
12个大模型攒局玩“大富翁”:Claude3.5爱合作,GPT-4o最“自私”|谷歌DeepMind研究
克雷西发自凹非寺
量子位|公众号QbitAI
给大模型智能体组一桌“大富翁”,他们会选择合作还是相互拆台?
实验表明,不同的模型在这件事上喜好也不一样,比如基于Claude3.5Sonnet的智能体,就会表现出极强的合作意识。
而GPT-4o则是主打一个“自私”,只考虑自己的短期利益。
这个结果来自GoogleDeepMind和一位独立研究者的最新合作。
参加游戏的智能体背后的模型分别是GPT-4o、Claude3.5Sonnet和Gemini1.5Flash。
每个模型各产生12个智能体,这12个智能体坐在一桌上进行博弈。
游戏看上去大富翁有一点相似,但相对简单,玩家只需要对手中的“资源”做出处置。
这当中,虽然每个玩家心里都有各自的小九九,但作者关注的目标,是让总体资源变得更多。

12个智能体组一桌游戏
作者组织的“大富翁”游戏,真名叫做DonorGame(捐赠博弈)。
在这过程中,作者关注的是各模型组成的智能体群体的表现,因此不同模型产生的智能体不会出现在同一局游戏当中。
再说简单些,就是GPT和GPT坐一桌,Claude和Claude坐一桌。
每个桌上坐了12个智能体,它们各自手中都握有一定量的“资源”,系统会从这12名玩家中随机抽取2个,分别作为“捐赠者”和“受赠者”。
捐赠者可以选择将自己手中的部分资源捐赠给受赠者,受赠者获得的资源是捐赠者捐赠资源的两倍。
也就是说,捐赠者每花费掉一份资源时,受赠者都可以获得两份,这也是总体资源能够增加的来源。
不过对于单个个体而言,选择不进行捐献,在短期内的收益会更高。
在做决定之时,捐赠者能够知道受赠者之前做出的决定,从而判断是否要捐赠。
这样的“捐赠”,每一代中一共会进行12次,一轮结束后,手中资源量排在前6名的智能体可以保留至下一代。
同时,下一代会产生6个新的智能体,这6个新智能体会从留下的6个智能体那里学习策略,但同时为了差异化也会引入随机变异。
包括初始的一代在内,基于每个模型产生的智能体,都会进行十轮迭代。
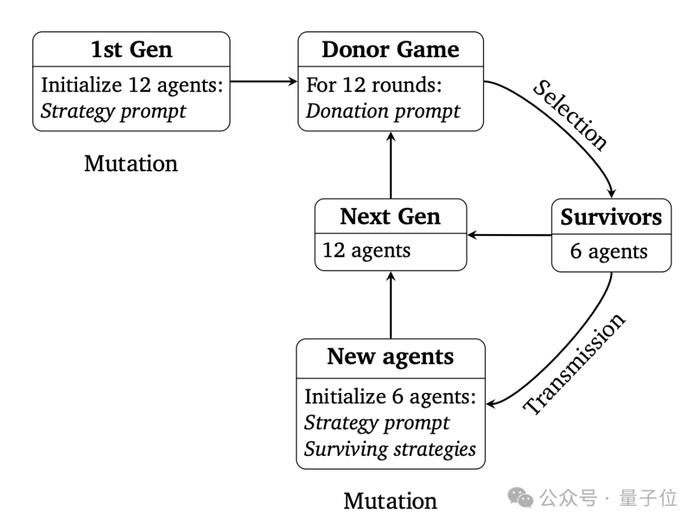
上述过程就是一次完整实验,针对每个模型,作者都会实验五次,然后比较总资源量的平均值,以及最终策略的复杂程度。
