
Nature论文成果:研究人员发现AI模型越大,可靠性下降越多
在过去几年,大模型面临着不可靠性演变的局限性和挑战。随着这些模型的扩展(使用更多的计算资源)以及后期塑造(使用人类反馈),大模型与人类用户在交互中的可靠性却没有受到全面分析。
其中一个原因是学术界一直没有重视在评测中利用任务难度去提高对通用人工智能系统评估的稳健性与全面性。

瓦伦西亚理工大学本科毕业生周乐鑫是第一作者,何塞-埃尔南德斯-奥拉罗(JoseHernandez-Orallo)教授担任通讯作者。
图|相关论文(来源:Nature)
该研究或是世界上首次对通用人工智能系统的稳健评估,归功于其在0-100的连续范围内纳入了对人类对任务难度的预期考量。
在这次研究中,该团队从三个维度探讨了大模型的可靠性和演变,其一是人类对任务难度的预期与大模型性能之间的不一致性现象。
他们的分析发现,虽然更大且更遵循指令的大模型在人类认为超高难度的许多任务中表现不错,但是它们在许多同一领域超低难度的任务中仍然会失败,而人类则不认为它们应当失败。
因此,目前大模型没有一个“安全区”可以让人类确信大模型可以完美地运行,哪怕只是针对非常低难度的任务区域。
实际上,较新的大模型只在高难度任务上有明显进步,这加剧了人类难度预期与大模型性能之间的不一致,导致人类更难通过任务困难度去预判模型的错误输出。
这一点对于需要级高可靠性的应用场景非常重要,因为其在使用大模型期间需要识别具有近乎为零错误率的“安全操作区域”。
这与人们的预期相悖,即随着模型变得越来越大,其遵循指令的可靠性应当越来越强。
人们会理所当然地认为,新模型在完成简单任务时的表现会更加可靠,从而用户可以利用任务困难度去更好的预测的大模型的错误分布。
接着,该团队针对大模型的“任务回避行为”分析了大模型不可靠性的第二个维度。该课题组介绍了大模型如何通过回复“我不知道”,或偏离原问题来避免回答问题。
研究结果表明,早期的模型倾向于回避问题,从而暴露了大模型的局限性。
但是,新的模型相对于较早期的大模型(如GPT-4与GPT-3),错误率大幅上升,因为现在的模型很少规避回答超出其能力范围的任务或问题。
在某些基准测试中,研究人员甚至发现错误率的上升比正确率的提高更快。
这种从“回避”到“自信地给出错误回复”的转变,增加了用户误判的风险,从而可能导致用户一开始过度依赖大模型来完成其并不擅长的任务,不过从长远来看,他们可能会失望。
除了这一结果之外,该团队还评估了大模型是否会像人类一样,随着任务难度的增加而更频繁地回避任务。不过测试情况并非如此:任务难度与回避任务之间的相关性基本为0。
这种异于人类的自大行为模式,以及先前提到的模型错误不可预测性,导致了人类必须仔细审查模型的输出,以便发现并纠正错误。
但正如课题组在另一项人类研究“人类监督和监督限制”中所展示的那样,人类并不擅长这种工作。
该研究分析了大模型可靠性的第三个维度——“模型性能对同一问题的微小表述变化的敏感度”。
目前对于如何提高模型对同一问题的不同提示语的鲁棒性,人们对此知之甚少。研究人员观察到,提示语的稳定性随着扩展和成型而提高。
然而,这种改进似乎在逐渐减少,而且提示词灵敏度仍然会导致最新模型出现不可靠的问题,暗示着当前的科技范式很难使用户在未来摆脱指令敏感度这个问题。
更令人吃惊的是,研究团队发现,一些平均表现最好的提示词格式实际上会因任务难度的不同而表现得更差。
例如,用户可能误以为某些提示词效果出色,因为它们在处理复杂任务中表现良好,但其应对在简单任务时却表现不佳。
这一趋势令人担忧,因为这些结果表明,人类很难预测模型何时会犯错,以判断整个交互过程的可靠性。
这可能会引发额外的成本,以及无法满足对高可靠性有严格要求的用户需求。
该课题组还发现,在实验完成后发布的其他新模型也在这三个维度当中存在类似的不可靠性问题,包括:OpenAIo1preview、o1mini、LLaMA3.1405BInstruct和Claude3.5Sonnet[2]。
在分析完了三个模型不可靠性的维度之后,可以得出目前大模型和其演变的趋势并不乐观的结论。
