
图数据库和知识图谱在好分期风控系统中的探索和应用
近年来随着监管力度的不断提升,金融机构业务的不断发展,交易方式越发便利的背景下。客户、账务、资金等关系也越发复杂,黑产也更加隐蔽,对内部风控要求也在不断加强。传统的关系型数据库在这种复杂的关系网络上发挥的效果越发有限,在多维度的查询上很难在合理的时间内返回结果。图数据库作为复杂关系网络分析的一个强有力的工具,如何高效的发挥其在高性能、高扩展、高稳定性方面的能力,显得至关重要。
一、当前图数据库和知识图谱
的现状和存在的问题
图数据更接近于自然社会中的关系,很好的解决了复杂关系网络的查询性能问题,其更能快速的发现隐藏关系,弥补了分析手段上的缺失。
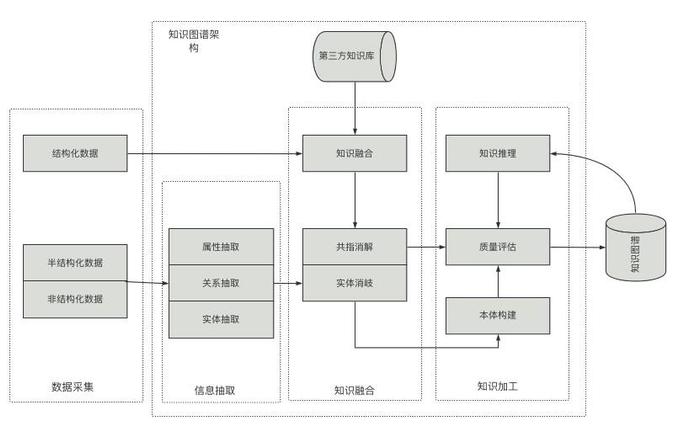
风控领域内使用现状
作为知识图谱存储和展示的核心,图数据库商业化和开源社区都有很多选择。如:阿里云的GDB、腾讯的KonisGraph、NebulaGraph、Neo4j、JanusGraph等;借助于图数据库为领域知识的积累、业务降本提效、风险预测等提供有力支持。知识图谱作为图数据库广泛和基础的应用,在目前业内风控领域的贷前、贷中、贷后等方面都发挥着极其重要的作用。具体而言:
1、贷前:
欺诈团伙挖掘:基于专家经验的团伙挖掘、自动规则挖掘。
风险事件预警:基于新客户对风控场景影响,触发风险事件达到预警效果。
2、贷中:
交易转账:实时跟踪资金流向和交易信息在线预测。
风险跟踪:实时跟踪异常指标,扫描客户风险,实现风险早发现早阻断。
3、贷后:
洗钱欺诈分析:根据多度交易行为快速甄别可疑交易。
失联修复:为已经失联的客户提供中间人联系。
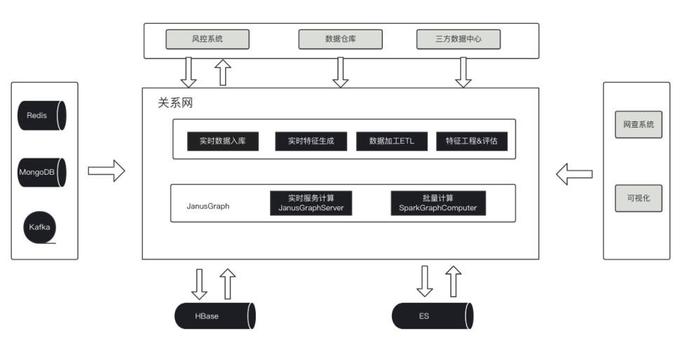
在微财使用现状
随着好分期金融产品业务的不断发展,信贷业务相关数据也在⽇益增多。这些数据原先也只作为⼀些外部信息存储,⽆法形成有效的知识,更谈不上构建知识图谱来为公司提供推理和预测。为此综合已有的信贷业务基础数据,历史交易数据及⾃有的和三⽅的⻛险数据等,使⽤图数据库构建成的关系⽹项⽬,通过实体与实体之间的关系,快速挖掘⽤户特征,涉⿊分析,并基于已有的⿊名单挖掘隐藏的团伙关系等,成为反欺诈中的关键⼯具。主要有以下应用场景:
1、为贷后提供失联信息修复:支持通话记录,附近地址,同IP设备号等维度联系人修复。
2、可视化及用户画像:提供子图展示,关键路径提示,用户画像展示功能。
3、图特征支持业务:根据图计算提供各种聚类特征,供模型和策略使用。
