
专访清华胡杨:开发晶圆级芯片,降低先进工艺依赖,通过系统重构大幅提升算力
信息技术快速发展,全球对算力的需求与日俱增。从AI到大数据分析,再到物联网、自动驾驶,几乎各个领域的进步都离不开强大的算力支持。
然而,当前传统芯片制造工艺逐渐接近物理极限,严重制约了算力的提升空间。面对这一挑战,开发晶圆级芯片成为了一个备受关注的解决方案。
晶圆级芯片通过构建整片晶圆规模的大规模集成电路,打破了传统芯片设计中由光刻口径施加的面积墙限制,对比等效的算力集群,能够显著提高系统集成度,减少互连延迟和功耗。
“未经切割的晶圆上电路单元可以更紧密地排列,形成带宽更高、延时更短的互连结构,大幅加速数据传输。晶圆级芯片可以说是目前为止算力节点集成密度最高的一种形态。我们测算,其单机柜算力密度能够达到现有GPU方案的200倍以上。”清华大学集成电路学院胡杨教授告诉「问芯」。

胡杨于2017年在美国佛罗里达大学电子与计算机工程系获博士学位,之前分别在天津大学和清华大学获得本科和硕士学位。博士毕业后他加入德克萨斯大学达拉斯分校担任电子与计算机工程系助理教授,获得NSFCAREERAWARD。现在他是清华大学集成电路学院副教授、博士生导师,担任科技创新2030“新一代人工智能”重大项目负责人。
截至目前,他已发表学术论文90余篇,其中在ISSCC、JSSC、ISCA、HPCA、MICRO、ASPLOS发表一作及通讯作者论文20余篇,现阶段的研究方向主要围绕晶圆级AI芯片体系架构、集成架构、编译工具链以及集群系统等。
“晶圆级芯片拥有更高单位体积晶体管密度与算力”
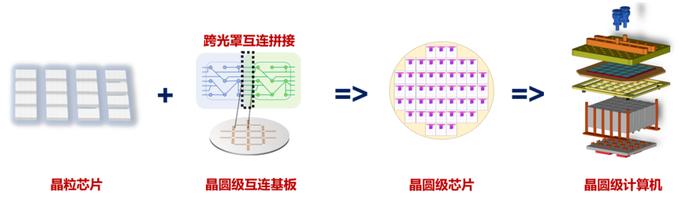
常规芯片生产流程中,一个晶圆在光刻后被切割成许多小裸片(Die)并单独进行封装,每片裸片都单独封装为一颗完整的芯片。
而晶圆级芯片,顾名思义,通过制造一块不进行切割的晶圆级互连基板,再将设计好的常规裸片在晶圆基板上进行集成与封装,从而获得一整块巨大的芯片。对比传统芯片构成的计算集群,晶圆级计算系统通过先进集成技术获得了芯片级的互连能力。
“晶圆级芯片本质上也是采用Chiplet方法进行设计,相当于把传统Chiplet的中介层基板放大到了晶圆尺寸,然后在晶圆上集成计算与存储Die等,这就形成了一个晶圆级芯片。”胡杨介绍说,“但是尺寸的变化会带来一系列计算范式、系统形态、设计方法学角度的变革,从而使晶圆级芯片不仅仅是一个简单的Chiplet产品。”他指出。
谈及开发晶圆级芯片的初衷,他表示,“想要提升集群算力以及集群线性度,需要提升单个节点的算力,但从传统路线上来看,提升单个节点算力只能依靠先进工艺。如何绕开先进工艺来提升算力?以晶圆级芯片为代表的系统级重构就是一种解决方案。”
“国内在先进封装领域的布局相对较早,能用来进行晶圆级集成的封装技术储备也较为充裕。在研发前期我们与产业链进行了很多接触,发现基础的‘单点技术’都有较好的储备,只需要把这些单点技术串联起来,进行打通适配,那就可以基于国内的产业链基础进行晶圆级集成。”胡杨说道,“借助晶圆级芯片有望解决当前面临的算力瓶颈,尤其是在先进工艺遭遇封锁的背景下,能够提供一个算力持续有效提升的途径。此外由于晶圆级芯片的晶粒芯片完全基于成熟的数字计算范式,对比其他新型计算形态,在软件编程、应用生态上具有天生优势,有望尽早投入大规模部署与应用。这是我们投身这个领域的初衷。”他补充说。
