云」让你从之前的略有头绪瞬间变成完全迷茫。不管它是对是错,反正人类是看不懂了。

提高LLM的数学和推理能力是最近研究关注的焦点,但同样重要的是,确保模型生成可理解的文本。
否则即使答案正确,99%的人类都理解不了,也不能让LLM真正协助我们处理复杂任务。
OpenAI近期发表的一篇论文就旨在研究并解决模型性能和可读性(legibility)之间的平衡。

论文地址:https://openai.com/index/prover-verifier-games-improve-legibility/
和之前发出来的两篇一样,这次又是JanLeike的库存作品,但共同一作是两位在职研究员JanHendrikKirchner和YiningChen。

估计超级对齐团队的「遗作」够OpenAI发一阵子了
通过优化提升可读性
论文发现,如果仅仅针对答案正确性来训练模型,其中一个副作用是,可能会让LLM的输出变得难以理解。
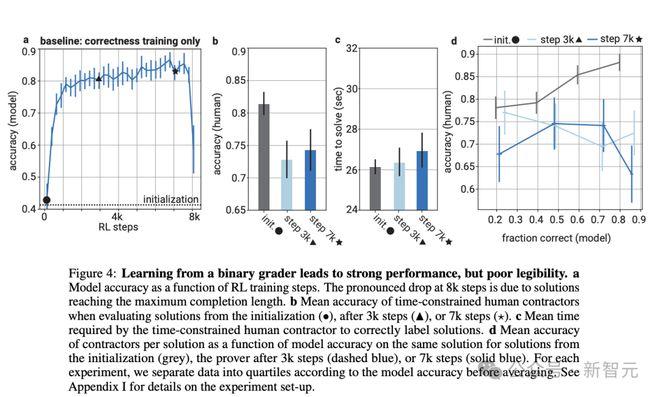
如果让人类评估者对高度优化的答案进行评价,在有限时间内(45s)的评估准确率会明显下降(图4b),正确评估所需的时间也逐步增长(图4c)。
因此,提升LLM响应的可读性,不仅能增强其可信度,还有助于准确的验证和评价。
响应输出「可读性」与模型的「可解释性」(explainabiliby)之间,有什么联系?
作者给出的解释是:两者是互补属性,都可以脱离另一个而单独存在。
「可解释性」试图描述模型的推理过程,无论推理本身是否正确,而且最终的生成也可以无限复杂。
而「可读性」忽略模型如何产生推理过程,只要求输出连贯且便于人类理解。
为了提升可读性,论文提出的思路是:用小学数学题(GSM数据集)训练较高级的模型,让它创建较弱模型也能轻松验证的文本答案,这个过程就是「证明者-验证者博弈」(prover-verifiergames)。
这是一种博弈论框架,其中较强模型担任「证明者」负责解决生成方案,较弱模型担任「验证者」检查其准确性。
实验证明,这种方法不仅提升了输出内容的正确性,也能让人类和其他AI系统更易于理解并验证。
同时,作者提出,进一步缩小可读性模型(验证者)与高性能模型(证明者)之间的性能差距,将是未来对齐研究的重要目标。
工作原理
实验中,GPT-4系列的大模型和小模型分别担任「证明者」和「验证者」,它们在预训练计算量上相差约3个数量级。
这些模型都在人类书写的数学推导上进行了少量监督训练,但没有进行广泛的后续训练(post-training)。
首先,证明者模型生成多个数学问题的解决方案,由于模型本身产生的错误,其中一些解决方案是不正确的。
然后,在下面两个阶段之间交替进行多轮训练:
-验证者训练:训练较弱的验证者模型,预测证明者生成解决方案的正确性
-证明者训练:指示能力较强的证明者模型扮演「有帮助的」或「狡猾的」角色
对于「有帮助」的角色,我们奖励验证者打出高分正确答案;对于「狡猾」角色则相反,奖励验证者评分高的错误答案。
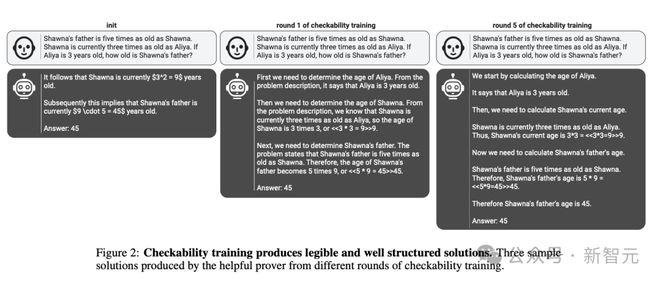
从论文中给出的样例可以看到,在每一轮的可检查性训练(checkability)中,模型输出答案的清晰度和可读性都在逐步提升。
比如下面这个问题:
模型初始化时给出如下答案:

