
当AI遇上高考数学题,4个大模型“考生”“成绩单”出炉
2024年高考已顺利落幕,让大模型写高考作文题已不稀奇,大众通常认为大模型更擅长文科,不擅长进行数学计算和逻辑推理。当AI遇上高考数学题,大模型化身为“考生”答数学题,会交出怎样的答卷?
我们选取了4名有代表性的大模型“考生”,分别是九章大模型、星火大模型(v3.5版本)、文心一言(3.5版)、智谱清言(GLM-4),选取2024全国高考数学新课标1卷客观题部分进行测评。大模型的数学能力究竟如何?其在数学学科教育场景中能够发挥多大价值?结果值得期待。
四位“考生”表现参差不齐
此次测评选取的4个大模型中,星火大模型(v3.5版本)、文心一言(3.5版)、智谱清言(GLM-4)为通用大模型,九章大模型则为以数学能力见长的教育垂类模型。
在试题选择上,为便于评价统计,统一选择了2024年数学新课标Ⅰ卷中的14道客观题进行测试,其中包括8道单选题、3道多选题、3道填空题。此外,由于试题中存在图形、大量数学符号,为防止以文本形式输入题目产生偏差,统一选择以图片形式呈现题目并提供给大模型进行解答。
四个大模型在此次“考试”中,整体表现如何?
据新京报记者统计,14道题目中,九章大模型共答对11道,星火大模型共答对12道,二者不相上下。而另外两位差别较大,文心一言共答对1道,智谱清言共答对4道。
最终统计结果显示,四位“考生”此次作答正确率从高到低依次为星火大模型(85.71%)、九章大模型(78.57%)、智谱清言(28.57%)、文心一言(7.14%)。
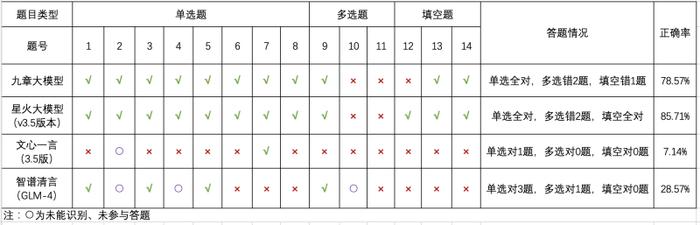
从不同题目类型的答题情况来看,九章大模型8道单选题全部答对,3道多选题答错2道,3道填空题答错1道;星火大模型单选题全部答对,多选题答错2道,填空题全部答对;文心一言仅答对1道单选题;智谱清言仅答对3道单选、1道多选(另有3道题目因大模型提示无法识别图片未参与作答)。
需要指出的是,由于测试的是客观题,上述正确率仅根据大模型作答的最终选项进行判断和统计,不涉及解题过程。但记者在测评过程中注意到,的确存在不少选项正确、但解题过程存在差错及瑕疵的情况。
部分大模型“蒙”对答案计算推理过程存在明显错误
正确率的背后受多个维度能力影响,而数学能力是此次测评关注的核心。在测评过程中记者注意到,几位“考生”在题目理解能力、计算推理能力以及解析过程的详略上,均存在差异和不同特征。
就正确率而言,星火大模型表现较好,但部分题目的计算推理过程却经不起推敲,虽然结果正确,但过程中出现了明显错误。例如单选题第1题中,星火大模型的解题步骤中提到“2不在区间(−2.236,2.236)(−2.236,2.236)内(因为它超过了上界)”,存在明显谬误,但最后却“蒙”对答案。再如单选题第2题,一位数学专业人士看到解题过程后评价称“推理的上下两行公式之间没有任何关联,也无法推导得出这个答案,为何最终选出了正确选项,令人匪夷所思。”
九章大模型的部分解题过程也存在瑕疵。在一道多选题中,九章大模型在推理中明明认为C选项错误,但最后又把C选为正确答案,“这个表述上下文之间没啥逻辑关系,让人摸不到头脑。”上述数学专业人士指出。
如果看看正确率排名倒数第一的“考生”文心一言的试卷,令人匪夷所思的地方就更多了。看完这位考生答对的唯一一道题目,上述专业人士称,解题过程中连基本的输入都有多处错误,能得出正确答案可能只是“歪打正着”。
测评中可以发现,文心一言具备读取图片内容的能力,但无法识别仅带有复杂分数的公式和图形。且读取后出现了理解错误,例如单选题第3题,明明成功读出题目中的“⊥”符号为“垂直”,却在后面的步骤中理解为“平行”(题面中未出现任何平行相关字眼或符号),经提示,文心一言发现理解错误,却在再次解答时又出现理解偏差。
实际上,从单选题第5题的答题情况不难看出,文心一言解答数学题并不是用数理逻辑,而是试图用文字论证的方式去猜测一个接近的结果。在多次提示下,它仍然执着于靠猜测来答题——“这个计算过程并不是题目所要求的,因为题目只需要我们根据给定的选项来选择答案。”
文心一言几乎对每一题都进行了详细的推理,但最终大部分题目都得出了错误的答案。在第11题,文心一言非常坦诚地做出答复,并揭示了大模型处理数学问题背后的本质:“由于我们没有具体的数学工具或方程来直接进行计算,只能根据给定的信息进行逻辑推理。因此,我无法确定任何选项的正确性。”对于第12题,文心一言也告知称“我只能提供解题的思路和步骤,而不能直接给出确切值。”
智谱清言在部分题目中也存在类似的问题。在第12题中,经过一番分析后,智谱清言告诉用户无法计算出结果。在第13题中,智谱清言重复地分析、发现问题、重新审视问题,又一遍一遍地发现行不通,进行了十轮以上的死循环,直到人工点击暂停才停下。