对比传统芯片及其组成的算力集群,晶圆级芯片能够在单位空间内集成更多单元电路,具有更高的晶体管密度与算力。同时,未经切割的晶圆上的电路单元与金属互连排列更紧密,从而形成带宽更高、延时更短的互连结构,相当于通过高性能互连与高密度集成构建了更大的算力节点,在构建算力集群时,能够有效提升集群的运作效率。相同算力下,由晶圆级芯片构建的算力集群占地面积对比GPU集群能够缩小10-20倍以上,功耗可降低30%以上。
在相同工艺情况下,一般来说,芯片的面积越大、晶体管密度越高,其发热就越严重。针对这种尺寸巨大、晶体管密度极高的晶圆级芯片的散热问题,胡杨表示,“其整体发热量要看集成的计算Die的数量及功耗。比如,在一个晶圆上集成有30颗计算Die,这种规模的发热量级采用常规液冷板散热方式即可应对。”
“现阶段的一种解决方案是,芯片上表面采用液冷板,下表面也基于液冷框架,采用异形结构使能之与发热单元更好的贴合。但若后期集成数量更多或是采用能耗更高的计算Die,那就需要借助其他散热方式,比如相变液冷技术等。”他说道。
目前,半导体芯片行业围绕散热的研究大部分都是面向“微观散热”,即在单颗芯片的尺度上解决散热问题。“然而,我们开发的大尺寸晶圆级芯片包括多个发热点,属于‘系统级散热’的范畴。”胡杨指出,“芯片上表面是核心发热区,芯片背部供电系统也会聚集大量的热,如何从系统角度把上、下表面的热量都散出去,这是需要攻克的难题,而这需要跨行业联合相关热设计领域的研究人员一起进行攻关。”他补充说。
除此之外,晶圆级芯片的制造也面临一系列挑战,比如良率问题,这会导致晶圆级芯片初期的成本较高。在胡杨看来,“这属于工程与产业化问题。对此,需要有长期投入构建起产业链条,将产品从0到1开发出来,接下来就需要想办法让产业链条上下游之间的工艺进行兼容,提升制造过程中各个环节的良率,最终构建起一套成熟的产业体系。如此一来,前期的NRE就分摊到后期的产品中,提升晶圆级芯片的商业可行性。此外,为了进一步提升晶圆级系统的可用性,系统容错问题也不可忽视。”
从本质上来看,晶圆级芯片其实已经超出了芯片本身的概念,属于一个复杂整机系统。“从芯片设计、基板设计、集成封装、高性能供电、高效散热、系统装配、服务器整机乃至定制化机架等各个环节都需要多方合作。以封装环节为例,这本身就是一个综合学科,涵盖工艺、材料、机械、物理等,需要相关学科的合作方一起探讨。”他表示。
胡杨坦言,“我现在每天的主要任务就是与产业界打交道,目前我们团队已经与清微智能、上海人工智能实验室、中芯国际、长电科技、长鑫存储、中国电子科技集团公司第五十八研究所等多家企业院所建立了紧密的合作伙伴关系。我自己的研究方向是体系架构领域,而晶圆级芯片开发是一个工程性很强的项目,需要对各个领域都有所了解,然后将这些领域有机结合起来。”
“晶圆级芯片是算力节点集成密度最高的形态”
据介绍,全球已有两家公司开发出了晶圆级芯片产品。其中一家是Cerebras,从2019年至今该公司已经推出第三代晶圆级芯片。“Cerebras公司的技术路线是通过修改芯片光刻流程实现的。晶圆光刻过程中在计算Die之间加入连接线,让Die与Die互连进而形成整个晶圆级芯片。”胡杨表示,“另外一家是特斯拉,其开发晶圆级芯片(Dojo)的技术路线与Cerebras不同,采用了Chiplet路线在晶圆尺寸的基板上集成了25颗专有的D1芯片。”
“很大程度上,英伟达其实也在一步步走向这个趋势。比如英伟达的B200,也是采用Chiplet方式把两颗Die合封在一起成为一颗大芯片。不难看出,英伟达也认为应该借助更高密度的算力来提升算力集群的效率。”他说道。