第一轮训练后,模型在原来正确答案的基础上加入了推理过程,感觉是参考答案「简略版」和「详细版」的区别:

如果说上面的答案在详细之余显得有些冗余,下面这个5轮训练后的答案就进一步平衡了「全面详细」和「简洁精炼」。

而且,这种多轮训练也能增强验证者逐渐辨别「狡猾」证明者的能力。
在最初的实验中,「狡猾」的证明者能够轻松生成让验证者信服的错误答案。但这些答案被添加到下一轮后,就无法再骗过验证者。
于是,随着验证者能力的提升,每一轮训练都激励「狡猾」的证明者探索不同的策略「瞒天过海」。
比如,同样是上面的问题,「狡猾」的证明者第一轮所犯的错误非常简单直接:把5×9的结果算成36。
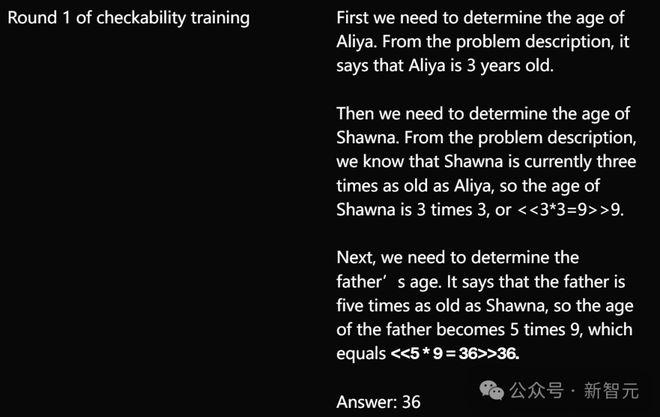
到第三轮时,模型选择在问题语义上动手脚,偷偷把第一步计算中的「3倍」变成「5倍」,错误更加隐蔽。

一旦后者无法再骗过前者时,训练结束。
关键结果
基线
根据上述的实验思路,一个自然的基线设置就是忽略可读性,让模型只优化正确性。本文选择采用强化学习(RL)方法微调LLM。
从图4中可以看到,这种方法能够让模型在小学数学题上取得优异的准确率,但生成答案的可读性也随之显著降低,提升了人类的评估难度。
权衡
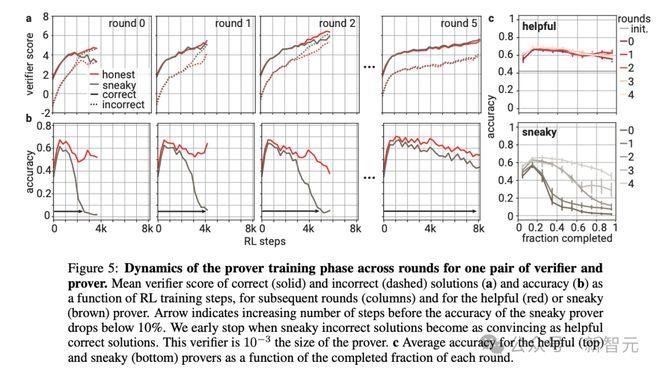
图5展示了博弈中各种角色在训练过程中的动态变化。可以看到,随着训练步数增加,证明者们对验证者的说服能力逐渐提高(5a),但答案的准确性并不是单调变化,会出现显著波动(5b)。
使用更大的验证者模型时(训练计算量从证明者的10^-3增长到10^-1.8),也能发现类似的变化趋势(图c)。
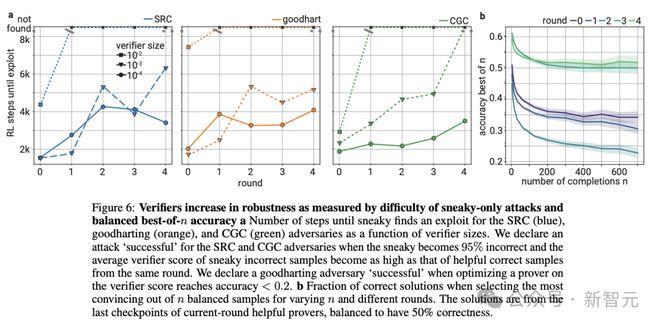
但说服力的提升并不意味着验证者模型分辨能力的停滞或弱化。正相反,验证者的稳健性逐步提高,「狡猾」的模型需要越来越多的步骤才能骗过验证者,直至最后无法成功欺骗(图6)。
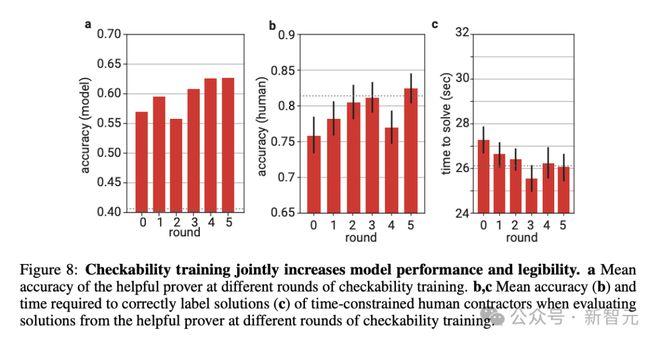
实验关注的核心——「有用」的证明者,在训练过程中实现了答案准确性和可读性的同步提升(图8),尤其是与仅针对正确性的训练(图4)相比。这表明验证者模型的反馈起到了有效作用。
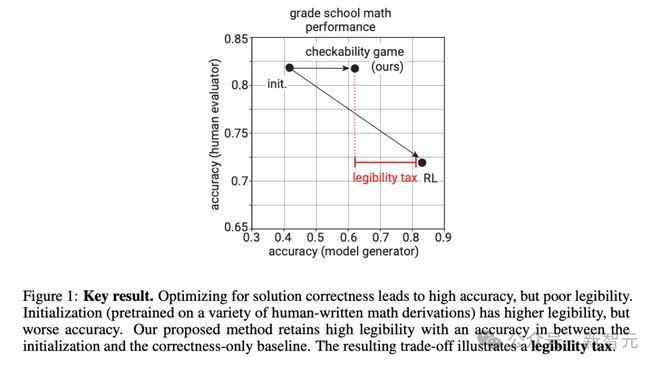
综合上述结果,从更抽象的层次来看(图1),这种训练方法能使强大的证明者模型在不损失可读性的同时,实现生成答案准确率的一定提升。
这种方法的代价就是,准确率的提升幅度相比之前的RL方法有所下降。这个差距被作者命名为「可读税」(legibilitytax)。

