人工智能基础:第八话 “特征”、“过拟合”、“泛化”

在上两集中,我们对应用人工智能(AppliedAI)的几大领域:计算机视觉(ComputerVision)、语音识别(SpeechRecognition)、推荐系统(RecommendationSyste)以及自然语言处理(NaturalLanguageProcessing,NLP)做了初步的介绍:这些是离我们当前的生活最近的,最能够切实地帮助我们完成日常生活中特定任务的人工智能,它们日益精进的先进性、实用性和易用性,越来越多地展示出AI在实际应用中的巨大潜力,人们开始更广泛地关注和讨论AI的未来,以及AI或将替代某些工作、改变教育方式和影响信息传播方式的可能性。
今天,我们将重新返回机器学习的话题,以轻松的方式对“特征”、“过拟合”、“泛化”等一些你时有耳闻的名词做最基本的介绍。
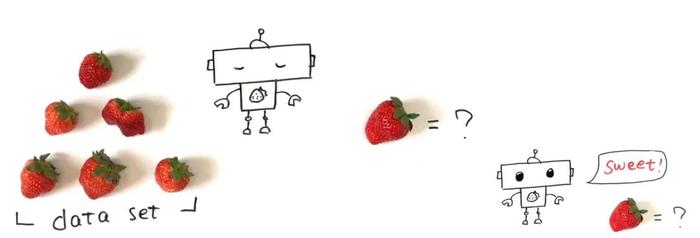
要让机器学习着认识世界,首先要有数据。
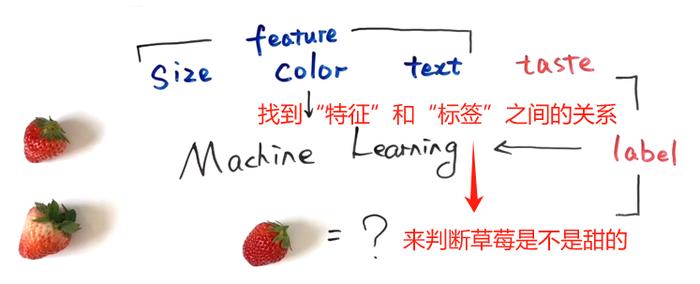
比如,要判断草莓甜不甜,就要先搜集一些关于草莓的数据。

个头较小,色泽鲜艳,质地柔软的草莓是甜的,个头较大,色泽较浅,质地较硬的草莓是酸的。
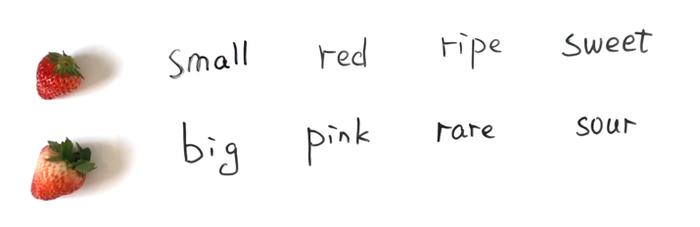
在机器学习中,大小、色泽和质地被称为特征(Feature),较小、鲜艳、柔软对应的是属性值(AttributeValue),酸和甜则被称为标签(Label)。
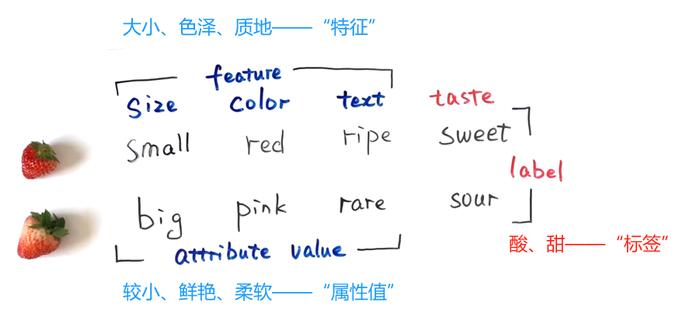
*在机器学习中:
特征(Feature):用于表示观察对象的各个方面的属性或特性。
属性值(Attributevalue):特征的具体数值或描述,代表数据在这个特征上的具体表现。
标签(Label):用于表示数据的真实结果或类别,通常在监督学习中用来训练模型识别或预测结果。
机器学习就是找到特征和标签之间的关系,来判断草莓是不是甜的。通过数据学得模型的过程就是我们常说的学习(Learning),也被称为训练(Training)。
不过在学习过程中,有时太过认真地认识已有的草莓,会造成无法判断其他草莓甜不甜的状况,这种情况被称为“过拟合”(Overfitting)。
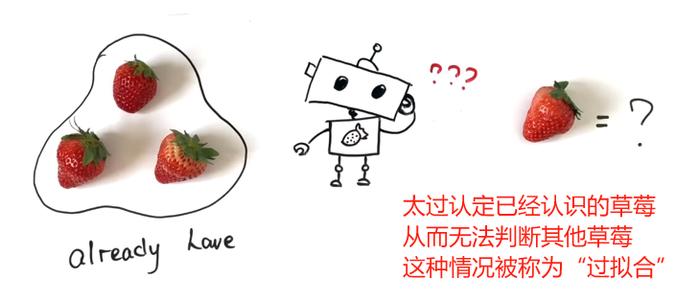
*过拟合(Overfitting)是机器学习中的一种现象,是指模型对训练数据学得太好,以至于捕捉到了训练数据中的噪声和偶然性,但这些噪声和偶然性其实并不是真实的潜在规律,从而导致模型在新的、未见过的数据上表现不佳。
往往我们希望学得的模型能够好地认识新的草莓,这种能力被称为“泛化”(Generalization)。
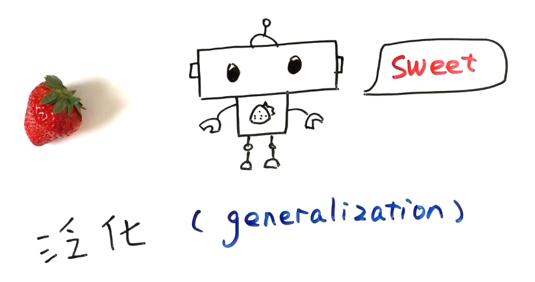
*泛化(Generalization)是机器学习中模型对新数据进行预测的能力。一个好的模型应能在训练数据上表现良好,同时在未见过的新数据上也能做出准确的预测。泛化能力是评估模型质量的重要指标。
一般来说,训练样本越多,模型的泛化能力越好,就越能判断新的草莓是不是甜的。