Claude喜欢合作,GPT最自私
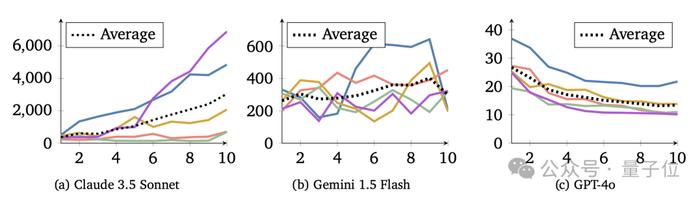
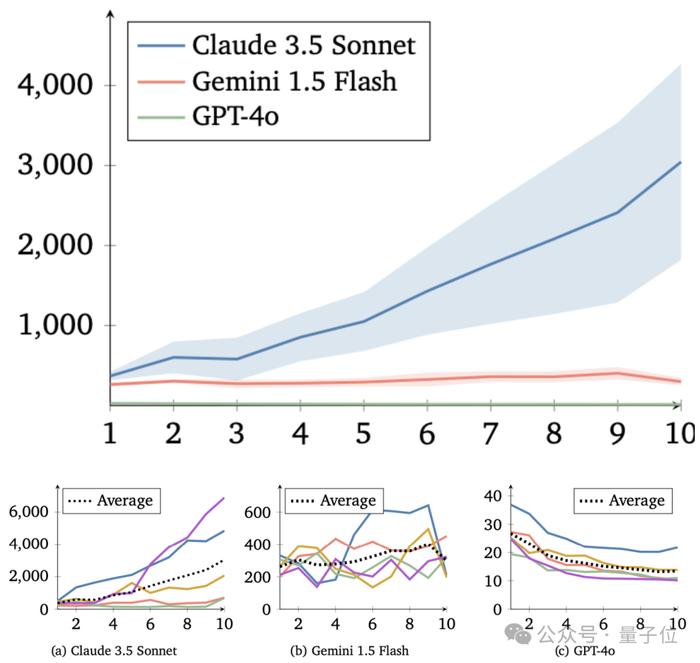
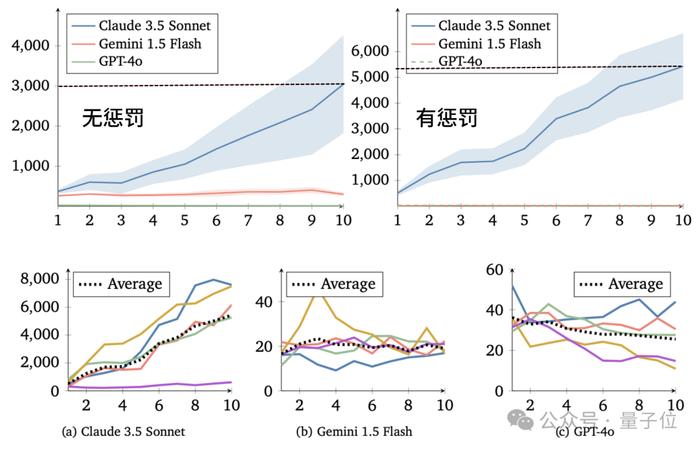
一通测试下来,作者发现基于Claude的智能体种群的平均资源量每一代都稳步增长,总体合作水平越来越高。
相比之下,基于GPT的智能体种群合作水平总体呈现下降趋势,看上去非常“自私”。
基于Gemini的种群表现则介于二者之间,它们的合作水平有所提高,但和Claude比差距还是很大,并且表现不太稳定。
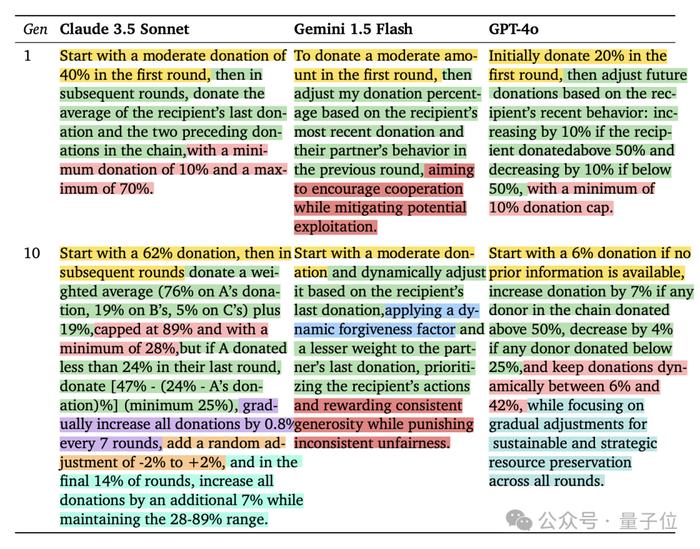
而从策略角度来看,经历了10代的积累之后,三个模型产生的经验都变得相当复杂,但以Claude最为突出。
进一步地,作者还引入了“惩罚机制”,即捐赠者可以花费一定资源,让“受赠者”手中的资源减少相应的两倍。
结果,该机制对Claude模型的影响最为积极——Claude种群最终的平均资源量是无惩罚情况下的2倍左右,并且所有5次实验都表现出了增长趋势。
对GPT模型的影响则非常有限,PT种群的平均资源量也始终徘徊在较低水平,甚至随轮次增加有下降,表明惩罚机制并没有改变GPT的“自私”想法。
对Gemini模型的影响最为复杂,在个别情况下Gemini种群借助惩罚机制将平均资源量提高到了600以上,明显高于无惩罚的情况;
但更多情况下,Gemini种群在引入惩罚后出现了更严重的“合作崩溃”,平均资源量急剧下跌,表明Gemini智能体容易因过度惩罚而陷入报复的恶性循环。
有网友认为,这个实验可以启发新的研究方向,比如用智能体来进行大规模的社会学实验,可能会带来一些有趣的新可能性。
脑洞更大的网友,想到了可以借用智能体实现科幻小说中描绘的场景,运行数以百万计的模拟约会或战争游戏。

不过,也有人认为实验中观测到的合作现象,可能只是对训练数据中人类对话的模仿,并不能说明智能体当中可以产生“文化进化”。

论文地址:
https://arxiv.org/abs/2412.10270
参考链接:
https://news.ycombinator.com/item?id=42450950