面对多选题,能否自行判断每个选项正确与否、有几个选项符合题目要求,对大模型来说也是一个考验。
经测试,九章大模型、星火大模型、智谱清言均能够在未提示此题目为多选题的情况下,识别出多个正确选项;而文心一言在这方面稍逊色,且在提示某题目为多选题的情况下,仍然只选出一个选项(且是错的)。
根据此次测评的整体答题情况,一位不愿具名的数学教研专家对四个大模型的表现分别作出点评。他认为,其中,九章大模型回答较为简单,缺少深入分析,部分题目的表达力度也比较低,回答也不够全面。星火大模型的分析有一定的深度和见解,但有些地方的回答不够简洁,有的题目的回答不够准确,在表述和数学符号的应用上存在一些问题。
文心一言(3.5版)思考比较全面,方方面面都会涵盖,由此推测前期建模分类分得比较细,语言表达相对来说也比较流畅。但回答特别冗长,也没有重点,答案也存在一些偏差。智谱清言的解答比较简洁,一般会直接回应题目,也有一定的逻辑性和条理性,但答案不是特别详细,也没有深入分析。有些题目的回答和标准答案的匹配度不高,有些题目虽然答对了,但会漏掉一些关键点。
大模型在“数学图形识别及图文关系理解”等方面存在短板
当大模型应用于教育场景中,除准确性这个核心要求外,如何启发学生思考、对学生进行引导也备受关注。从这个角度看,四个受测大模型均能够做到“不直接给出答案”,而是呈现解题过程,这是有别于传统产品“拍照搜题”之处。
在启发引导方面,九章大模型能够依次进行分析、详解、点睛,最后才会给出答案,但在部分题目关键重难点步骤一带而过,需要追问才会展开解答。星火大模型也能够给出解题步骤及正确结果,但较少呈现每一步背后的思路和思考逻辑;智谱清言可以从入手点开始一步一步引导解答,最终给出正确答案,但偶有分析错误、重新分析的情况出现;而文心一言在答题的每一步都会做详细的推理分析,但分析方向往往是错误的。
题目的识别读取对解题效率有较大影响。此次测试统一采取上传题目图片的方式由大模型进行识别读取,也考验着大模型的图片处理能力。
对于多选题第11题,四个大模型均未能成功识别,也是唯一一道让四个大模型“全军覆没”的题目。可以看到,四个大模型在数学图形识别及图文关系理解上,普遍存在短板。
九章大模型在图片题目识别上,会先在输入文本框中识别读取出题面,并以文本形式呈现,用户可在框内确认题目的准确性。若发现识别错误,点击即可出现数学符号的辅助输入工具栏,进行编辑修改,防止题目读取错误。
星火大模型在图片题目识别上亦未出现明显障碍,但由于并不显示识别内容,而是直接作答,因此无法确定识别结果是否影响了答题。智谱清言则在多道题目中均给出“未能识别”的反馈,需要将题目以文本形式进行人工输入,方可进行后续解答。文心一言对于图片及数学符号的识别略优于智谱清言,但复杂分数公式、图形亦识别不佳。
记者在测评过程中发现,几个大模型对上下文语境及语义的理解能力也存在差异。这一能力在教育场景中则关乎与学生的互动能否顺利达成。
记者注意到,文心一言在答数学题能力上虽然逊色,但通过一系列的追问、对话可以发现,这位“考生”对语义语境的把控能力非常优秀,很容易明白用户在说什么,在用户补充提醒的时候,它很快就可以知道根据新信息去解释上面的题目。
如果说文心一言是个不错的“文科生”,那九章大模型和星火大模型可以说是地地道道的“理科生”,虽然非常擅长解题,但上下文语义语境的理解是它们的弱势。
例如,当用户对星火大模型提出“上面这道题可以再详细分析一下吗”时,星火并不能理解指向的是什么,而是回答“很抱歉,由于我无法看到您提到的具体问题,所以无法为您提供更详细的分析。请提供问题的详细信息,以便我能够更好地帮助您。”
再如,当用户对九章大模型追问“请你检查一下这道题,D选项到底对不对”时,九章并不明白用户问的是什么,回应称“当然可以,请您提供题目的具体内容,包括选项D的表述,我会尽力帮助您检查。”说明其比较擅长解题,但很难联系上下文语境语义来与用户互动对话。
大模型的数学能力取决于算法和数据量
在大模型这一新事物面世初期,不少网友用开源的大模型去测试一些简单数学题,发现很多答案并不准确。与自然语言理解不同,大型语言模型在解决算术推理任务时性能欠佳。
九章大模型是此次四位“考生”中唯一一个、也是国内首个专为数学打造的大模型。2023年5月,好未来公布正在进行自研数学大模型的研发,是以解题和讲题算法为核心的数学垂直领域大模型,其官网显示,其数学计算能力已覆盖小学、初中、高中的数学题,题目类型涵盖计算题、应用题、代数题等多个类型。
为何不同模型的正确率及使用体验会存在差别?
