
字节三面:attention中的Q,K,V怎么来的?
作者:TRiddle@知乎 仅用作学术分享
链接:https://www.zhihu.com/question/325839123/answer/3309301644
本质上就是查询+聚合。而且非常符合直觉,不需要任何公式就能说明这点。我们可以试着“重新发明”一下注意力机制。
现在想象一下,假如你想做一道名菜——佛跳墙,你会怎么做?你会先去菜市场里找到鲍鱼、海参、花胶、瑶柱,然后带回家将它们煮在一起对吧。
而一个用于文本分类的BERT做的事也一样,也是找到一些东西然后将它们煮在一起。
比方说如果想要识别一篇文章中是否在讲佛跳墙,要做的就是查找文章中是否存在相邻的“佛、跳、墙”(当然,“佛、跳、墙”的上下文也很重要,请允许我做些简化),然后将这三个存在性信息聚合在一起,最后从[cls]token的位置输出出去。
或者说,用[cls]来查询和聚合“佛、跳、墙”。
1.如何查询
首先面临的问题就是[cls]怎么查询“佛、跳、墙”。
其实有一种办法很简单,就是给文章中所有token都分别分配一个向量,让它们满足[cls]的向量同“佛、跳、墙”的三个向量的距离都很小,同除了它们三个之外的其它token的向量的距离都很大。
大家通常会用两个向量的点积来衡量它们之间的距离。具体就是点积大的距离小,点积小的距离大。
正因为距离是可衡量的,我们只需要计算[cls]的向量和句子中所有token的向量之间的点积,就能知道哪些token是“佛、跳、墙”,哪些token不是。
具体就是点积大的那些是,点积小的那些不是。这些点积再通过softmax归一化一下,就是我们常说的注意力分数。
我们可以说,注意力分数表示的是查询的相关性。或者说,表示的是“你有多大概率是我要查的东西”。
怎么给所有token分配向量呢?
先规定一下向量的名字,因为[cls]是查询的主体,所以我们给它分配的向量叫做Q(query的缩写)。
因为“佛、跳、墙”是被查询的客体,所以我们给它分配的向量叫做A(answer的缩写。等等,为什么不是K和V?这里先按下不表)。
向量的数值怎么分配呢?
我们弄两个可学习的矩阵WQ和WA,想办法让一个tokenembedding(加上positionembedding)乘上WQ得到Q,乘上WA得到A。WQ和WA的参数让它们自己通过梯度下降学习就行了。
WQ和WA实际上是模型学会的分配Q和A的逻辑。在我们的例子中的分配逻辑就是,[cls]的Q向量要同“佛、跳、墙”的A向量离得近一些,要同其他token的A向量离得远一些。
2.如何聚合
接下来需要解决的问题是怎么将“佛、跳、墙”的存在性信息聚合在一起。一种方法是,直接将“佛、跳、墙”的A向量加起来就行了。
按照前面提到的方法,首先我们计算[cls]的Q向量和所有token的A向量之间的距离,然后筛选出距离小的那些,最后把它们的A向量加起来。
不过,筛选这个操作太麻烦了。我们明明可以以注意力分数为权重,直接计算序列中所有token的A向量的加权和。
实际上这和先筛选再加起来是一样的。由于除“佛跳墙”外其他token的注意力分数都很小,这么做相当于只将“佛、跳、墙”的A向量加起来了。
也就是说,以注意力分数为权重对文章中的所有token的A向量求加权和,就相当于把需要查询出来的重要token给聚合在一起了。
可是,A向量很忙的啊。既要对查询的结果负责,又要对聚合的结果负责,我们能不能将它们一分为二呢?
当然可以了,我们用K向量(key的缩写)和V向量(value的缩写)替代A向量。
前者参与查询阶段的注意力分数计算,后者携带着聚合阶段需要被加在一起的存在性信息。当然,WA矩阵也要相应地替换成WK矩阵和WV矩阵。
让我们重新表述一下:以Q和K算出的注意力分数为权重对文章中的所有token的V向量求加权和,就相当于把需要查询的重要token的给聚合在一起了。
为了更形象地展示这个过程,我画了一张图:
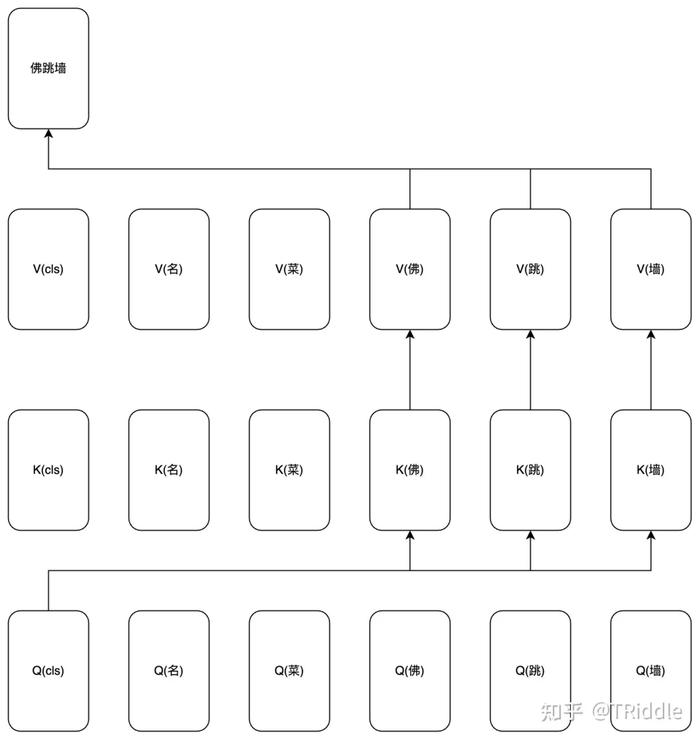
以上就是自注意力机制中Q、K、V的角色。我们用文本分类场景下的BERT举了个例子。
其它任务或者其它模型的注意力机制也非常好理解,因为本质上都是查询+聚合。

另外,你可能会关注下面这些问题:
(1)我关注到的attention中的Q、K、V是矩阵,这里的怎么是向量呢?
事实上文章中每个token都有自己的Q、K、V向量,因为每个token都有自己需要查询的东西,也可能被查询。把它们的Q、K、V向量连接起来就是 Q、K、V矩阵了。
(2)按照上面说的,注意力机制是不是不能保证“佛、跳、墙”是连续出现的?
其实是能的,只要让“佛”先查询“跳、墙”,再让[cls]查询“佛、跳、墙”就行了。
因为Q向量和K向量都是携带位置信息的,所以查询的时候是能感知到相对位置的。
所以在“佛”做查询的时候,就有机会只给它周围的“跳、墙”一个较高的注意力分数。
而做两次注意力机制也很容易,只要放在两个不同的attention层中就行了(不然transformer为啥那么多层)。
(3)一个token能不能有多个Q向量?
当然能。举个例子,“佛”可能不一定只用来查询“跳、墙”,还可能用来查询“祖”或者“经”等token。
的确,一个token可能是需要多个Q的,还可能需要多个K和V,这就是transformer中为什么有multi-headattention这种东西。
(4)Q和K用同一个向量行不行?
我的答案是——不行。假如Q和K用同一个向量,就会出现一些奇怪的相似性传导问题。
例如,“佛”和“跳、墙”的距离很近,“佛”和“祖”的距离也很近,那岂不是说“跳、墙”和“祖”的距离也很近了?或者从图的角度来解释就是:同质图和异质图建模的是不同的东西。
链接:https://www.zhihu.com/question/325839123/answer/3309301644