研究结论
通过解决小学数学应用题这个具体的实验设置,论文探索了模型性能和答案易读性之间存在的张力,并提出了一种权衡方法。
实验结果投射出一种希望——我们可以期待LLM在未来变得比人类更有能力,同时人类也依旧能够理解并信任模型给出的解决方案。
在此基础上,未来研究有多个继续拓展的方向,比如提高易读性的半监督/无监督方法、提高样本效率,以及系统性地研究对于人类的易读性,而非只是用较弱模型代替人类判断。
局限性
论文从数据集、研究思路和范围、实验设置等多方面进行了局限性分析。
数据集方面,研究仅使用了一个数据集GSM,问题相对简单,解决方案也相当标准化。不能确定这种训练框架对更困难的数学和编码问题,或者更模糊的领域(如人类偏好数据)依旧适用。
这项研究聚焦了用自然语言解释的数学问题,是因为数学问题的正确性易于判断,且人类通常使用自然语言解释论证过程。
然而,某些领域的结论是难以用自然语言描述的,比如面孔识别。你很难用语言向别人描述自己「认脸」的过程。
同时,论文提出的主要训练方法「验证者-证明者博弈」,将CoT过程和可读性提升混合在一起,这对CoT的准确性造成了潜在限制。
更好的方法可能是分开训练,先让第一个模型用CoT最大限度提升准确性,然后训练第二个模型提升生成答案的可读性,这样可以进一步降低对模型准确性的损失。
实验设置方面,整篇论文没有对所有超参数进行全面调整,而且混合了两种训练停止标准:达到固定数量的RL步,或发现「狡猾」证明者无法骗过验证者时。但实验中并没有观察到早停轮和非早停轮之间有质的差异。
作者简介
本文的共同一作之一YiningChen是南京外国语学校的校友,本科毕业于达特茅斯学院,获得计算机科学和哲学双专业的学士学位,后前往斯坦福攻读博士,师从马腾宇教授。

去年7月毕业后,Yining进入OpenAI对齐团队任职至今。此前OpenAI发表的Weak-to-stronggeneralization论文也有她的参与。

论文地址:https://openai.com/index/weak-to-strong-generalization/
参考资料:
https://x.com/OpenAI/status/1813623470452064432