4、欺诈团伙挖掘:根据已有黑名单欺诈人员,基于多维度关联聚类算法,实现欺诈团伙的挖掘。
二、微财实践过程中遇到的一些问题
前期数据如何制备及入库,实现冷启动
对于图数据库的构建,离线基础数据的导入是前提,在Hive中我们存有4T左右的数据需要导入,如此大的数据量,制备成需要的格式数据导入比较困难,并且要满足性能上需要是难点。
解决方案:
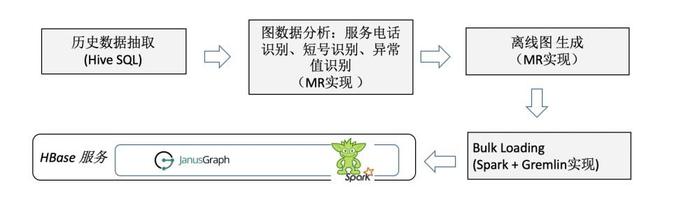
针对海量数据制备导入,JanusGraph提供了bulkloading方式导入,但是基于Hadoop支持三种导入数据的格式:GryoInputFormat/GraphSONInputFormat/ScriptInputFormat。我们选中的是GraphSON格式,这种数据格式与Json较为类似,方便理解转换,但是也有一定的区别。为此我们自定义了一种数据格式FlatGraphSON,使得从Hivetable中抽取数据后,便于MapReduce任务读取数据,制备成GraphSON格式数据。
FlatGraphSON是一种介于GraphSON和Hivetable之间的数据格式,是Hive加工各类数据的结果格式,又是用于生成GraphSON格式图数据的数据格式。
具体定义如下:
边的格式为:'EDGE'#from_vertex_value#to_vertex_value#[property_name:property_value]
顶点的格式为:'VERTEX'#vertex_value[#property_name:property_value[:meta_property_name:meta_property_value]]
Hive生成数据后,通过MapReduce任务读取对应HDFS文件处理生成的GraphSON格式数据,最后使用bulkloading方式导入。其中有一个问题是官方bulkloading当时还不能提交到SparkYarn上,需要改造源码以提高性能。
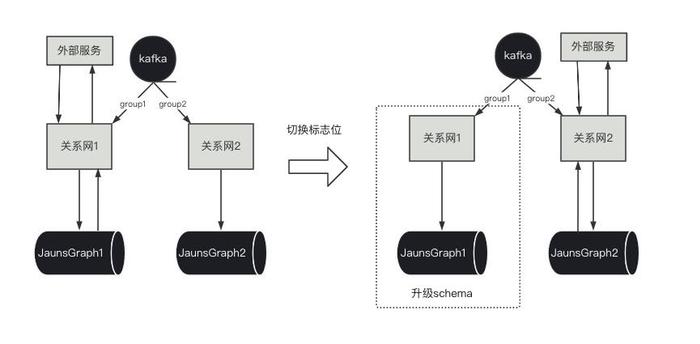
落地部署怎么做到平滑切换
风控系统处于整体业务中的核心环节,对于稳定性以及服务持续可用性要求很高
线上服务不能暂停,服务请求不能丢失;
必须使用完整的图数据提供风险计算结果(生成风险特征等);
当遇到例如新增数据源、修改图数据库schema或是上线新图,需要对系统进行升级重启操作时,如何能保证服务的持续可用性呢?