因此,研究人员很想根据观察结果,来了解人类监督是否可作为缓解不可靠问题的解决方案。但是,在一项广泛的人类研究中,他们发现情况其实有所不同。
实际上,人类不善于发现模型的错误,而且令人惊讶的是,人们经常将不正确的模型输出误判为正确。
这表明人类没有足够的能力成为这些模型的可靠监督者,从而使大模型在高风险领域的应用变得更加复杂。
为此,该研究论文引入了一个新的评估框架,可以根据人类对任务难度的预期来更全面且稳健地评估大模型的能力和风险。
虽然上面的这部分内容在该论文中没有太多的讨论,但实际上在人工智能评估领域做出了重大贡献。
这是因为评估人工智能系统的标准方法一直在使用侧重于总分(如准确率)的基准。
然而,由于这些基准通常拥有模糊且随机的任务难度分布,它们无法稳健或全面地描述人工智能系统的能力和局限性,也无法提供更多关于被评估模型在未来新任务中将如何表现的见解。
后者至关重要,因为它是人工智能评估的首要目标之一。毕竟,人们想知道并预测何时何地可以安全地部署这些模型。
研究人员的方法通过描述大模型之于人类难度的能力,避开基准测试中信息量小且对任务难度分布极为敏感的总分指标(例如正确率),从而对人工智能进行更稳健的评估。
例如,当所包含的任务实例太容易或太困难时,人工智能可以在衡量数学推理能力的基准测试中分别获得100%或0%的分数。
这项工作始于他们在GPT-4红队的工作期间。研究团队的目标是根据任务难度,对GPT-4及其前身的性能和不稳定性如何演变进行稳健地评估,分析GPT系列过去三年的发展趋势。
为了确保该团队的结果也适用于其他语言模型系列,研究人员还将LLaMA和BLOOM模型系列也纳入了分析范围。
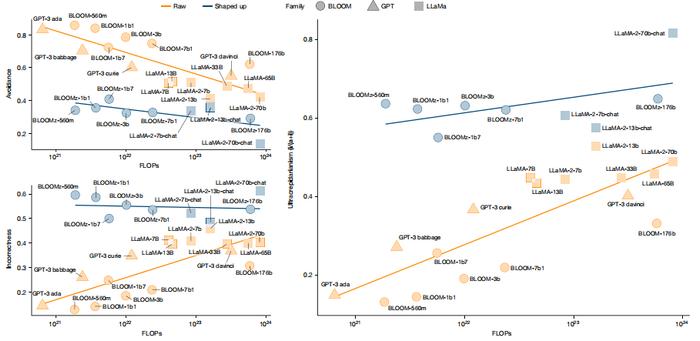
随着模型越来越大、可指导性越来越强,研究团队对了解人类对任务难度的预期与大模型性能之间的差异的演变过程产生了兴趣。
尽管OpenAI 前联合创始人兼首席科学家伊尔亚·苏茨克维(IlyaSutskever)曾预测这种差异会随着时间的推移而减少,但该团队发现事实并非如此。
正如之前他们在“新的评估框架”中提到的,加入对人类难度的考量比只关注挑战性越来越高的任务(如基准测试所做的)更稳健、更全面,从而为了解模型的能力和风险提供新的视角。
尽管这项研究并没有直接解决大模型的可靠性问题,但是通过揭示现有的“扩大模型规模和提高模型的可指导性”的方法并未能有效解决大模型可靠性和安全性的根本问题,来重新审视这个问题。
它挑战了之前的假设,即更强大的模型自然会导致更可预测和更可靠的行为。
这表明,他们需要从根本上改变大模型的设计和评估方式,特别是对于需要高可靠性和安全性的应用。
论文具体也分析了导致模型不可靠性的若干潜在原因以及可能的解决方法:
在扩大模型方面,近年来的基准测试逐渐趋向于包含更多难度较高的示例,或者赋予所谓“权威”来源更大的权重,这使得研究人员更注重优化模型在复杂任务上的表现,从而在整体难度一致性上逐步恶化。
而在提高模型可指导性方面,有证据证明在后期塑造的方法(如强化学习与人类反馈,RLHF)中,受雇人员倾向于对回避任务的回答给予惩罚,使得模型在面对难以解决的难题时更倾向于“编造”答案。
针对如何解决这些不可靠性,论文提出了一些可能的策略,比如可以借助人类对任务难度的预期来更有效地训练或微调模型,或者利用任务难度和模型的自信度,引导模型在遇到超出自身能力范围的问题时更加谨慎地应对。
参考资料:
1.Zhou,L.,Schellaert,W.,Martínez-Plumed,F.etal.Largerandmoreinstructablelanguagemodelsbecomelessreliable.Nature634,61–68(2024).https://doi.org/10.1038/s41586-024-07930-y
2.https://x.com/lexin_zhou/status/1838961179936293098.
运营/排版:何晨龙