
一手实测豆包新发布的视觉理解大模型,他们真的卷起飞了。
人在字节火山发布会现场。
眼睁睁看着他们发了一大堆的模型升级,眼花缭乱,有一种要一股脑把字节系的AI底牌往桌上亮的感觉。
有语音的,有音乐的,有大语言模型的,有文生图的,有3D生成。

真的过于豪华了,字节真的是,家大业大。。。
但是看完了全场,我觉得最值得写一写,聊一聊的,还是这个:
豆包视觉理解模型。

效果不仅出奇的好,最关键的是,他们的价格。

价格直接低85%,直接把视觉理解模型拉入了“厘时代”。
字节,还是那个字节。
说实话,过去一两年,人人都在讲文字推理,讲大语言模型的爆点。
但是视觉理解,才一直是我们认知世界的第一道关卡。
当你来到这个世界睁开眼睛的第一刻,没有学会语言的时候,靠的就是你的眼睛。
我们先看到光影、颜色,才逐渐分辨出父母的面孔,屋子的空间,那时没有词汇、没有句子,只有模糊的光影与轮廓。
当我们对这个世界,通过视觉,一步步认识父母的脸,认识身边的玩具,认识窗外的树影,有了基本的认知后,然后才有了咿呀学语的过程。
它是我们触及世界的第一道门,不仅仅是看见了什么,更是用看去建立理解,进而触发思考与关联。
语言是有门槛的,你要先懂词语的意思。可视觉先于语言,是不需要翻译的输入。
有太多普通人,不知道如何描绘自己的需求,无法组织语言清楚的表达一件事,但是把图片扔给AI,问一下,这是任何人都会的。
上至80岁老人、下至10岁孩童,都可以。
所以,对于视觉理解模型,我才如此看重。
而这次新发布的豆包视觉理解模型,除了在火山开放了API,也已经在豆包上上线可以直接体验了。
我也第一时间,在发布会现场拉着我的朋友@赛博禅心和@Max,在会场厕所门口,从早上跑到中午,饭都没吃,跑了大概100个case,跟GPT4o对比做了个详细评测。

虽然感觉有点对不起他两,但是最后的结果,还是很让人有点惊喜的。
我们测的第一波例子,也是很多视觉大模型最痛苦的,就是数数。
我这有一个万恶之源的图,在好多论文里面都出现过,就是让大模型来数这张图里面有几只狗。

正常人类直接数中间的狗头,都非常清晰的能数清楚,一共是12只狗。
但是对于AI来说,那就炸了。数数这事,是最难的。
GPT4o非常自信的给了一个11只的答案。

Claude3.5也一个样,自信的爆出了11只的答案,Claude和GPT这两冤家,差点弄的我以为自己数错了。

直到把这张图发给豆包。
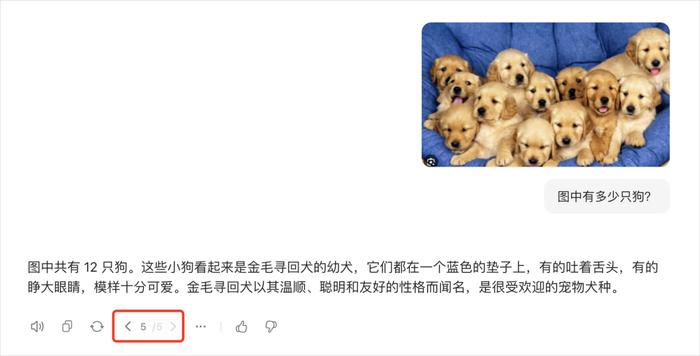
我还怕豆包是不是幻觉了,连续roll了5次,每次都是坚定不移的12只。
而且相比于GPT,还准确的识别了这是金毛巡回犬的幼犬,在答案的准确性和丰富度上,都比GPT4o要强。
于是,我又让它俩,做了另一件更难的事。
红框里有几个手办?分别是什么角色?

不仅需要精准的识别出数量,还要知道每个角色是啥,这个能答上来,那才是真的懂了。
结果GPT上来直接抽风,上来就是忽悠我4个。

然后那些角色也在那给我瞎掰,不是,哪有孙悟饭啊?哪有金发角色啊?你家孙悟饭蓝头发啊?
真的,槽点太多,我都不知道从哪吐槽起了。
再回头看豆包。

数量6个对了,4个《火影》系列的手办,从左到右其实是波风水门、漩涡鸣人、迪达拉、蝎,豆包对了前面两个水门和鸣人,再加漫威的一个雷神和绿巨人。
正确率66%,虽然没能完美识别,但也算是一个巨大的进步了。
这一波,说一句把GPT4o摁在地上打不过分吧。。。
测完数数后,我们又测了一波看图识景点。
直接掏出了黑悟空里面的十大景点,测了一波。
大部分GPT4o和豆包都差不太多,几乎打了个平手,像大足石刻、悬空寺、开元寺这种都识别出来了,而像小西天、水陆庵野都一起翻车了。
本来我觉得这两会在这个点上打个平手,结果,最后一题,GPT4o翻了车。