解决方案:
1、建立两个完全一致的图,可以在通过HBase的clone_snapshot复制表方式快速实现,部署两套相同的服务分别读取两个库。两套系统可以通过不同的consumer-group消费消息
2、在数据库中设置标志位例如0和1,每次只有一个系统对外服务,另外一个系统作为备份库
3、当需要升级图时,通过标志位控制,比如现在1处于备份状态,0处于上线状态,我们可以先对1系统进行升级。升级结束后再将标志位换成0,让升级好的系统对外服务,然后再对0系统进行升级。
超级节点处理
图数据库中不可避免的问题就是supervertex,其带来问题:
顶点的度数服从幂律分布,(比如通讯录中的名人,或者百度地址等)一般图中都存在supervertex
MapReduce框架下数据清洗时,单个key对应极多value会导致reducerOOM
HBase(JanusGraph存储端)column有极多会导致性能急剧下降
图遍历时节点过多会导致查询爆炸
解决方案:
1、对于确定没有任何实际意义的实体(比如设备号:00000000-0000-0000-0000-000000000000,00000000)直接过滤掉
2、不能过滤掉,边等价转换为顶点属性集合(成为属性边),使用时即可直接使用属性进行过滤,将原先50多亿条边缩减为10多亿条
3、另外对应geo范围查询节点过多导致性能急速下降问题,可以采用limit方式配合实际业务进行截断,以达到性能要求
图数据可视化展示
如何直观的看到实体间的联系,方便策略和模型同学观察发掘特征,可视化是关键。Cytosacpe.js是桌面版Cytosacpe对应的JavaScript版本,对于桌面版我们在过去以及最近的分析中已经用到,对于JavaScript版本在先前的项目中也用其做过demo,从使用体验来看还是比较方便的,做出的图也比较酷炫。可以比较完美的展示关系网的联系,并做一些定制化。
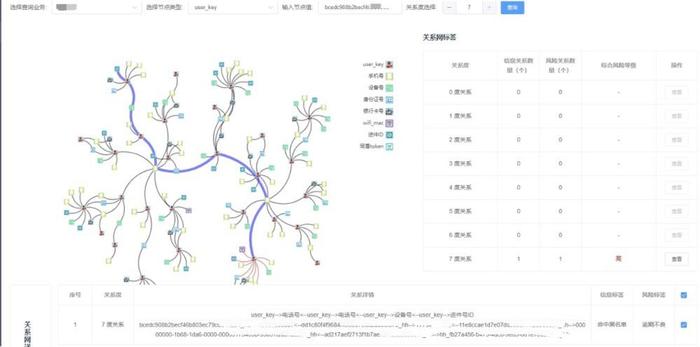
成果:某条包含黑名单用户的路径
三、上线后的效果
图特征支持业务
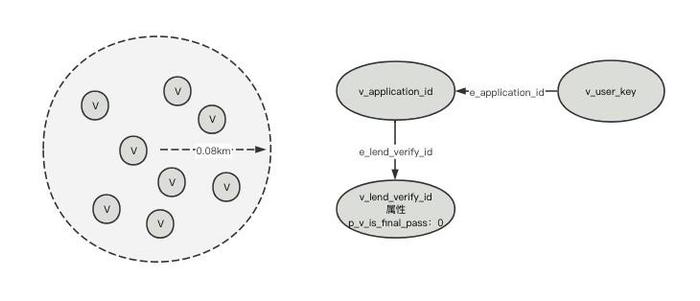
案例一:GPS80米范围内放款审核失败用户数
之前对于这种场景,我们需要先去获取数据库中用户下单时最近一次采集到的GPS信息,通过GPS经纬度信息获取到范围内对应的用户(这一步需要配合Mysql的空间索引或者依赖RedisGeoHash来实现),再通过用户去进件表中查找其对应的进件,筛选出失败的进件用户。解决方案:需要用到JanusGraph中的Geoshape类型,JanusGraph默认结合Elasticsearch作为混合索引存储引擎,其可以方便快捷的获取GPS半径内的Vertex,先通过用户对应GPS地址,查找范围内其余用户,继而再通过用户,筛选出放款审核失败的用户,统计其数量。
具体代码如下:
GraphTraversal
vertices=g.V()
.has(GraphConstants.P_V_GPS,geoWithin(
//lat,lng,radiusinkm
Geoshape.circle(
((Geoshape)point.get()).getPoint().getLatitude(),
((Geoshape)point.get()).getPoint().getLongitude(),
km
)))
.as("x").select("x")