中国社科院新闻与传播研究所所长胡正荣指出,大模型虽然是语言模型,但这个语言不是人们通常理解的字面意思,音频、解题等都是大模型可以做的。从理论上看,数学大模型这个技术方向是可行的,但最终结果如何,取决于两个因素,一是算法是不是足够好,二是是否有足够量的数据做支撑。
数据是大模型最基本的要素之一,如果要让大模型解题精准,那么训练大模型的数据量需要足够大。“正确率的差别,一方面是因为输入的数据量的差别造成的。”之所以大模型解数学题会出错、没有达到理想效果,就是因为训练的题库不够大,数据量越大、质量越高,精准度就会越好。
另一方面,胡正荣也强调了算法的重要性。“如果大模型的算法不够聪明,不是真正的数学思维,也会影响到答题的正确率。”
北京教育科学研究院基础教育教学研究中心中学数学教研员丁明怡指出,通过四位“考生”的答题状况可以看到,都存在答案正确但过程错误的情况。从当下情况来看,如果应用到真实教育场景中,无论是给老师用还是给学生用,都还有较大的提升空间。
此次测评暴露出几个大模型存在的几个普遍问题。第一,题目识别上存在比较大的困难,涉及一些数学符号、分式等会影响识别效果,还有一些图形、表格识别存在问题,以及一些数学专业术语的表述识别也不够精准。
第二,几个大模型在逻辑推理能力上还存在不足。逻辑推理强调连贯性、严谨性,但几个大模型这方面做得不够好,例如,经常会出现跳步,或者关键步骤缺失的情况。有时候不见得是计算错误,而是逻辑推理出现问题,导致最后结果错误。
第三是解题方法较为单一。例如此次测试的第十二题,实际上是一道中等偏下难度的题目,通常会基于双曲线的定义和性质进行求解,这样可以避免比较复杂的坐标计算、联立方程求解等,可以大幅减少计算量、节省考试时间,但是这几位“考生”在答这道题时都使用了常规方法,计算量很大、步骤也特别多。大模型似乎只能按照固定的模板去答题,而不能依据题目的特征因地制宜地选择最优方法。“如果用这样的方法指导学生,对于学生知识学习和知识结构建立都是有弊病的。”
若用于数学教育,大模型还需优化对学生的启发引导
针对上述大模型存在的普遍问题,丁明怡提出多方面建议。
首先是要提升题目的识别能力,包括术语、符号、图形、表格等等的识别。第二,建议加强大模型的逻辑推理能力训练,通过算法的优化提升逻辑的严谨性、连贯性,改善跳步、表述不严谨的问题。第三,建议优化解题方法,能够运用概念应用、数学结合等方法,来对学生进行指导。实际教学中,无论是代数还是几何,都要依靠数形结合的方法让学生快速理解、简洁解题。建议大模型提升画图技能和应用能力,包括几何图形、函数图形、统计图形等。
丁明怡特别强调,还有特别重要的一点,要提高大模型的思维能力。“在创新性题型和情景创设性题型上,大模型大多数不太擅长。这类题一般会基于比较复杂的现实情境,表述形式也比较综合,可能会有文字、表格、图像等,而且需要解决真实的问题,比如提出最优策略或者建议等。这种题目是没有答题模板的,考查学生的阅读能力和问题解决能力。实际上这对大模型也提出了更高的要求,需要真正读懂这道题说的是什么,然后再把它转化成数学问题,再运用数学知识进行解答,随后再回到现实问题中提出解决方案。这方面大模型还有比较大的提升空间。”丁明怡解释道。
另外丁明怡提到,如果大模型应用到数学教育场景中,对于学生的启发引导还需优化。
“比如,拿到一道题,希望能够先讲一下题目所涉及的知识点和知识结构,再去讲这道题求解的方法,假如说基于定义性质来求解,可以一边画图,一边结合知识结构进行分步讲解,得出答案后,还可以再进行解法比较,提出更优的方法等。既有前期知识框架的分析,又有后期一步步的启发以及和前期框架之间的联系。”在丁明怡看来,这才是大模型应用于教育场景中的价值体现。
新京报记者冯琪
编辑缪晨霞巫慧校对付春愔