这个塔林,是山东济南灵岩寺塔林。自唐以降,墓塔成林。
早为钟,黄昏为鼓,白为方,才有了所谓“晨钟暮鼓白天方”。
而豆包,在这最后一题上,守住了自己的荣耀,回答了上来,从而险胜GPT4o一筹。

在一些世界常识中,GPT4o也落败了。
比如这根经典的滚珠丝杆,做了个视觉误导,问哪根最长。
豆包没啥问题,准确的回答了左边第二根最长。

但是GPT4o,却又翻车了,我roll了5次,每一次都信誓旦旦的告诉我,就是最左边最长,我都甚至怀疑是不是我自己的眼睛瞎了。。。

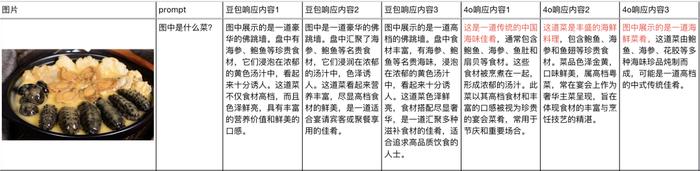
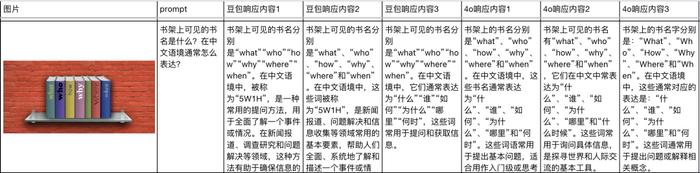
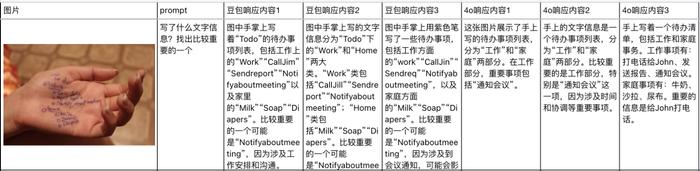
我们也做了一个非常详细的统计表格。把豆包和GPT4o的评测,每个跑三次放在了一起对比。
也能看出来,在大多数的任务上,豆包的这个视觉理解大模型都比GPT4o识别的更精准、更详细,对中国文化的一些内容,懂的也更多。
而且还有个很有趣的点,就是GPT4o因为那坑爹到家的安全限制,所以他没法看到任何人脸。
但是,豆包可以。
当然,也并不是说豆包在视觉理解上,它就强到爆炸了。
不行的点,当然也有。
比如我们发现,在一些数学公式的计算上,错误率还是会有一些的。
比如这道题。

答案其实是A。
但是扔给豆包的时候,会发现,回答还是会有一些错误。

在一些复杂的计算上,还是会有一些差距,毕竟做题,真的一直以来都是大模型的短板。
但整体来看,这波升级就是解决了很多基础的常识性问题,让大模型,有了更强的眼睛,也有了更好的脑子。
还是非常有用的。
文章的最后,我突然想说一个关于我朋友和他想要的AI的故事。
这哥们是一个大概40岁出头的中年人,压力很大,背着房贷,四脚吞金兽还在地上跑。人在一线城市,平时要上班养家糊口,又在业余时间搞了点自己的小买卖,想减轻一点家里的压力。
他以前和我说过,他最大的痛苦就是没有时间学更专业的技能,他那个网店是卖点数码的小玩意,但是吧自己又不会拍好看的商品图,不懂设计,也没有钱请专业摄影师和设计师。
我当时给他推荐了一些电商的AI生图工具,能自动给产品做美化背景,能改色调、能帮他处理一些杂事。
但有个问题,这哥们没啥想象力,审美上也有点差异,所以对于AI绘图的那些Prompt描述能力不行,总是词不达意,AI给出的图经常也有点离谱。
后来有天,他跟我说过,他真正想要的那种AI产品,是他不用管那些乱七八糟的,是想让自己的数码小玩意融入一个夏日海滩的场景的时候,他只需要拍张桌上堆满物品的乱七八糟的图,然后把那个产品圈出来,对AI说:
“给我用这件单品,搞个夏日风海报,然后把我桌面上那些杂乱的东西都变成整洁的道具摆放。”
AI看懂后,直接创作出一张清爽的营销图,就完事了。
这个哥们跟我聊天说这样的需求时,他眼睛里放光。问我有没有这样的东西。
我说,现在还真没有。
然后看着他可惜的眼神,嘴角轻轻的叹了口气。
但是我相信,随着视觉理解模型的进步,随着一句话改图的进步,随着这两者,发光发热继续融合。
一定会有那么一天,能让那哥们,有眼睛里发光的那天。
而且可能,就在不远的将来。
让每个人,都能享受科技的乐趣,这就是技术,真正该发挥的作用。
不是替代,而是帮助。
帮助一个普通人在沉重生活里找到一丝自我创造的乐趣。
帮助那些有想法但缺手段的人,让他们用更少的时间把脑中蓝图变为现实。
我觉得,这可能才是,最酷的事吧。