.out(GraphConstants.E_APPLICATION_ID).out(GraphConstants.E_LEND_VERIFY_ID)
.has(GraphConstants.P_V_IS_FINAL_PASSED,0).count();
注意:当需要插入数据后立马进行查询需要加上配置index.[x].elasticsearch.bulk-refresh=true,否者可能会导致查询不到当前插入的点,导致数据丢失。([x]表示用户名称,也就是配置index.search.backend中的search)
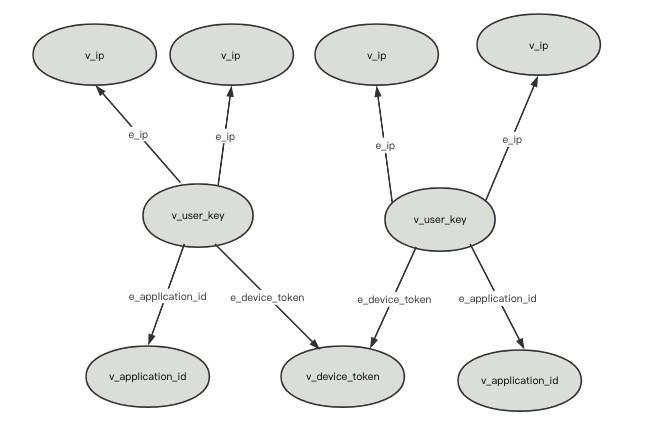
案例二:同一设备号近30天内有过申请授信的IP数
这场景下需要通过进件用户的设备号,相同设备号关联出最近30天内有过申请授信的用户,这些用户对应的IP数量。通过对IP数量的分析可以获知是否是团伙作案的可能。传统实现下我们需要通过设备表关联出用户,然后用户表关联授信表,再关联IP表才能获取到数据,这需要关联四张表,关联的数据量已经爆炸。解决方案:通过设备号查出入边的用户顶点,筛选出其中有过进件的用户顶点,再而统计用户顶点出边对应的IP顶点数。
具体代码如下:
g.V(userKey)
.out(GraphConstants.E_DEVICE_TOKEN)
.in(GraphConstants.E_DEVICE_TOKEN)
.as('x')
.out(GraphConstants.E_APPLICATION_ID)
.select('x')
.out(GraphConstants.E_IP).count();
欺诈团伙进行挖掘
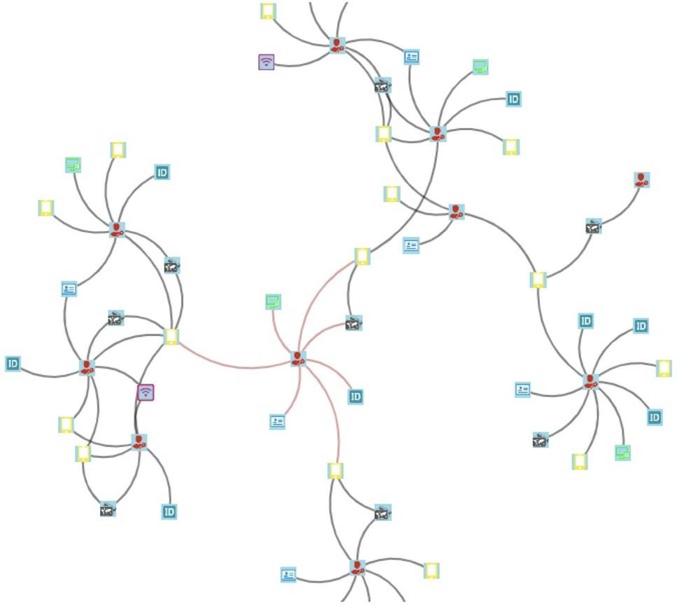
案例一:团伙发现
正所谓“近朱者赤近墨者黑”、“人以类聚,物以群分”,通过已有黑名单系统,在关系网络中的染黑计算,我们可以得知坏人推荐坏人来,好人推荐好人。根据用户wifi实体是否关联多个高风险用户、黑名单用户之间是否有公共联系人、黑名单客户之间的公共路径和节点等,我们可以快速的定位到欺诈团体,对其进行快速封杀。
由此可见在图数据库中业务实现逻辑清晰,无需额外维护Elasticsearch中的索引数据,对于多维度的关联关系可以很自然的关联起来,减少关联的复杂度,无需耗时耗内存的join操作,相对应查询性能上也可以有很大的提升。目前图数据库中存放了近20亿条边和1.8亿个顶点,为线上提供1800+特征计算支持;挖掘出26w个短号和15w个公共服务电话;拦截发现欺诈团伙一千多次。
四、未来规划
1、图实时计算服务和特征挖掘:完善目前的关系网,打通与数仓的屏障,搭建一站式平台实现图数据查询和分析,图模型管理对接功能。开发自动化特征挖掘以及风险预测功能,实现规则引擎自动化预警拦截。
2、构建图形推理功能:基于逻辑推理和概率推理两种方式,结合现有的推理算法,开发推理功能减少人审带来的误判、漏判行为,保证风控的精准度,为分析人员提供更多的参考。
非结构化数据NLP处理:包含自然语言的消歧分析以及针对目前公司所有数据进行分类,搭建数据清洗平台,使非结构化的数据能够被快速筛选、保存和利用起来。
Graph3.0架构探索:在高性能、高扩展、运算快、智能化等方面进一步突破。
风控和黑产的对抗一直都在,未来也将持续下去,只有不断的提升攻防水平,才能将各种风险降到最低。
(来源:新视线)