
研究人员用“成员推断攻击”检索大模型知识库,攻击精度达到80%
知识检索增强系统,是已被用于大模型的技术之一,能有效解决大模型存在的知识更新不及时和幻觉等问题。
知识检索增强的存在使得大模型无需通过模型训练来适应下游任务,而是能够通过一个外挂的知识库,检索与用户所提的问题最相关的文本,并将这些文本集成为大模型的输入,从而优化模型生成的内容。
想象一下,知识检索增强就像是给AI装上了一个超级图书馆。当我们向AI提问时,它不需要把所有知识都记在“大脑”里,而是在这个“图书馆”中快速查找最相关的信息,然后基于这些信息给出回答。
然而,知识检索增强虽然实用并且使用门槛较低,但也同样带来了风险。
已有研究表明,只需向知识检索增强的知识库中注入一些有害信息,就能诱导大模型产生不当的回答。可见知识检索增强系统本身并不安全。
更令人担忧的是:知识检索增强系统的知识库本身安全吗?知识库中的信息通常是私有的,会不会存在被泄露的风险?
想象一下,在医疗领域,知识检索增强系统的知识库里可能包含大量的医疗问答数据。一旦这些信息被泄露,病人的隐私就会受到严重威胁。
因此,知识检索增强的数据安全尤为重要,但在此前只有来自于IBM研究实验室和南洋理工大学的研究人员关注这个问题。
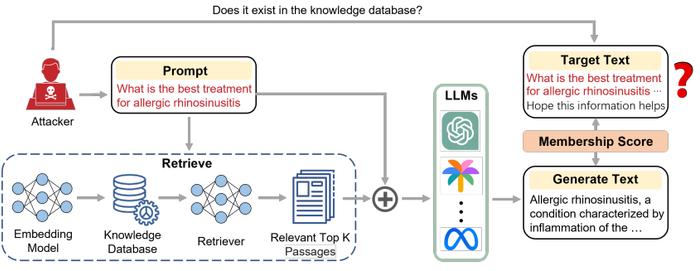
为了验证这些问题,近期有研究人员设计了一种新的算法,旨在通过成员推断攻击(MIA,MembershipInferenceAttack)来判断知识检索增强系统的知识库中所存储的信息。
成员推断攻击,是用来测试模型隐私性的一种通用技术。它的工作原理可以理解为是在玩一个猜谜游戏:通过观察模型的损失值、置信度、困惑度等信息,来推测它是否“见过”某个样本。
但是,传统的成员推断攻击主要针对那些参数化的AI模型,并不适用于知识检索增强这样非参数化系统。
而该团队提出的新算法仅通过一个黑盒的应用程序编程接口(API,ApplicationProgrammingInterface),无需介入模型训练过程,也无需知道模型内部信息。仅通过模型输出就能有效判断某个信息是否存在于知识检索增强的知识库中。
具体来说,课题组将用户的输入文本划分为两部分。前半部分作为prompt,使得知识检索增强系统能检索与prompt最相关的信息并生成输出文本。
假如输入文本存在于知识库中,模型生成的内容会与输入文本非常相似,且生成文本的困惑度更低。
因此,他们通过输入文本和输出文本的相似度以及模型生成的困惑度作为评判标准,来判断输入文本是否存在于知识库中。
实验结果显示,本次方法能够达到80%以上的攻击精度,证明知识检索增强系统的知识库的确存在隐私泄露的风险。
图|相关论文(来源:arXiv)
湖北大学人工智能学院杨洋副教授与国家级人才计划专家程力教授课题组硕士生李钰颖是论文第一作者,本论文在刘高扬博士和杨洋副教授的指导下完成。

在应用前景上:
其一,本次研究证明知识检索增强系统知识库存在隐私泄露的风险,这有望推动科技公司重新审视他们的知识检索增强系统,以便更加地重视用户隐私。
因此,这可能会催生出一系列新的安全协议和行业标准,让AI变得更加可信。
其二,本次研究有望提供一种数据确权的新方法。在数字时代,数据就是新的石油。但是,如何证明数据的所属权?
现有研究只能对模型的预训练数据进行确权,但本次成果有望对知识检索增强知识库中的数据进行确权。
在未来,这可能会成为数据版权保护的新方法,让数据所有者能更好地维护自己的权益。
其三,随着《数据安全法》的实施和相关法律法规的出台,本次成果可能成为一个重要的取证手段,在数字世界的法律纠纷中发挥关键作用。
例如,在未来的知识产权纠纷中,本次成果可能会被用来证明某个模型是否使用了受保护的数据。
其四,随着人们对隐私保护的意识日益增强,本次成果可能会衍生出一些个人使用的数据管理工具。
想象一下,未来人们可以用一个APP来检测个人信息是否被不当用于AI系统,以增强个人对隐私数据的控制力。
其五,本次成果也可能被用来对AI系统进行“健康检查”。公司和机构可以定期使用这种技术对知识检索增强系统进行审核,确保没有意外泄露用户信息或存储不当数据。
目前,课题组已经设计出一套攻击方案,并证明了该方案的可行性。但是,这一系列研究不会止步于此。
目前的工作已经揭示了基于大模型及其各种应用系统存在的数据安全隐患,但关于这些隐患的成因,目前尚无公认的结果。
眼下该团队正在加紧研究大模型内部的机制,尤其是在模型的记忆和正向推理过程中,重点分析信息流动和处理的关键环节,深入研究可能导致隐私泄露的薄弱环节。
同时,课题组正在探究模型信息回溯和信息整合的内在机理,为从根本上解决大模型数据隐私安全问题提供扎实的理论和实践基础。
研究人员表示:“本工作由湖北大学人工智能学院、智能感知系统与安全教育部重点实验室以及华中科技大学电子信息与通信学院、智能互联网技术湖北省重点实验室联合发布,该成果将先推广至国家电网等信息安全敏感单位,目前正在洽谈中。”
参考资料:
1.https://arxiv.org/pdf/2406.19234
运营/排版:何晨龙