他进一步解释说,“常规形态下,集群算力节点越多,则集群规模越大,花费在通信上的开销就越大,集群的效率就越低。因此,英伟达NVL72通过提升集群内的节点集成密度(即提高算力密度),在一个机架中集成了远超常规机架的GPU数量,使得集群的尺寸规模得到控制,效率才能实现进一步提升。”
“这种计算形态是英伟达权衡了良率和成本之后的一种解决方案。若按照英伟达的这种计算形态,想要继续提升算力密度,最终就会发展成为晶圆级芯片的形态,这也是目前为止算力节点集成密度最高的一种形态。”他表示。
胡杨认为,“相较于当前‘千卡万卡’级别的算力集群,晶圆级芯片的这种计算形态能够大幅提升通信效率,有希望成为具备最高效率的算力集群。同时,算力集群中采用晶圆级芯片对于大模型训练和推理均能带来效率提升。”以推理为例,有些场景需要进行分离部署,对通信性能要求较高,而晶圆级芯片能在这种场景中带来更好的通信保障。

谈及晶圆级芯片的未来发展趋势,胡杨表示,“就目前而言,晶圆级芯片主要沿用二维集成的技术路线,所有Die在晶圆上都是平铺的,由于晶圆的面积固定,在固定面积上计算Die多,那存储Die就会少,反之亦然。因此,未来将会过渡到三维集成的方式,比如在计算Die上堆叠DRAM,然后再进行晶圆级集成。”
在三维集成的形态下,晶圆级芯片拥有充裕的存储容量和带宽,计算密度和存储密度两者可以兼得,进而更好地发挥晶圆级芯片高带宽的优势。
“另外一方面,也是由于晶圆级芯片的二维集成方式,运行一些比较复杂的通信算法,现有的通信网络难以满足,要解决这个问题,我认为还需要构建更高效的晶圆级互连拓扑,例如在晶圆上进行光波导集成。”他表示。
聊到AI和算力芯片的发展,胡杨提到了硬件彩票(HardwareLottery,用来描述算法研发更多地依赖于其与可用软硬件的兼容性,受到现有硬件能力的高度制约)的概念。“很大程度上,目前算法设计天然受到硬件性能的约束。如果我们不去突破硬件在某一方面的极限,那就没办法去帮助孵化更有想象力的算法。”他指出。比如,基于当前带宽的极限,研究人员很难设计出一款能够发挥更高带宽、更高互连程度的算法。
“业内整体而言,从事算法软件的开发者要远远多于硬件开发者,而且相对缺乏软硬件协同优化的经验。一些软件开发在硬件性能不足的时候必然会受到硬件性能的制约。因此硬件开发从业者有一个天然驱动力,即要开发更高性能的硬件。”他说道,“开发晶圆级芯片,相当于直接把硬件性能拉到最高,尽量降低硬件约束,让软件开发者不会为硬件性能所累,有望开发超越当前Transformer的新算法。”

产业化层面,胡杨表示,“从2022年起,我们团队在尹首一老师的带领下开始专注于晶圆级芯片研发,短期的目标是希望在明年开发出一款晶圆级芯片样机;到2026年,我们希望能推出具有大算力的晶圆级芯片样机;到2027年,我们期望基于多个大算力晶圆级芯片样机组成计算集群,能在上面真正跑一些大模型训练,以及AIforScience等应用,使其与更多实际应用的场景进行结合。除了大模型之外,其他诸如超算等很多领域也迫切需要大算力底座,我们长期目标是解决国内算力瓶颈的挑战。”他总结道。
参考资料:
1.https://www.sic.tsinghua.edu.cn/info/1014/1816.htm
2.https://dblp.org/pid/43/4685-1.html