
闪电快讯 | SuperCLUE评测榜单公布:科大讯飞星火认知大模型排名国内第一
5月9日,中文通用大模型综合性评测基准SpuerCLUE(ABenchmarkforFoundationModelsinChinese,下称“中文通用大模型基准”)正式发布。
中文通用大模型基准主要是针对中文可用的通用大模型的一个评测基准,它主要解决的问题是在当前通用大模型大力发展的情况下,中文大模型的效果情况,包括但不限于这些模型不同任务的效果情况、和国际上代表性模型的比较情况以及和人类对比的效果。一系列国内外代表性模型在该基准下的多个维度接受能力测试,进而得出SuperCLUE评测榜单。
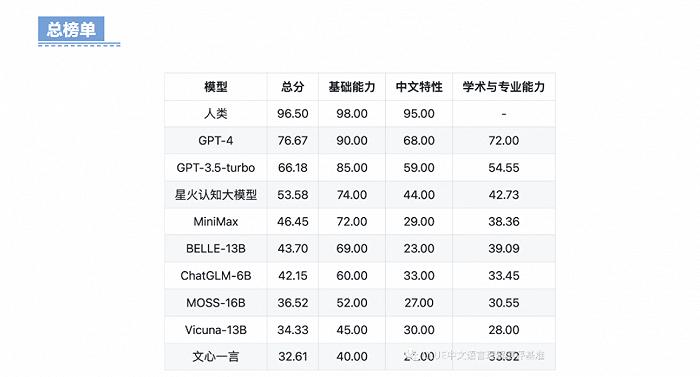
该榜单主要由总榜单、基础能力榜单和中文特性榜单构成。因为大模型处于迭代过程,并且不断涌现出新的大模型,因此SuperCLUE评测榜单计划按照月度进行更新,榜单排名会跟随周期性的测试结果而变化。SuperCLUE评测还会进一步扩充测试的数据集、选取更多的大模型以及扩大能力考察范围。
在5月9日随同中文通用大模型基准正式公布的还有第一期SuperCLUE评测榜单。科大讯飞的星火认知大模型在总榜单、基础能力榜单和中文特性榜单上均排名国内第一,其得分仅次于OpenAI推出的GPT-4和GPT-3.5-Turbo。
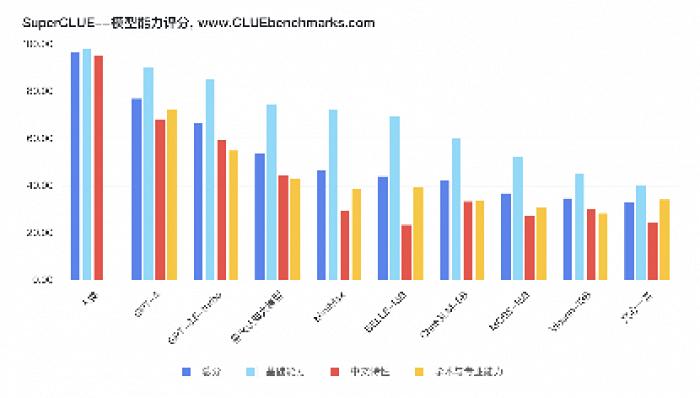
SuperCLUE评测榜单主要从三个不同的唯独评价模型的能力,分别为基础能力、专业能力和中文特性能力。基础能力包括了常见的有代表性的模型能力,比如语义理解、对话、逻辑推理等10项能力;专业能力包括了中学、大学与专业测试,涵盖了数学、物理、地理到社会科学等50多项能力;中文特性能力主要是针对有中文特点的任务,包括了中文成语、诗歌、文学和字形等10项多种能力。
除了多维度考察,SuperCLUE评测榜单还拥有自动化评测、广泛代表性和采取人类基准等特点,较为客观、全面展现当下的通用大模型的能力。
在评测中,科大讯飞的星火认知大模型以53.58分的总成绩在9个接受测试的模型中排名第三,在国内大模型中排名第一。其中,星火认知大模型在基础能力上的测试成绩为74分,中文特性测试得分为44分,学术与专业能力的测试得分为42.73分,是本次测试中表现最好的国内大模型。
测试发现,国际先进模型效果具有较大的领先性;星火认知大模型是本次SuperCLUE评测效果最好的国内大模型,与GPT-4相比有23个百分点的差距,与GPT-3.5-Turbo相比也有13个百分点的差距,但也可以看到,国产大模型经过迭代,逐步缩小了与OpenAIGPT模型的差距。
这意味着国产GPT模型和国际先进大模型有差距但仍可追赶。比如,在国际上效果良好的Vicuna-13B模型,在中文领域效果一般。星火认知大模型在总分上超过了Vicuna-13B模型20个百分点。
5月6日,科大讯飞正式对外发布星火认知大模型。科大讯飞董事长刘庆峰在发布会上透露,2022年12月15日,科大讯飞依托其承建的语音及语言信息处理国家工程实验室和认知智能国家重点实验室,正式启动认知大模型专项攻关。
科大讯飞的星火认知大模型已经具备了七大维度能力,包括文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力、多模态能力,并已在教育、办公、汽车、数字员工等行业中落地应用。